

The Harness, Not the Model: Why Agent Quality in 2026 Is Mostly Tooling
Foundation model gains are slowing. Deterministic tooling around the LLM is compounding. The next 18 months of AI productivity lives in the harness layer.


The dominant discourse on AI tooling in 2026 still treats foundation models as the central variable. Each new release of Claude, GPT, or Gemini triggers a wave of “this changes everything” commentary, complete with performance comparisons, capability charts, and revised buyer recommendations. The pattern is familiar. The pattern is also wrong for the domains where AI is actually being deployed for production work.
The competitive variable for AI in 2026 has moved from the model layer to the deterministic tooling layer surrounding it. Foundation model improvements are compounding at roughly 5 to 10 percentage points per major release on canonical benchmarks. Deterministic harness improvements are compounding at 25 to 35 percentage points on the same benchmarks. Same benchmark, same task, same dataset. The model is the constant. The harness is the variable.
Engineering leaders, platform teams, and AI buyers who optimize their evaluation around model selection are optimizing the smaller axis of improvement. The larger axis is the tooling layer.
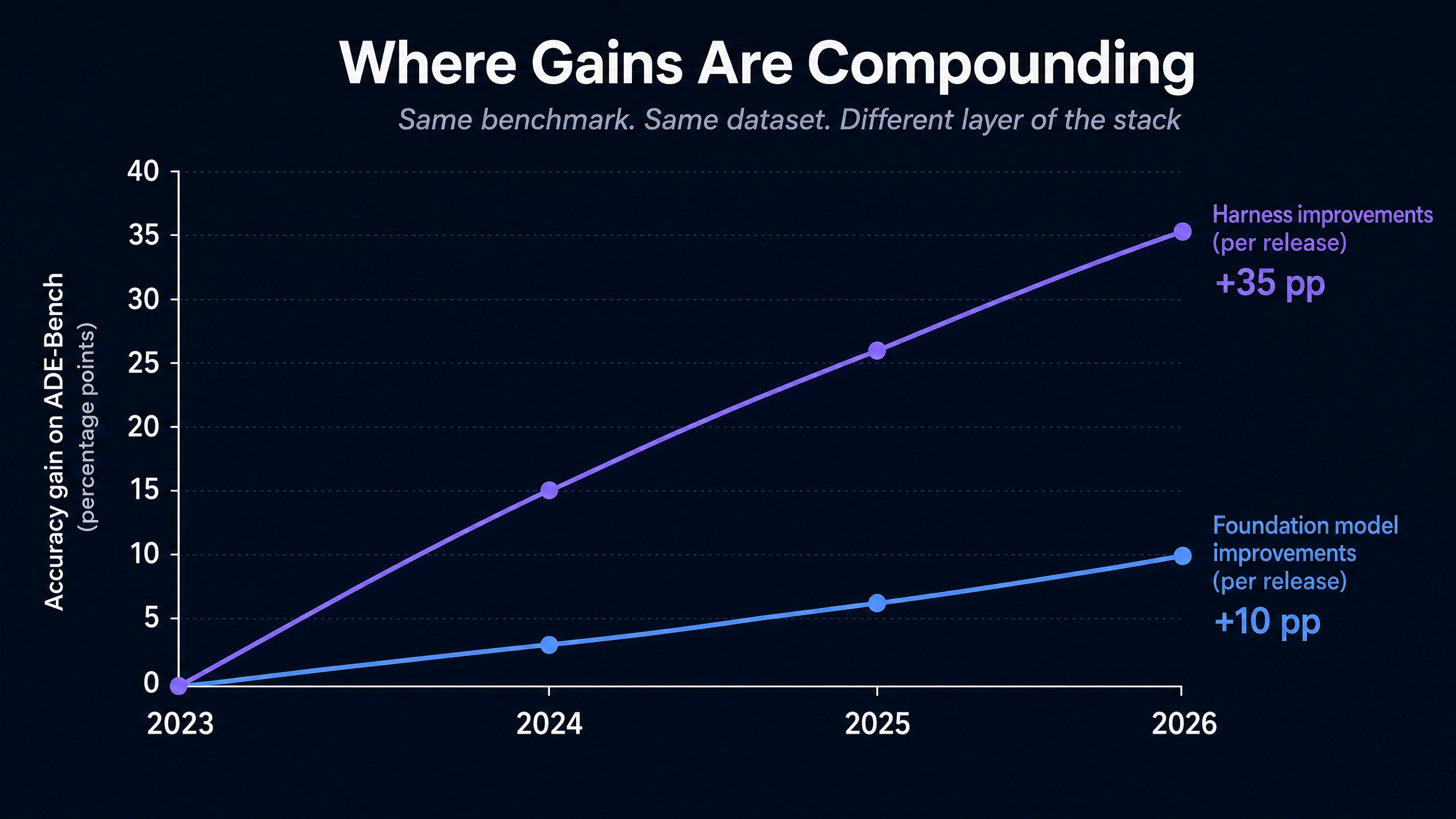
The Defining Benchmark Data Point
Altimate AI’s published benchmark from March 2026 is the clearest available illustration. Altimate Code, an agentic harness built around standard LLMs, reports 74.4 percent on ADE-Bench, dbt Labs’ analytics-engineering benchmark. The nearest specialized competitor reports approximately 65 percent. General-purpose agents (Claude Code, Cursor agent mode, others on the same task surface) report approximately 40 percent.
The 35-point gap between general agents and Altimate Code is not produced by a better LLM. Altimate Code runs on the same Claude, GPT, Gemini, and other foundation models that competitors and general agents use. The gap is produced by the deterministic tooling layer wrapping the LLM: schema introspection, column-level lineage extraction from a Rust core, SQL equivalence checking, dialect translation rules, anti-pattern detection, and roughly 100 additional specialized tools the agent can invoke.
On DAB-Bench, the harder multi-database benchmark, Altimate Code reports 60.4 percent against a baseline of 30 to 40 percent for general agents. The absolute number is lower because cross-warehouse heterogeneity is intrinsically harder. The relative gap remains substantial.
