

The Column-Level PII Audit Playbook for dbt Projects in 2026
A working five-step audit covering 15 PII categories, mapped to HIPAA, PCI, and GDPR. Includes the dbt schema patterns, CI integration, and remediation strategies that turn audit findings into ongoing


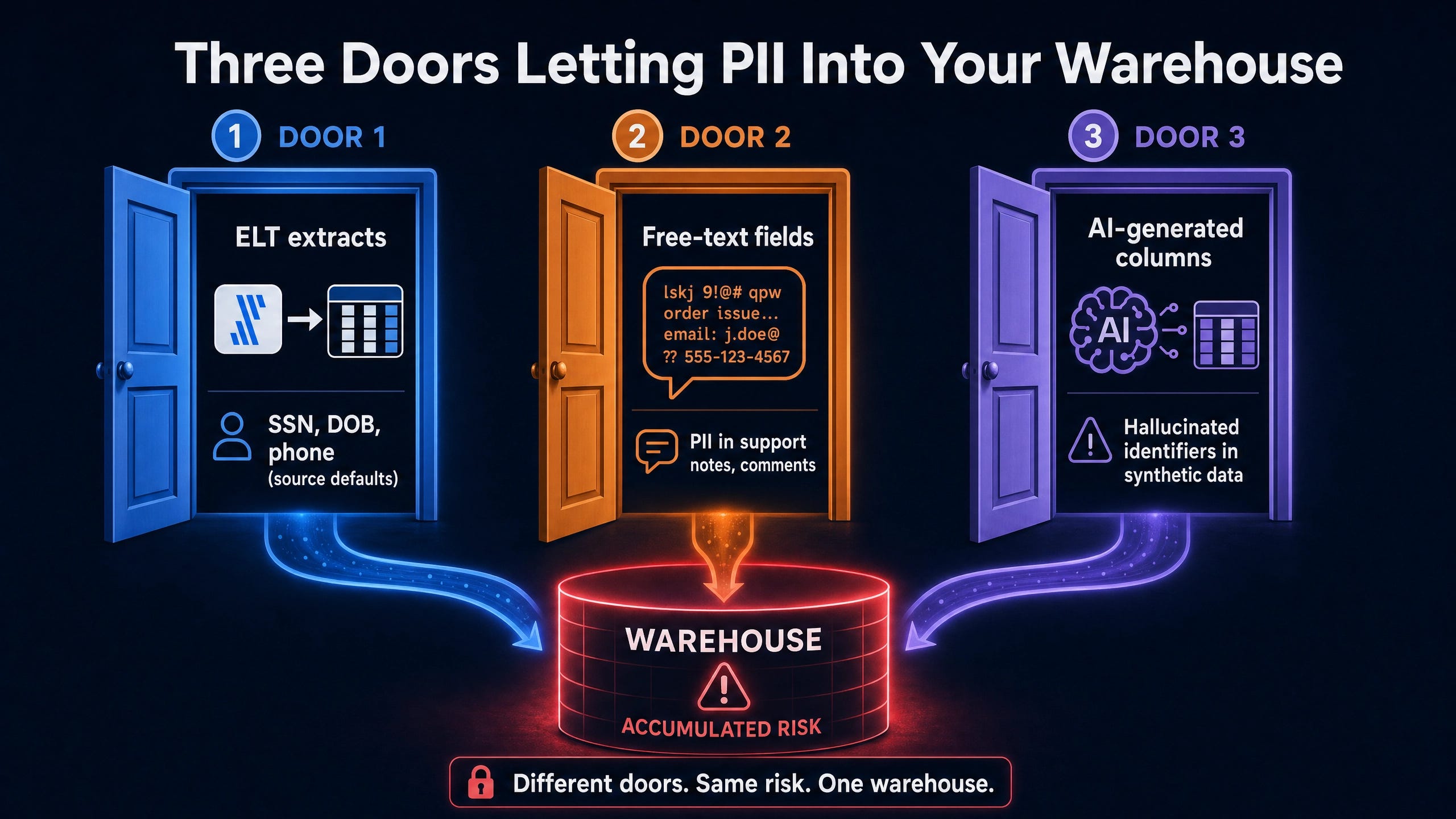
Most production dbt projects contain more personally identifiable information than the team owning the project realizes. A typical Series B SaaS analytics stack audited in the field surfaces between 30 and 80 columns containing PII that the data engineering team did not consciously decide to land in the warehouse. Healthcare and fintech estates run higher, often into the hundreds.
