

Practical AI Cost Reduction, Part 3: Advanced Algorithms and Governance
Speculative decoding, activation probes, batching, and taming autonomous agents


In Part 1 we covered the model pricing spectrum — how routing work to the right tier can cut costs by 20–100x before you touch a single prompt.

In Part 2 we tackled context optimization — caching, compression, and smarter retrieval that eliminate the waste in what you send to the model.

This final installment covers the techniques that go beyond standard API usage. These are the strategies that most teams never implement because they require understanding how inference actually works under the hood: speculative decoding, constrained output generation, activation-based monitoring, and batch processing economics. Each one targets a different cost surface, and combined, they squeeze the last order of magnitude out of your AI spend.
Speed Up Inference with Speculative Decoding
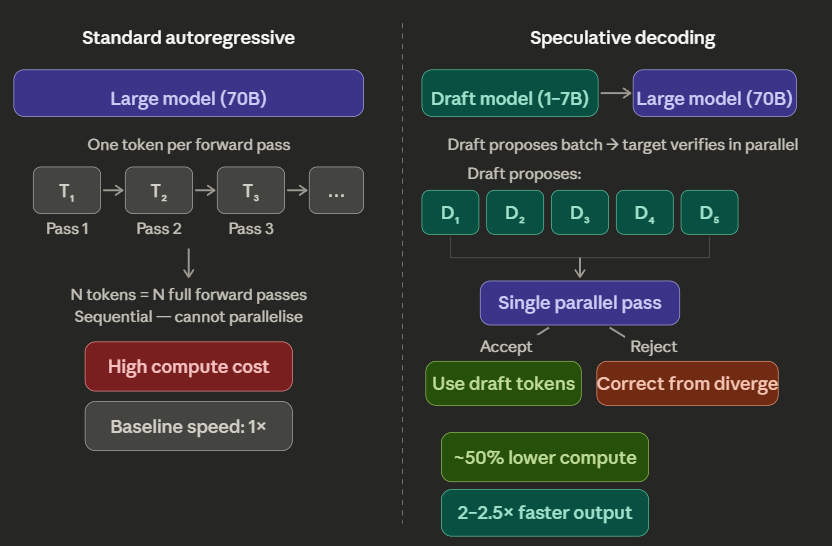
The fundamental bottleneck of LLM inference is that autoregressive models generate tokens one at a time. Each token requires a full forward pass through the model, and the next token cannot start until the previous one finishes. For a 70-billion-parameter model, this means every token costs the same amount of compute regardless of whether it is a predictable filler word or a genuinely novel insight.
Speculative decoding breaks this bottleneck by pairing a large “target” model with a small, fast “draft” model. The draft model — something like a 1–7B parameter distilled version — proposes a sequence of tokens (typically 5–10 at a time). The target model then verifies the entire proposed sequence in a single parallel forward pass. If the draft tokens match what the target model would have generated, they are accepted. If not, the target model corrects from the point of divergence.
The key insight is that the verification step is much cheaper than generating those tokens from scratch. The target model processes the proposed sequence in parallel rather than sequentially, and the draft model handles the bulk of the generation at a fraction of the cost.
Chen et al. (2023) demonstrated 2–2.5x speedup on Chinchilla 70B using this approach, with no degradation in output quality — the mathematical guarantee ensures the output distribution is identical to what the target model would have produced alone.
Variants push the speedup further. Medusa (Cai et al., 2024) adds multiple prediction heads directly to the target model, eliminating the need for a separate draft model entirely. Each head predicts a different future token position in parallel. Published benchmarks show 2.2x lossless speedup with Medusa-1 and 2.3–3.6x speedup with Medusa-2, which relaxes the strict distribution-matching requirement in exchange for even faster generation.
For production deployments, speculative decoding means you can serve the same quality output at roughly half the compute cost. If your inference bill is dominated by output tokens from a large model, this is one of the highest-leverage optimizations available — and it requires no changes to your prompts or application logic.
Kill Verbose Output with Logit Bias and Constrained Decoding
Output tokens are expensive. On Claude Opus 4.6, output costs $25 per million tokens — 5x the input cost. On Claude Opus 4.1, output is $75 per million. Every unnecessary token in your model’s response is a direct line item on your bill.
The problem is that models are trained to be helpful and conversational. They add preambles (”I’d be happy to help with that!”), transition phrases, disclaimers, and summaries you did not ask for. A data extraction task that should return 50 tokens of clean JSON often returns 200 tokens of JSON wrapped in conversational padding.
Logit bias fixes this at the decoding level. Most API providers expose a logit_bias parameter that lets you adjust the probability of specific tokens during generation. Apply a strong negative bias (−80 to −100) to common filler tokens — “certainly”, “however”, “I’d”, “happy” — and the model skips them entirely. The output becomes more direct without any change to your prompt or fine-tuning.
