

Practical AI Cost Reduction, Part 2: Context Optimization and Memory
Caching, compression, and RAG chunking strategies that eliminate token waste


In Part 1, we covered the model pricing spectrum and how to route work to the right tier. The takeaway was simple: stop sending every task to a frontier model. Use OpenRouter to route cheap tasks to DeepSeek and reserve Opus for what actually needs it.

But picking the right model is only half the equation. The other half is how much context you send with each request.
Context bloat is the silent budget killer of 2026. Context windows expanded to 10 million tokens, and developers got lazy. They started sending entire codebases, full conversation histories, and bloated system prompts with every single request. The model does not care about your 200-page PDF when it only needs three paragraphs to answer the question. You are paying for all 200 pages anyway.
This article covers the technical mechanisms that fix context waste: caching that cuts repeat costs by 90%, compression that trims inputs by 2–6x, and smarter retrieval that halves your token usage per query.
The Two Types of Caching That Save Real Money
The most impactful cost reduction technique in 2026 is also the simplest: stop re-processing tokens you have already processed. There are two distinct caching mechanisms, and they solve different problems.

Prompt Caching Works When Your Prefix Is Stable
Every time you send a request to an LLM, the model processes every token in your input from scratch — including the system prompt, the few-shot examples, and any static context that has not changed since the last call. Prompt caching eliminates this waste by storing the model’s internal key-value state for token prefixes it has already seen.
Anthropic’s implementation lets you manually mark cache breakpoints in your prompt. Any prefix before the breakpoint gets cached for a 5-minute TTL window. Subsequent requests that share the same prefix get a 90% discount on those cached tokens — the model skips the expensive prefill computation entirely and jumps straight to processing the new content.
DeepSeek handles this automatically. Their API detects when a new request shares a prefix with a recent one and caches it without any developer configuration. Input costs drop from $0.28 per million tokens to $0.028 per million — a 10x reduction on repeat prefixes.
The practical implication: if you have a system prompt longer than 1,000 tokens and you send it with every request, you are almost certainly overpaying. Structure your prompts so the static content appears at the start, and the dynamic content comes at the end. That way, the cache hits on every subsequent request.
In a 20-turn conversation where the 5,000-token system prompt gets re-processed every turn, prompt caching alone cuts the cost of those system tokens by 90%. Across thousands of daily conversations, that adds up to a significant line item.
Semantic Caching Bypasses the Model Entirely
Prompt caching saves money on tokens you send. Semantic caching saves money by not sending tokens at all.
The idea is simple: convert every incoming query into an embedding vector and check it against a local vector store (Redis, Pinecone, or similar). If a previous query with similarity above 0.95 exists, return the cached response directly. The LLM never sees the request.
This works brilliantly for support bots, FAQ systems, and any application where users ask the same questions in slightly different ways. “How do I reset my password?” and “I forgot my password, what do I do?” map to the same intent. A semantic cache catches both and returns the same pre-computed answer.
The savings are 100% on every cache hit — no model call means no token cost. For a support bot handling 10,000 queries a day where 60% of queries are repeat intents, that is 6,000 free responses per day.
Compressing Your Prompts Without Losing Meaning
Caching handles repeated content. But when every request is unique — dynamic multi-document analysis, fresh data ingestion, one-off research queries — there is nothing to cache. You need compression instead.