These numbers are reproducible in principle and reported by the vendor in published material. Independent verification of the exact numbers requires running the benchmark suites against alternative agent configurations, which several research teams are pursuing. The relative ordering (specialized harness > specialized model + thin harness > general agent) is consistent with what data engineering teams report in field deployments.
Defining the Harness Layer Precisely
The word “harness” has become overloaded in 2026 marketing materials. A precise definition matters.
A harness is the layer of deterministic tooling and orchestration logic between the user prompt and the LLM’s final output that provides the LLM with verifiable information about the task and validates the LLM’s proposed actions before they execute. The LLM provides probabilistic reasoning. The harness provides deterministic verification. The combination outperforms either alone.
For SQL work specifically, the deterministic tools that matter are:
Schema introspection. The harness queries the warehouse’s information schema directly and returns ground-truth column names, types, and constraints. The LLM never has to guess whether
customer_idis varchar or integer.Column-level lineage. The harness parses the SQL AST of every model and resolves which output column derives from which input columns. The LLM gets a precise answer to “what depends on this column?” without searching files.
AST manipulation. Parse SQL into an abstract syntax tree, walk the tree, rewrite specific nodes, regenerate clean SQL. The harness offers rewrite primitives that the LLM can invoke without producing malformed output.
Dialect translation with rule-based correctness. Snowflake’s
QUALIFY, BigQuery’sSTRUCTsyntax, ClickHouse’sargMaxall have known translations. The harness encodes those rules deterministically rather than asking the LLM to remember them.Equivalence checking. Given two candidate query rewrites, the harness can run them against sample data and verify identical outputs row-for-row via hash diffing. The LLM proposes the rewrite. The harness verifies correctness.
Anti-pattern detection. Deterministic rules flag common failure modes (cartesian joins, unbounded SELECT *, missing predicates on large tables) before the SQL reaches the warehouse.