Constrained decoding takes this further. Libraries like Outlines and Guidance let you enforce a grammar or JSON schema on the model’s output. The model cannot generate tokens that violate the schema — invalid JSON keys, wrong data types, extra fields. This eliminates retry loops where you call the model again because the first response had malformed output.
The combined effect: output length drops by 30–40%, retry rates drop to near zero, and your effective output cost per successful response drops proportionally. For a firm extracting structured data from invoices where the model typically adds 40% conversational filler, logit bias alone cuts the monthly output token bill by thousands of dollars at scale.

Replace Your LLM Judge with Activation Probes
One of the biggest hidden costs in enterprise AI is the “judge” pattern — using a second model to monitor the first model’s output for safety, PII, quality, or policy compliance. If your production model generates a response and you then send that response to GPT-5 Pro or Gemini Flash for safety screening, you are effectively doubling your inference cost on every interaction.
Activation probes offer a radically cheaper alternative. During the normal forward pass, an LLM generates internal hidden states (activations) at every layer. These activations already encode information about what the model “knows” about its own output — including whether the content is safe, contains PII, or violates policy guidelines.
A probe is a simple linear classifier (often just a single matrix multiplication) trained on these internal activations. It runs on the activations that are already being computed during the model’s normal generation — no additional forward pass required. The marginal compute cost is negligible compared to a full model call.
The results are striking: a “Probe-Flash Cascade” architecture — where the probe handles the initial screen and only flags uncertain cases for a full LLM judge — achieves comparable monitoring accuracy at roughly 1/50th of the inference cost. The expensive LLM judge only processes the 5–10% of responses where the probe is uncertain, rather than every single interaction.
For practical deployment, this means a healthcare company monitoring 10 million daily interactions for PII does not need to run every response through a second model. The activation probe handles 90%+ of the screening, and the LLM judge only reviews the edge cases. A monitoring budget that would be $250,000 per month with a full LLM judge drops to under $25,000.
Research has shown these probes can detect concerning patterns — including intentional underperformance (”sandbagging”) and hidden goal-seeking — with 90–96% accuracy, providing a layer of governance that standard output analysis cannot match.
Batch Your Non-Urgent Work for 50% Off
Not every inference request needs a real-time response. Log analysis, quarterly reporting, bulk data enrichment, content moderation backlogs, embedding generation — these tasks have deadlines measured in hours or days, not milliseconds.
Both OpenAI and Anthropic offer Batch API endpoints with a flat 50% discount on all tokens — input and output. You submit your requests as a .jsonl file, the provider processes them within a 24-hour window during off-peak capacity, and you download the results when they’re ready.
A $10,000 synchronous inference bill for a monthly data processing pipeline becomes $5,000 through the Batch API. The only trade-off is latency, and for analytical workloads that run overnight, that trade-off is free money.
The operational pattern is straightforward: any task where the result is not needed within the hour should be batched. Set up a queue that accumulates non-urgent requests throughout the day and submits them as a single batch at midnight. Your production API handles real-time user interactions at full price, and everything else gets the 50% discount automatically.
The Runaway Agent Problem
A final cost governance note for teams deploying autonomous agents: agents fail in loops.
A coding agent that gets stuck on a type error will retry the same approach dozens of times, generating thousands of output tokens per attempt. Without guardrails, a single stuck agent can burn $200 in 30 minutes before anyone notices. This is not hypothetical — it happens regularly in production deployments with insufficient monitoring.
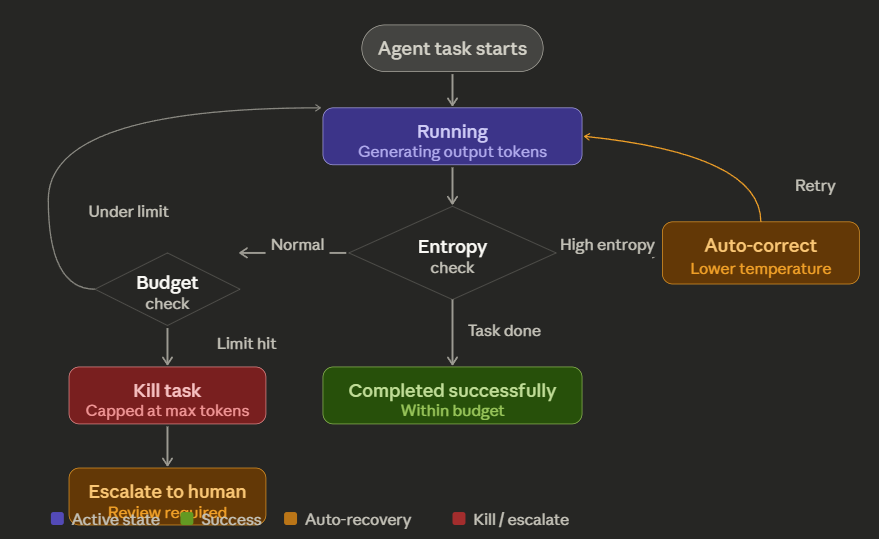
The fix is an adaptive token budget. Set a hard per-task token ceiling. Monitor the agent’s output entropy — if the model keeps generating high-entropy (uncertain) tokens without making progress, that is a signal it is stuck. Automatically lower the temperature and trigger an early exit. If the agent exceeds its budget, kill the task and escalate to a human.