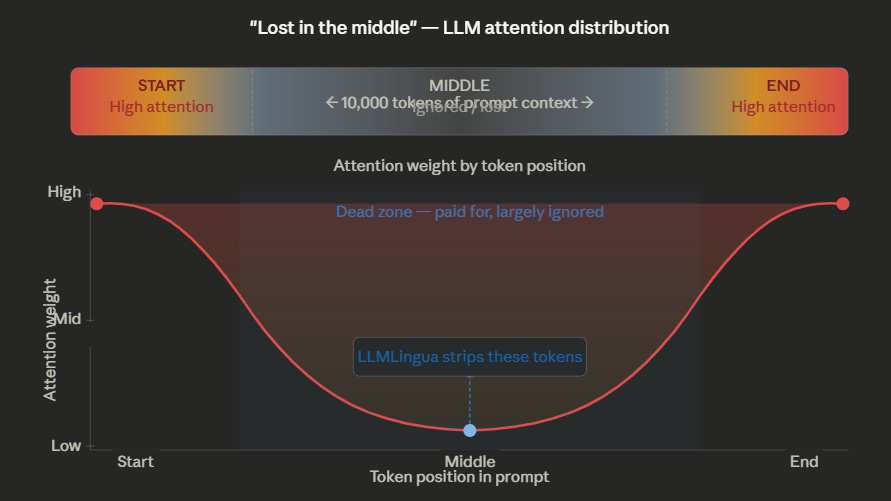
The research here is encouraging. A phenomenon called the “Lost in the Middle” effect (Liu et al., 2023) shows that LLMs often ignore information in the middle of long prompts. They attend most strongly to the beginning and end. This means a significant portion of your long prompts is dead weight — tokens the model processes and charges you for but effectively ignores.
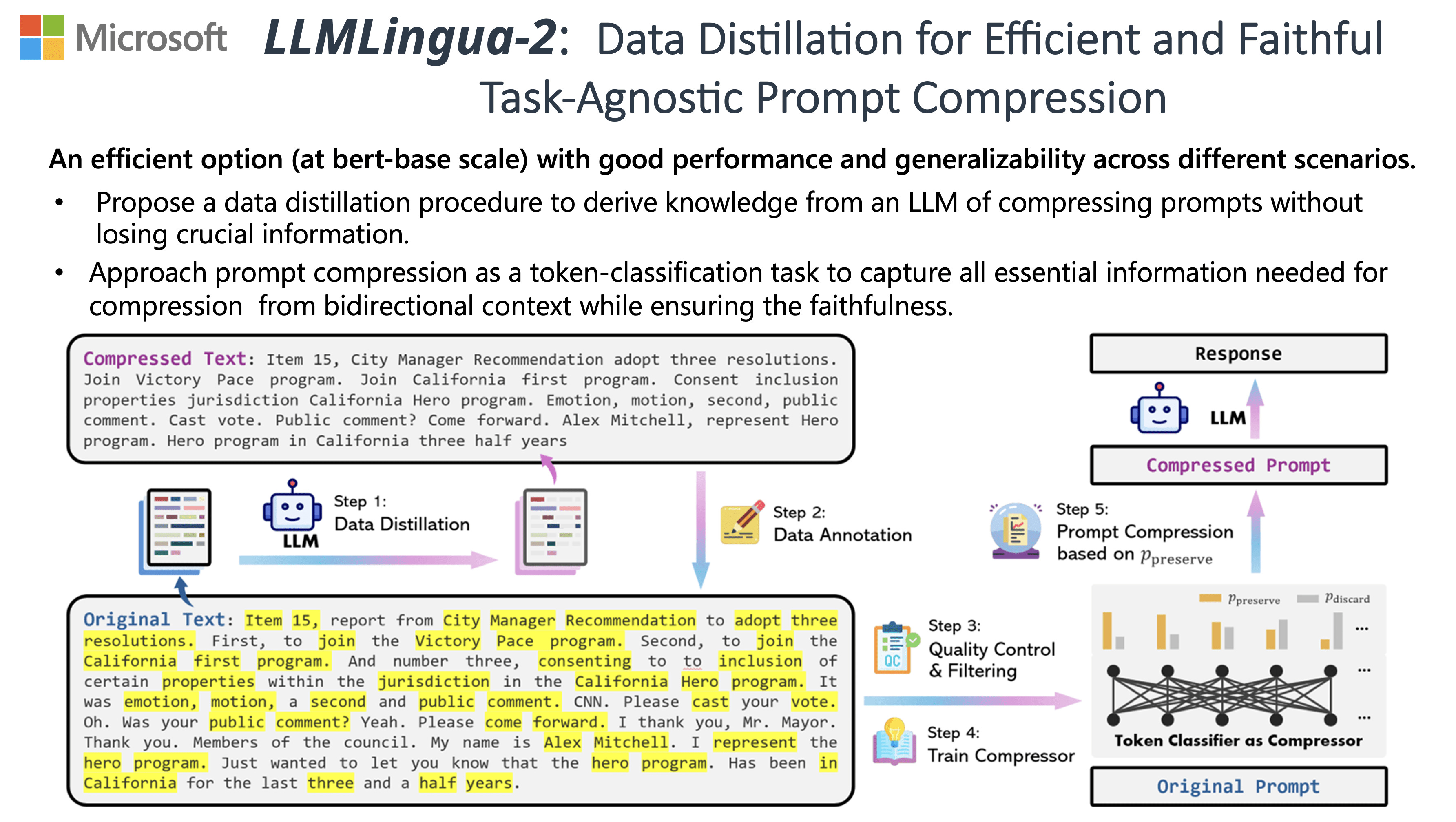
LLMLingua (Microsoft Research, ACL 2024) exploits this directly. It uses a small, fast model to calculate the perplexity of each token in a large prompt. Tokens with low information content — grammatical filler, redundant phrasing, boilerplate — get stripped out. The result is a compressed prompt that preserves the semantic meaning while dramatically reducing token count.
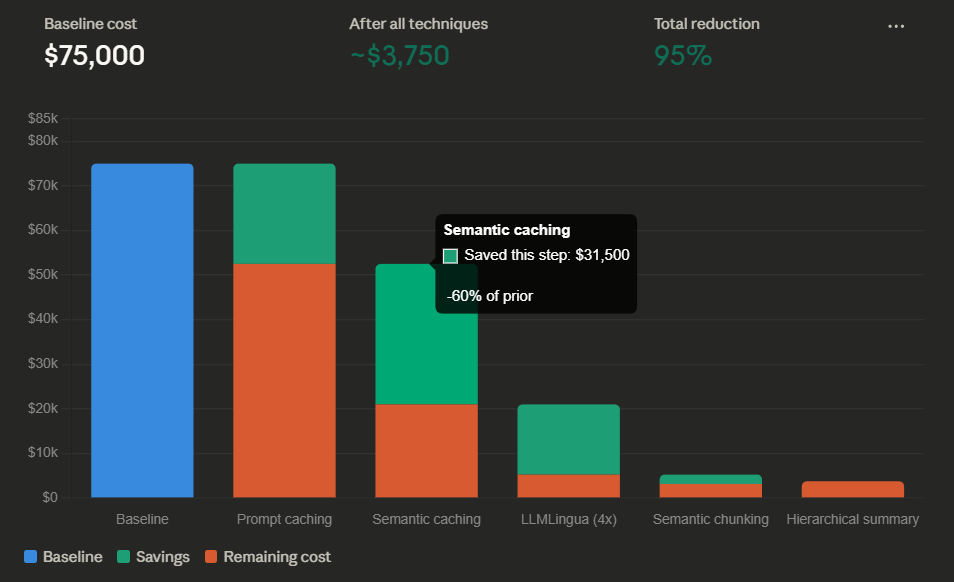
The published results show 2x to 6x compression ratios depending on the content type. On the NaturalQuestions benchmark, LLMLingua achieved a 21.4% performance boost with 4x fewer tokens — the model actually performed better with the compressed input because the signal-to-noise ratio improved. On the LooGLE long-context benchmark, it achieved 94% cost reduction while maintaining comparable accuracy.
For a concrete example: an enterprise sending 5 billion tokens of input per month through Claude Opus 4.1 ($15 per million input) faces a $75,000 monthly input bill. Applying LLMLingua at a conservative 4x compression ratio reduces that to roughly $18,750 — a $56,250 monthly saving. The compression model itself runs on a small local GPU and costs negligible compute compared to the saved API calls.
The key constraint is that compression works best on natural language prompts with redundant phrasing. Highly structured inputs like JSON schemas or code compress less effectively. Test your specific content to find the right compression ratio before deploying.