PII scanning. Pattern-based and semantic scanning of column names and row samples identifies sensitive data that should not flow through certain transformations.
None of these are LLM capabilities. Each is a deterministic function that runs in milliseconds and returns a correct answer by construction. The harness routes the LLM through these tools at the right moments. When the LLM is about to invent a column name, the harness intercepts and runs the schema lookup. When the LLM proposes a rewrite, the harness verifies equivalence before suggesting the rewrite to the user. When the LLM drafts a join, the harness checks the join keys are type-compatible.
The LLM produces strategy. The harness verifies correctness. The output is meaningfully better than what either layer produces alone.
Why This Pattern Compounds Faster Than Model Improvements
Consider what a model release accomplishes. A new Claude or GPT moves accuracy on a fixed benchmark from approximately 65 percent to 70 percent. That gain is real. It is also asymptotic. The remaining 30 percent gap is mostly composed of tasks where the LLM has the wrong information about the world, not where it has the wrong reasoning capacity.
A harness changes the information available to the LLM. That is a categorically different axis of improvement. Adding a new deterministic tool to the harness improves performance on every task that tool covers, without changing the model at all. The improvements compound: each tool added to the harness benefits every subsequent task that touches its domain.
The harness also learns about specific deployments in a way models cannot. A model only knows what it learned during training. The harness’s memory layer, project-scoped context, schema fingerprints, and session compactors capture facts about a specific team’s codebase, conventions, and history. Over time the harness’s effective intelligence on a given project increases. The model’s effective intelligence is fixed at training time.
For domains with verifiable ground truth (SQL, type systems, financial calculations, infrastructure state), the harness compounding effect is large. The right answer to most questions in these domains is a deterministic fact about the underlying system, not a stylistic preference. The harness can supply those facts. The LLM cannot, except by guessing.

Where the Pattern Generalizes Beyond SQL
SQL is the first domain where the harness thesis lands hard in 2026 because SQL has the cleanest combination of properties: well-defined ground truth, long history of catalogued failure modes, large existing investment in deterministic tooling (parsers, query planners, type checkers), and high economic cost when AI gets it wrong silently.
The same pattern is observable in adjacent verticals:
Type systems in TypeScript and Rust. The compiler is the harness. LLMs integrated with tsc or rust-analyzer ship fewer type errors than LLMs operating on source text alone. Cursor’s recent agent mode improvements correlate strongly with deeper TypeScript language server integration.
Infrastructure as code. terraform plan is deterministic. Agents that invoke terraform plan before proposing infrastructure changes produce safer outputs. Pulumi and OpenTofu integrations follow the same pattern.
Financial modeling. Spreadsheet equations have ground truth. LLMs that can call a deterministic spreadsheet engine before suggesting changes produce fewer wrong numbers. Quant teams are increasingly building harnesses around financial DSLs like Q/Kdb+ and tinygrad-style numeric verifiers.
Healthcare claims. ICD-10 codes, CPT codes, NDC drug codes, billing rules, and formulary checks are all deterministic. LLMs wrapped with code-validator tools and formulary databases produce fewer compliance errors than LLMs trying to reason from training data alone.
Legal contract review. Clause structures are formally specifiable. Deterministic parsers that decompose contracts into their atomic obligations outperform LLMs that “understand” the contract holistically.
In every case the architectural insight is the same: probabilistic strategy on top, deterministic verification underneath. The vertical-specific value lives in the tools the harness can invoke.
The Honest Counterargument
Better models do close some portion of the gap. A foundation model that has memorized more SQL dialect quirks needs the dialect-translation tool less. A model with longer context can hold more of the schema at once. A model with stronger tool use is easier to wrap into a harness in the first place.
These trends are real and accelerating. They do not eliminate the need for the harness. They make a well-designed harness more valuable, because better tool use means the harness’s tools get invoked more reliably.