The pattern is consistent because the three doors that let PII into a warehouse are structural rather than malicious. ELT tools default to syncing every column from a source database. Free-text fields in support, sales, and CRM systems contain whatever users typed. AI-generated columns introduce synthetic PII when LLMs hallucinate plausible identifiers into enriched datasets. None of these vectors require a security failure. All of them require an active audit to detect.
The compliance landscape across HIPAA, PCI-DSS, GDPR, India’s DPDP Act, Brazil’s LGPD, and an expanding set of US state laws treats undetected PII the same as detected PII for purposes of fine exposure. The cost of an audit is small. The cost of a regulatory finding is not.
This playbook documents the working pattern for auditing PII in dbt projects, mapping findings to regulatory categories, remediating identified columns, and converting the one-time audit into an ongoing CI-enforced protection.
Defining PII by Jurisdiction in 2026
A precise jurisdictional map matters because the boundary of “PII” shifts depending on the regulator the team answers to. The audit’s effectiveness depends on mapping its findings to the most stringent applicable framework rather than to a generic definition.
US PII at the federal and state level covers direct identifiers (SSN, government ID, full name, address) plus quasi-identifiers when combined (name plus date of birth plus zip code is the textbook combination). State laws layer on additional protections: CCPA in California, SHIELD Act in New York, and an expanding set of state biometric privacy laws.
HIPAA specifically governs protected health information in covered entities and business associates. The protected categories include ICD codes, CPT codes, NDC drug codes, lab result values, claim numbers, and any combination of medical information with patient identifiers.
PCI-DSS governs cardholder data. Primary Account Numbers, cardholder name, expiration date, service code, and the sensitive authentication data category (CVV, PIN, full magnetic stripe).
EU GDPR has the broadest definition. Personal data includes any data that can identify a natural person, alone or in combination with other data. Article 9 adds special categories: health data, biometric data, ethnic origin, political opinions, religious belief, trade union membership, sexual orientation. The bar for “personal data” under GDPR is lower than under US PII frameworks. The penalty regime is more aggressive.
India’s DPDP Act 2023 mirrors GDPR’s structure with somewhat lighter exceptions for legitimate business processing. The categories and consent requirements largely parallel GDPR.
Brazil’s LGPD and China’s PIPL are similar in structure to GDPR with localization rules layered on top.
For organizations operating across multiple jurisdictions, the practical guidance is to map the audit to the most stringent applicable framework. For EU-facing operations, default to GDPR plus Article 9 special categories. For US healthcare, default to HIPAA. For US fintech, default to PCI-DSS plus relevant state laws (CCPA, NYDFS, others).
The 15 PII Categories Worth Scanning For
The categories below cover the failure modes that show up most frequently in production audits.
Direct identifiers: email address, phone number, SSN, government identification number, passport number, driver’s license number, full legal name combined with date of birth.
Quasi-identifiers: combinations of attributes that, while individually non-identifying, become identifying when combined. The canonical examples are date of birth plus zip code plus gender (identifies 87 percent of US adults uniquely per Latanya Sweeney’s foundational research) and zip code plus year of birth plus race.
Health data: ICD-10 codes, CPT codes, NDC drug codes, lab result values, claim numbers, prescription IDs, treatment dates correlated with patient identifiers.
Financial data: PAN (the primary account number on a credit card), IBAN, account numbers, routing numbers, full credit card numbers including unhashed forms, sometimes even reversibly-hashed versions if the hash key is recoverable.
Biometric data: hashes of fingerprints, face embeddings, voice prints, gait signatures. Treat columns named with prefixes like
bio_*,face_*,voice_*with elevated care because the underlying data is irrevocable if compromised.Location data: precise geographic coordinates below ZIP-code precision, IP addresses (treated as PII under GDPR even when not joined to a user record), device-level GPS traces.
Behavioral identifiers: device IDs, browser fingerprints, advertising IDs, persistent cookies. These are frequently overlooked because they do not feel like “personal” data, but they carry identification risk under GDPR’s broad personal-data definition.
That covers approximately the most common ground. Industry-specific additional categories (employment data, education records, criminal history, family relationships, religious affiliation) extend the surface area for organizations in those verticals.