This is not optional for production agent deployments. Token budgets are the seatbelts of AI cost management.
The Advanced Techniques Playbook
Here is how each technique maps to specific production scenarios. Find yours.
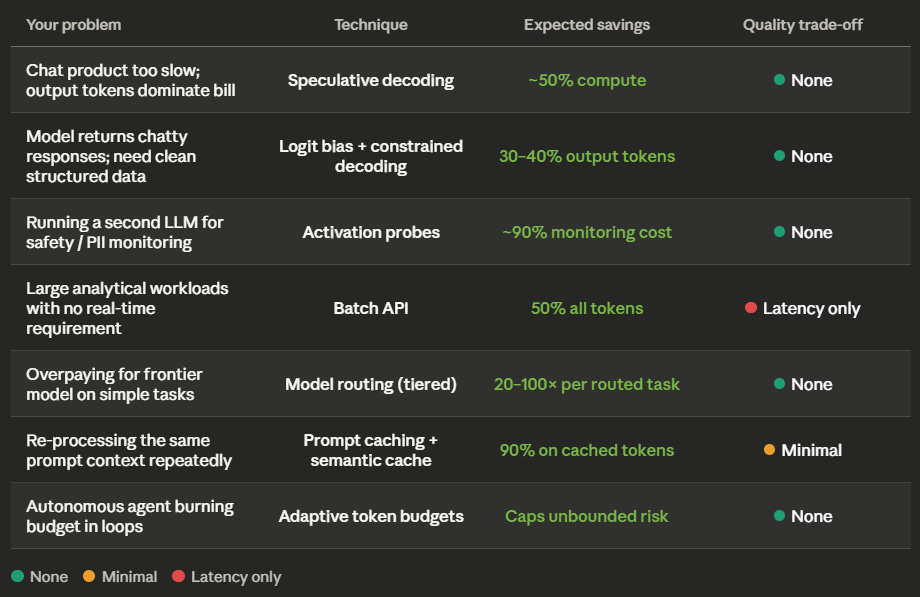
Your users complain that your chat product is too slow, and your inference bill is mostly output tokens.
Deploy speculative decoding. Pair your large target model with a small draft model (1–7B params). The draft model proposes tokens, the target model verifies in parallel. You get 2–2.5x faster generation at roughly half the compute cost, with mathematically identical output quality. If you cannot run a second model, look at Medusa heads — same speedup without a separate draft model (2.2–3.6x).
Your model returns verbose, chatty responses when you need clean structured data.
Apply logit bias (-80 to -100) on common filler tokens (”certainly”, “I’d be happy to”, “here is”) and enforce a JSON schema via constrained decoding (Outlines, Guidance). Output length drops 30–40%, retry rates from malformed output drop to near zero. For a data extraction pipeline producing 10M output tokens/month on Claude Opus 4.6 ($25/M), this saves $75,000–$100,000 a year in output cost alone.
You are running a second LLM to monitor the first for safety, PII, or quality.
Replace the LLM judge with an activation probe. Train a light linear classifier on the production model’s internal hidden states. The probe screens 90%+ of responses at negligible compute cost. Only the 5–10% of uncertain cases escalate to the expensive judge model. Monitoring cost drops by ~90%. A healthcare company screening 10M daily interactions saves $225,000/month vs. running every response through a second model.
You have large analytical workloads that do not need real-time results.
Use the Batch API. OpenAI and Anthropic both offer 50% off on all tokens for batched requests processed within a 24-hour window. Set up a queue that collects non-urgent work (log analysis, embedding generation, bulk enrichment) and submits a nightly batch. A $10,000/month synchronous bill becomes $5,000 with zero quality trade-off.
Your autonomous coding agent burned $200 in 30 minutes because it got stuck in a loop.
Implement adaptive token budgets immediately. Set a hard per-task ceiling (e.g., 50,000 output tokens). Monitor output entropy — high entropy over sustained generation means the model is confused and looping. Auto-lower temperature and kill the task if the budget is exceeded. Escalate to a human reviewer. This turns an unbounded cost risk into a predictable, capped expense.