Building a Smarter RAG Pipeline with Semantic Chunking
In Retrieval-Augmented Generation (RAG), the most expensive decision happens before the model ever sees a token: how you chunk your documents.
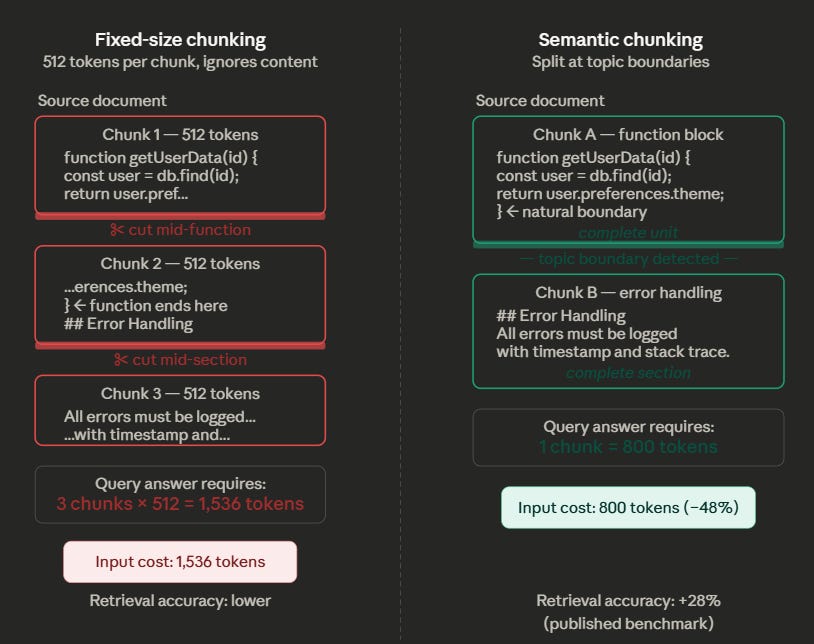
Traditional fixed-size chunking — splitting documents into 512-token blocks regardless of content — is the default in most RAG frameworks. It is also terrible for both cost and accuracy. A 512-token boundary does not care that it just split a function definition in half, or separated a conclusion from its supporting evidence. The retrieval system then has to pull three chunks to reconstruct what a single well-bounded chunk would have provided, tripling your input token cost.
Semantic chunking fixes this by using embedding similarity to detect natural topic boundaries. Instead of slicing at fixed intervals, it measures the cosine similarity between adjacent sentences. When the similarity drops below a threshold — indicating a topic shift — it creates a chunk boundary there.
The result: each chunk contains a coherent unit of meaning. Retrieval accuracy improves because the model gets complete, self-contained context rather than fragments. Published benchmarks show a 28% improvement in retrieval accuracy, and because you retrieve fewer, more relevant chunks per query, your input token cost per retrieval drops by roughly 50%.
A software company using RAG for their API documentation illustrates the difference well. With fixed-size chunking, a coding question triggers retrieval of three 512-token chunks (1,536 tokens) because the function definition got split across boundaries. With semantic chunking, the system identifies the function boundary and retrieves a single 800-token chunk that contains the complete answer. Same accuracy, nearly half the tokens.
Managing Chat History Without Losing the Thread
The final context cost trap is conversation history. In multi-turn applications, the standard approach is to include the entire conversation history in every request. By turn 50, you are sending tens of thousands of tokens of history in every API call — most of which the model barely uses.
The fix is hierarchical summarization. Keep the last 3–5 turns as raw text so the model has full fidelity on the recent context. For everything older, run a periodic summarization pass that condenses the conversation into a compact state summary — typically 200–500 tokens that capture the key decisions, preferences, and unresolved threads from the entire conversation.
This replaces 5,000+ tokens of raw history with 300 tokens of compressed state, cutting per-request context costs by 94% while maintaining the model’s ability to reference earlier parts of the conversation. For applications with long-running sessions — customer support agents, coding assistants, research workflows — this is the difference between $10 per conversation and $0.60.