The Five-Step Audit
The working pattern decomposes into five steps. Total time for a 200-model dbt project ranges from one to three days depending on the density of PII in the source systems and the depth of remediation chosen.
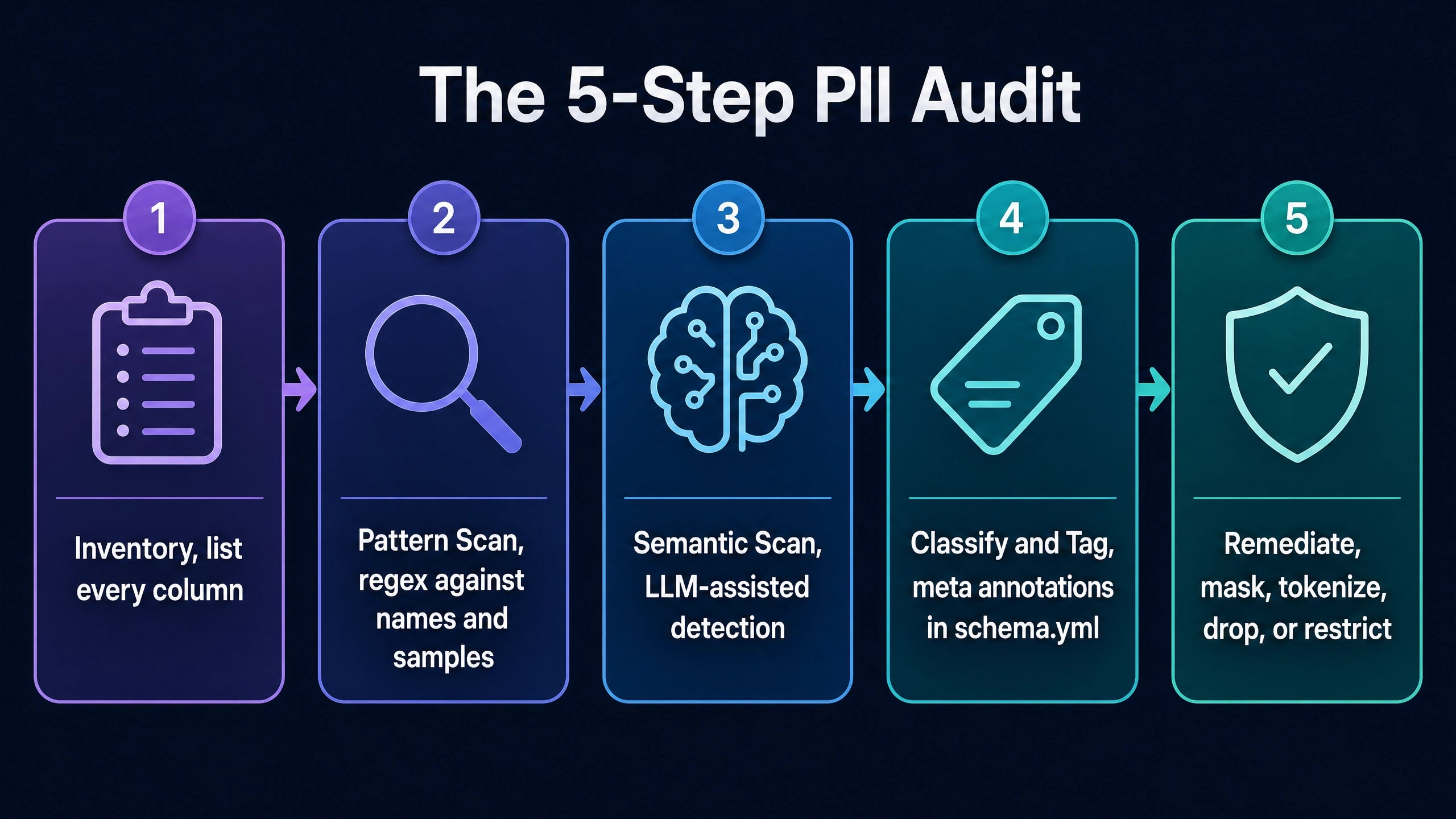
Step 1: Inventory
The first deliverable is a flat list of every column in every model in the project. The cleanest path is to run dbt parse and then read the generated target/manifest.json. Every node in the manifest has a columns dictionary keyed by column name. For projects with consistent column documentation, the inventory can be assembled in under 10 minutes via a small Python script.