You need a 70B+ model’s reasoning quality but cannot afford the per-query cost at scale.
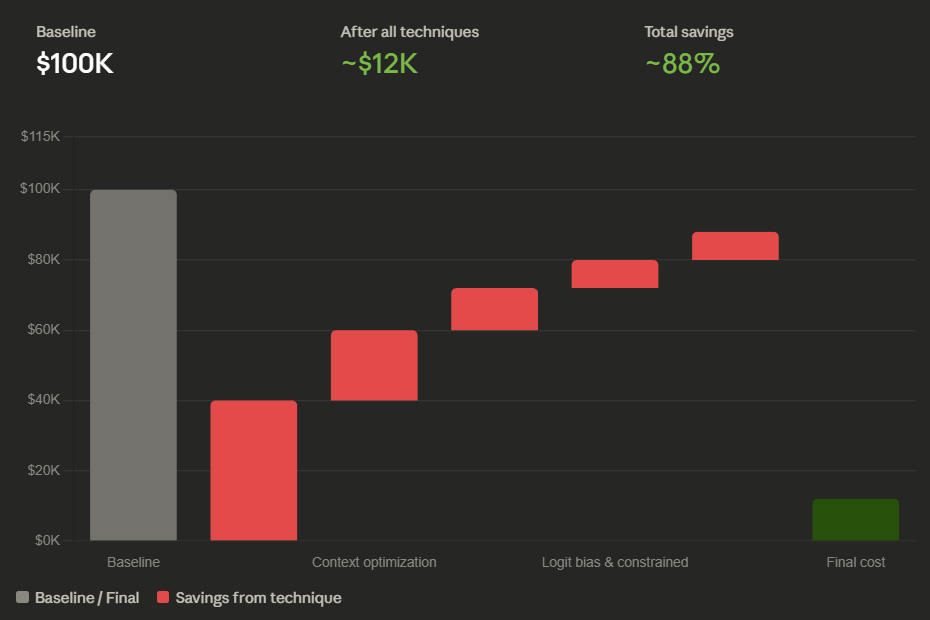
Combine techniques: use speculative decoding to cut per-query compute by ~50%, add logit bias to trim output by 30–40%, and batch all non-urgent queries for another 50% off. Stacked together, a $100,000/month inference bill can realistically drop to $15,000–$25,000 without changing the model or sacrificing output quality.
Wrapping Up the Series
Across three articles, we have covered the full stack of AI cost reduction:
Part 1 — The Tactical Stack: Pick the right model for the task. Use OpenRouter to route cheap work to value-tier models (DeepSeek at $0.28/M input, Qwen at $0.05/M) and reserve frontier models (Opus at $5/M, Sonnet at $3/M) for work that genuinely needs them. This alone can cut costs by 20–100x on the tasks you’re currently overpaying for.
Part 2 — Context Optimization: Stop re-processing the same tokens. Prompt caching gives you 90% discounts on static prefixes. Semantic caching bypasses the model entirely for repeat intents. LLMLingua compresses dynamic inputs by 2–6x. Semantic chunking halves your RAG retrieval costs. Hierarchical summarization keeps conversation history manageable.
Part 3 — Advanced Techniques: Speed up generation with speculative decoding (2–2.5x). Kill verbose output with logit bias and constrained decoding (30–40% output reduction). Replace expensive LLM judges with activation probes (50x cheaper monitoring). Batch non-urgent work for 50% off. Put token budgets on every autonomous agent.
None of these techniques require sacrificing output quality. The math works because the default way most teams use LLMs — one model for everything, full context every time, no output constraints, no batching — wastes 90% or more of the spend. Fix the waste and the quality stays the same.
Treat AI compute as a finite resource. The economics reward the teams that respect the budget.
Part 3 Checklist
Evaluate speculative decoding for any workload where output tokens dominate your bill — pair your large model with a small draft model for 2–2.5x speedup at half the compute
Apply logit bias (-80 to -100) on common filler tokens for all structured data extraction and JSON generation tasks
Enforce output schemas via constrained decoding (Outlines, Guidance) to eliminate retry loops from malformed responses
Replace any LLM-as-judge monitoring with activation probes — train a linear classifier on the production model’s hidden states for 50x cheaper safety screening
Move all non-real-time work (log analysis, bulk enrichment, embedding generation, quarterly reports) to the Batch API for 50% off
Set hard per-task token budgets on every autonomous agent — monitor output entropy and auto-kill looping tasks
Stack techniques: speculative decoding (speed) + logit bias (brevity) + batching (discount) compound to 75–85% total savings
Review your full inference stack monthly — model routing (Part 1) + context optimization (Part 2) + advanced techniques (Part 3) — and re-benchmark as model pricing changes