The summarization pass itself can run on a cheap model (DeepSeek, Haiku 4.5) since it is a straightforward condensation task. You are spending a fraction of a cent to save dollars on every subsequent turn.
The Context Optimization Playbook
Every scenario below maps to one (or more) of the techniques covered above. Find yours and follow the recommendation.
Your chatbot re-sends a long system prompt on every turn.
Use exact prefix caching. Put your system prompt and few-shot examples at the start of every request, and the dynamic user content at the end. DeepSeek does this automatically — input drops from $0.28/M to $0.028/M on cached tokens. Anthropic requires manual cache breakpoints but gives you the same 90% savings. For a 20-turn conversation with a 5,000-token system prompt, caching alone saves you from paying for 95,000 redundant tokens.
Your FAQ or support bot handles thousands of similar questions daily.
Deploy a semantic cache (Redis + vector embeddings). Convert every incoming query to an embedding, check similarity against your cache. If similarity > 0.95, return the stored response without calling the LLM at all. For a bot where 60% of queries are repeat intents, this eliminates 6,000 model calls per day — 100% savings on each one.
You are processing large, messy documents (legal PDFs, technical manuals, compliance reports).
Run LLMLingua compression before sending to the model. A 10,000-token document with boilerplate, footers, and redundant phrasing compresses to 2,500–5,000 tokens at 2–4x ratio. The model often performs better on the compressed version because the noise is gone. An enterprise processing 5B tokens/month on Claude Opus 4.1 at $15/M input saves $56,250/month at 4x compression.
Your RAG pipeline retrieves too many chunks per query and costs are ballooning.
Switch from fixed-size chunking (512 tokens) to semantic chunking. Fixed chunks split documents at arbitrary boundaries, forcing the retrieval system to pull multiple fragments to answer one question. Semantic chunks align to natural topic boundaries, so you retrieve one cohesive chunk instead of three fragments. Token cost per retrieval drops ~50%, accuracy improves ~28%.
Your agent or assistant conversations grow expensive after 30+ turns.
Implement hierarchical summarization. Keep the last 3–5 turns as raw text. Summarize everything older into a compact 200–500 token state block using a cheap model (DeepSeek, Haiku). This replaces 5,000+ tokens of raw history with ~300 tokens. Per-request context costs drop by 94%, and the model still has the conversational thread.
You need all of the above — caching, compression, and smart chunking.
Stack them. They are not mutually exclusive. Structure your prompts for cache-friendly prefixes (caching). Compress dynamic content with LLMLingua before injection (compression). Use semantic chunking in your RAG pipeline (retrieval). Summarize long conversations periodically (memory). Each layer compounds on the last. A system using all four can realistically cut context costs by 95%+ compared to a naive implementation.
Part 2 Checklist
Structure every prompt so static content (system prompt, few-shot examples) comes first and dynamic content comes last — this maximizes cache hits
Enable prompt caching — automatic on DeepSeek, manual breakpoints on Anthropic — for any system prompt over 1,000 tokens
Deploy a semantic cache (Redis + embeddings) for any user-facing application with repetitive query patterns
Run LLMLingua (or equivalent) on long natural-language inputs before sending to the model — target 2–4x compression on documents with boilerplate
Replace fixed-size RAG chunking (512 tokens) with semantic chunking based on embedding similarity
Implement hierarchical summarization for multi-turn conversations — raw text for the last 3–5 turns, compressed state summary for everything older
Measure your cache hit rate weekly — if it is below 50% on a repetitive workload, your prefix structure or similarity threshold needs tuning
Test compression on your actual content before deploying — structured data (JSON, code) compresses less than natural language
Coming up in Part 3!

You have picked the right model (Part 1) and you are managing your context efficiently (Part 2). The final frontier is techniques that go beyond standard API usage — speculative decoding that doubles inference speed, activation probes that replace expensive LLM judges at 1/50th the cost, logit bias that kills verbose output, and batch processing that gives you a flat 50% discount on non-urgent work. Part 3 covers the advanced algorithmic and governance techniques that squeeze the last order of magnitude out of your AI spend.