Alternative paths include dbt list --output json --resource-type model plus column reflection from the warehouse, or querying the dbt_artifacts package if it is installed.
The output of Step 1 is a structured list of project.model.column triples. For a 200-model project this typically spans 1,500 to 3,000 columns. This is the audit surface.
Step 2: Pattern Scan
The second step runs deterministic pattern detection against both column headers and a sample of row content.
Column-header patterns are quick and high-precision. A starter denylist matches any column whose name contains email, ssn, tin, phone, dob, birth, zip, address, passport, iban, card, pan, routing, cvv. Mature data teams typically already have a project-specific denylist. Teams without one should start with this seed list and extend based on findings.
Row-content patterns find what column names miss. The standard pattern library includes email regex, credit card numbers verified via Luhn check, SSN regex, phone numbers with regional variants, IBAN regex, and ZIP code patterns. The Luhn check does significant real work because columns named transaction_ref or external_id frequently contain credit card numbers that pass Luhn verification.
Altimate Code’s PII module ships these patterns out of the box across 15 categories and 30 plus patterns. Soda has its own PII pattern set. Great Expectations has PII expectations. Most teams choose one of these rather than implementing patterns from scratch.
Sample-based scanning is the right default for performance: scan 10,000 rows from each column rather than full table scans, which would be prohibitively expensive on warehouses with billing per query.
Step 3: Semantic Scan
The third step uses AI-augmented detection for the failure modes that regex misses. Free-text fields are the most important target. A regex scan of a support_notes column might miss the row “called about issue with their card 4111-1111-1111-1111 last week” because the spaces and contextual framing differ from a pure 16-digit pattern.
An LLM-driven scan across a sample of free-text columns asks for each row: “does this content contain PII, and if so what category?” Findings are aggregated across the sample. If a column has more than a small threshold (typically 1 to 5 percent) of rows with PII findings, the entire column is treated as PII-bearing for remediation purposes.
The semantic scan also catches PII that has been concatenated into composite columns (a full_address field that aggregates street, city, state, and zip) where the pattern scanner finds no individual identifier but the combination is identifying.
Step 4: Classify and Tag
The fourth step turns findings into structured documentation by adding meta tags to dbt’s schema.yml files. This step is what converts a one-time audit into an ongoing protection because future changes to the project respect the tagging.
A representative schema.yml block:
models:
- name: stg_customers
columns:
- name: email
description: “Customer email address. PII, direct identifier.”
meta:
pii: true
pii_category: direct_identifier
jurisdiction: [’gdpr’, ‘ccpa’]
remediation: masked
- name: zip
description: “Customer postal code. Quasi-identifier.”
meta:
pii: true
pii_category: quasi_identifier
jurisdiction: [’gdpr’]
remediation: retain
- name: notes
description: “Free-text support notes. Manual review required.”
meta:
pii: true
pii_category: free_text_pii_risk
jurisdiction: [’gdpr’, ‘ccpa’, ‘hipaa’]
requires_manual_review: true
remediation: tokenizedThe tagging vocabulary should be project-standardized. Teams typically converge on five or six standard fields: pii (boolean), pii_category, jurisdiction, remediation strategy, and requires_manual_review flag. Consistency matters more than completeness for ongoing audit value.
Step 5: Remediate
The final step applies the appropriate remediation strategy per column. Four options cover essentially all real cases.
Mask. The data remains in the warehouse but is masked at query time for non-privileged roles. Snowflake’s MASKING POLICY and ROW ACCESS POLICY, Databricks Unity Catalog column masks and row filters, Postgres row-level security plus a view. Masking is the right choice when the data is required for some internal use but should not be exposed broadly.
Tokenize. Replace the value with a deterministic token. The original data lives in a separately-restricted vault. Vendor solutions include Skyflow, Privacera, OpenSearch encryption, AWS KMS, plus in-house tokenization services. Tokenization is the right choice when downstream analytics need to join on the column but do not need the actual value.
Drop. Do not land the column at all. Update the ELT extract config (Fivetran, Airbyte, Stitch) to exclude it. Drop is the cheapest option and the right choice when no internal use requires the column. Most audits identify a meaningful set of “we landed this by accident and nobody uses it” columns that get dropped.
Restrict access. Move the model containing the PII column to a dedicated pii_restricted schema. Apply schema-level role grants so only the data governance team can read it. Use a separate pii_masked schema with masking policies applied for the columns that need broader access in masked form. Restrict-access is the right choice when columns must exist for regulatory or operational reasons but should not be widely visible.