The arithmetic that matters is this: a 90-percent model with a strong harness outperforms a 95-percent model with no harness, on tasks that have ground truth and silent failure modes. The benchmark data supports this consistently. Engineering teams choosing AI tooling who optimize for the 95-percent model and ignore the harness layer ship worse production outcomes than teams who optimize for the harness.
Implications for Engineering Teams Building AI Tooling
For organizations building AI tooling internally or evaluating vendor offerings, the harness thesis translates into five practical principles.
Build deterministic tools first. Before investing in prompt engineering or model fine-tuning, build the deterministic verification layer. Schema introspection, AST manipulation, type checkers, validators, lineage extractors. These are the cheap part of the system and they compound across every subsequent task.
Treat the LLM as a strategy layer, not a knowledge layer. The LLM should plan, call tools, and integrate results. The LLM should not be the source of truth about the codebase, the data, or the business rules. Anything that lives in the LLM’s training data is approximate. Anything that lives in the harness’s tools is exact.
Benchmark the harness, not the model. ADE-Bench, SWE-Bench, or an internally-developed benchmark. Test the same harness against multiple LLMs. The harness should improve the performance of every model it wraps. A harness that only works with one specific model is too thin to be the strategic moat.
Make tools composable through open protocols. Each deterministic tool should be callable from any LLM via Model Context Protocol or function calling. Avoid embedding the LLM choice directly into the tool. This preserves portability as the foundation model market continues to commoditize.
Persist learning across sessions. Memory layers, session compactors, project-scoped schema fingerprints. The harness should know more about the deployment on day 30 than on day 1. Without persistence the harness re-learns the same facts repeatedly, which wastes compute and reduces output quality.
Implications for AI Buyers
For organizations evaluating AI tooling vendors in 2026, the right filter questions have shifted away from model selection toward harness quality.
Productive evaluation questions to ask vendors include:
What deterministic tools does this system ship with, and can the customer enumerate them?
How does the system handle uncertainty in the LLM’s output?
What does the system do when the LLM proposes something demonstrably wrong?
Can the customer bring their own LLM, or is the system locked to a specific model provider?
What is the published benchmark performance, and on what tasks?
How does the system persist learning across sessions, and what is the data residency model for that persistence?
Most “AI for data” or “AI for code” products in the market today fail one or more of these questions. The ones that pass are the products engineering leaders should be evaluating seriously.
The Conceding Note
The model layer continues to matter. A worse model with a strong harness still loses to a stronger model with the same harness. The model is a multiplier on the harness’s effectiveness.
The strategic point is not “models do not matter.” The strategic point is that marginal model improvements have slowed while marginal harness improvements have barely started, and the bet on where to invest the next dollar of engineering or procurement budget should reflect this asymmetry.
For organizations betting time and money on AI tooling, the higher-yield bet through 2027 is the harness layer, not the model layer.