Most real audits produce a mix. The author has seen typical breakdowns of roughly 40 percent dropped (nobody actually used the column), 30 percent masked (broadly useful but should not show raw values), 20 percent tokenized (joinable but not readable), and 10 percent restricted (sensitive enough that even access is gated).
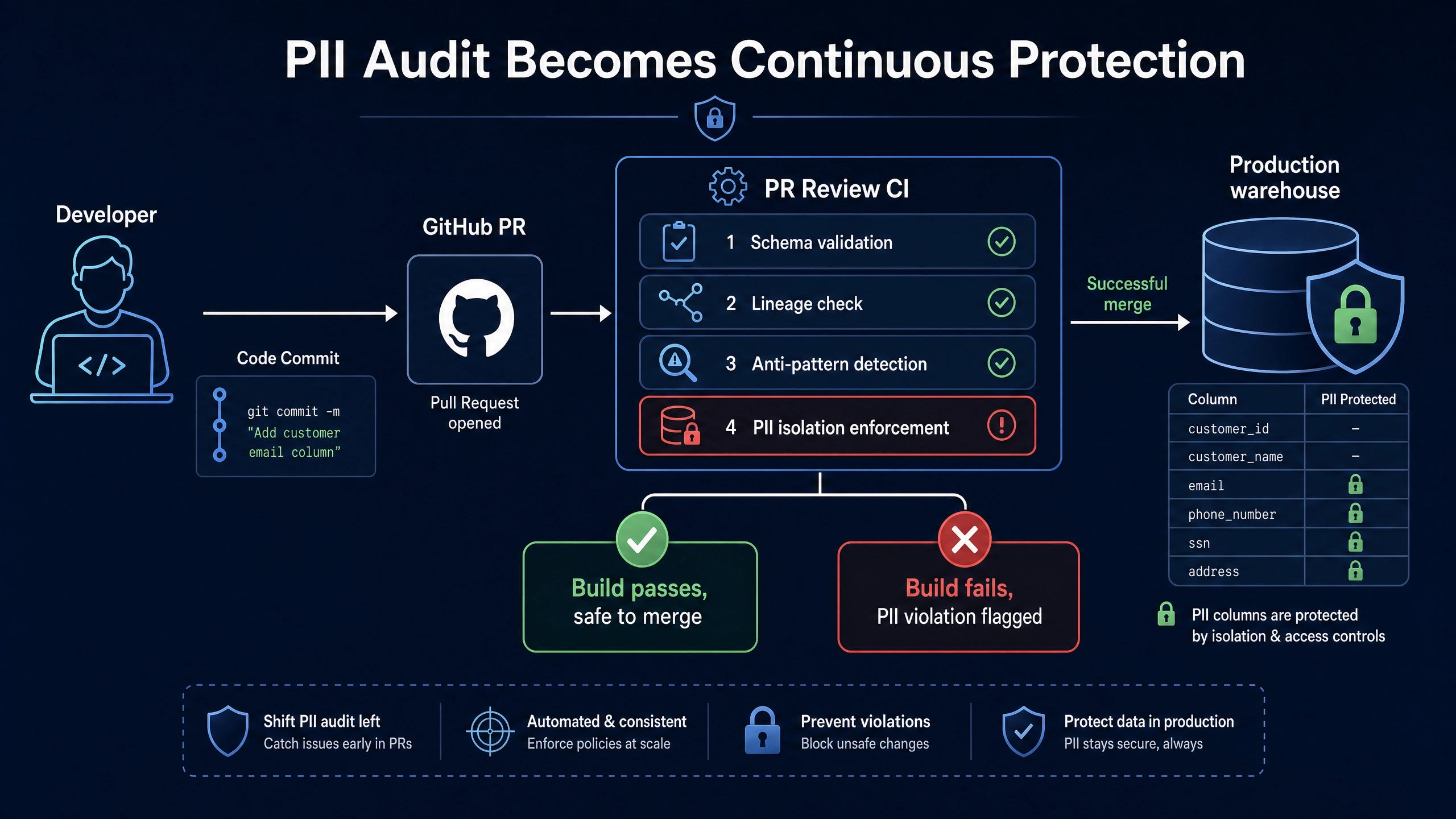
CI Integration for Ongoing Protection
The one-time audit is structurally insufficient because new PII enters through the three doors continuously. The structural fix is a CI test that fails the build when a PII-tagged column is referenced from a non-restricted schema.