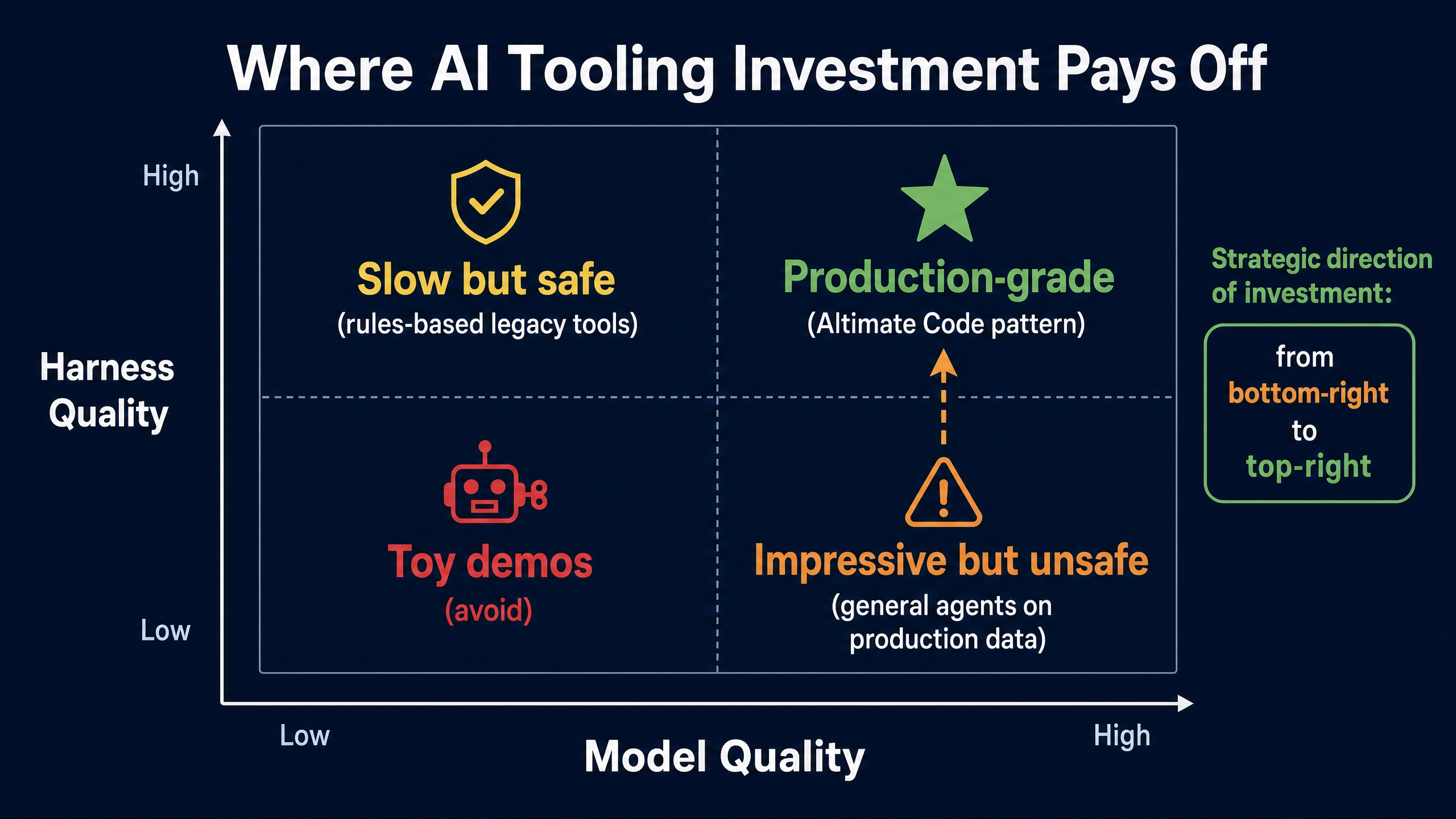
The Strategic Bottom Line
The competitive frame for AI tooling through 2027 will reflect the asymmetry between slowing model improvements and accelerating harness improvements. Generalist agents will continue to dominate the broad surface of software engineering where the cost of approximate output is low. Domain-specialized harnesses will dominate verticals where ground truth exists and silent errors are expensive.
Data engineering is the canonical first vertical because SQL meets every condition: ground truth in the warehouse, well-catalogued failure modes, mature deterministic tooling, and high cost of silent errors. Other verticals (infrastructure, financial modeling, healthcare claims, legal review) will follow as their respective harnesses mature.
For engineering leaders allocating budget toward AI tooling in 2026, the strategic question to ask is not “which model should we use?” The strategic question is “where in the stack does our deterministic verification layer live?” Organizations that can answer that question precisely are positioned to capture the next 18 months of meaningful productivity gain. Organizations that cannot are buying marketing.
The next dollar of AI productivity is hiding in the harness layer. The benchmark evidence supports it. The architectural pattern generalizes. The competitive frame is shifting in favor of vendors who understand this. Engineering teams should be choosing tools accordingly.