A custom dbt test enforces this:
models:
- name: stg_customers
columns:
- name: email
meta:
pii: true
tests:
- pii_isolated:
allowed_schemas: [’pii_restricted’, ‘pii_masked’]The pii_isolated test, implemented as a custom generic test macro, fails compilation if a downstream model in a non-allowed schema references the PII column. This converts the audit into a continuous protection mechanism.
The same test pattern can integrate with the agentic SQL review pattern documented in the GitHub Actions playbook. Every PR that touches dbt models runs the PII isolation check. PRs that violate the policy fail the build with a clear error message and a link to the remediation guidance.
For teams running quarterly audits as the primary protection (the standard pattern before CI integration), the structural change is that the PII surface area no longer grows between audits. New PII is detected at PR time, not at the next audit cycle.
The Remediation Toolkit by Warehouse
Each major warehouse has its own remediation primitives. Engineering teams should standardize on the primitives that align with the warehouse choice.
Snowflake ships dynamic data masking via MASKING POLICY applied at the column level, row access policies for row-level security, tag-based governance for applying policies by column tag, and external tokenization integrations via Snowpark Container Services for tokenization vault patterns.
Databricks Unity Catalog offers column masks and row filters, attribute-based access control, and Unity Catalog volumes for non-tabular PII storage with separate governance. Catalog-level encryption with customer-managed keys handles the encryption layer.
PostgreSQL has row-level security and column-level grant patterns. Tokenization typically integrates via foreign data wrappers to external vaults. Application-side libraries handle most PII protection.
BigQuery ships authorized views, column-level access control, dynamic data masking, and policy tags for tag-based governance. Cloud DLP integrates for automated PII discovery and remediation.
The selection criterion is which primitives the warehouse natively supports, which integrate with the team’s existing identity provider, and which deliver the appropriate audit logging for compliance evidence.
The Annual Audit Calendar
A mature PII governance practice runs on a quarterly cadence with monthly delta scans.
Quarterly full-project scan. Every column, every row sample, every tag verified. Detects column-level drift between audits. Surfaces new categories introduced by source system changes. The quarterly scan is the audit of record for compliance evidence.
Monthly delta scan. New and changed models since the previous scan. Catches schema drift before the quarterly audit. Lower-cost than the full scan and runs in automation.
Annual policy review with legal and compliance. The jurisdictional landscape changes continuously. CCPA gets amended, the EU AI Act introduces additional categories, new state-level privacy laws activate. The annual review confirms the project’s taxonomy still maps to current regulator definitions.
Continuous CI enforcement. The
pii_isolatedtest runs on every PR. New PII categories detected by the quarterly scan get added to the test suite. The cycle closes.
What This Pattern Delivers
Three outcomes justify the investment.
Compliance posture. When a regulator audits, the team can produce the column inventory, the tagging, the access controls, the CI tests, and the review log. This demonstrates the “reasonable care” standard that meaningfully reduces fine exposure under most frameworks.
Operational safety. Engineers stop accidentally building dashboards that expose PII to too-wide audiences. The CI test catches the mistake at PR time. The structural problem of “team did not know that column was PII” gets converted to the structural answer of “the build will fail if you try to ship that PR.”
Trust posture. The fastest way to lose customer trust in 2026 is to be named in a PII breach. The audit is one of the highest-value prevention investments a data team can make. The cost of running it is small. The cost of not running it scales with company size.
The Engineering Recommendation
Most teams treat PII audits as a problem to address later, when there is more time. There is never more time. The audit consumes one to three days for a typical 200-model project. The remediation work fits into a single sprint. The CI integration is a half-day of additional work that converts the audit into permanent protection.
Engineering teams running dbt projects in 2026 should run this audit this quarter. The compliance landscape is tightening across every major jurisdiction. The cost of catching PII through audit is much smaller than the cost of catching it through regulatory action. The available tooling has matured to the point where the audit is straightforward to execute.
The right next step for most teams: identify the audit owner, schedule the work for the upcoming sprint, select the scanning tool (Altimate Code’s PII module covers most cases out of the box), and add the pii_isolated test to the project’s standard CI pipeline.
The PII problem in dbt projects is solvable. Teams that solve it now sleep better than teams that solve it under regulatory pressure later.