

Practical AI Cost Reduction, Part 1: The Tactical Stack
How model routing and tier selection can cut your inference spend by 20–100x


I spent $340 in one week running Claude Opus 4.6 on full codebase scans. Repeat scans, debugging loops, architecture reviews — all piped through a model that charges $5 per million input tokens and $25 per million output tokens. The same work on DeepSeek V3.2, with its automatic input caching, cost me under $2.
That gap is the entire thesis of this series.
Frontier models keep getting smarter in 2026. They also keep getting expensive when you use them carelessly. The difference between a $6 task and a $0.02 task comes down to which model you pick and how you route the work. This three-part series breaks down exactly how to cut those costs — whether you are a solo developer, a growing SMB, or running inference at enterprise scale.
The Model Pricing Spectrum
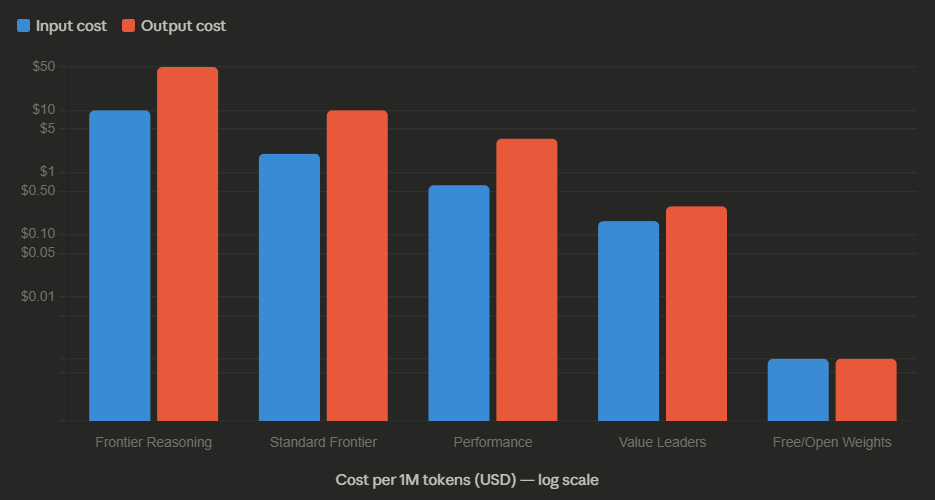
The pricing gap between “reasoning” and “standard” models has become extreme. Providers now offer massive context windows at dirt-cheap prices for everyday tasks, but charge 10–60x premiums for chain-of-thought reasoning modes where the model spends extra compute thinking through problems.
Here is what the pricing landscape looks like across the dominant tiers in early 2026, verified from provider documentation as of March 2026.
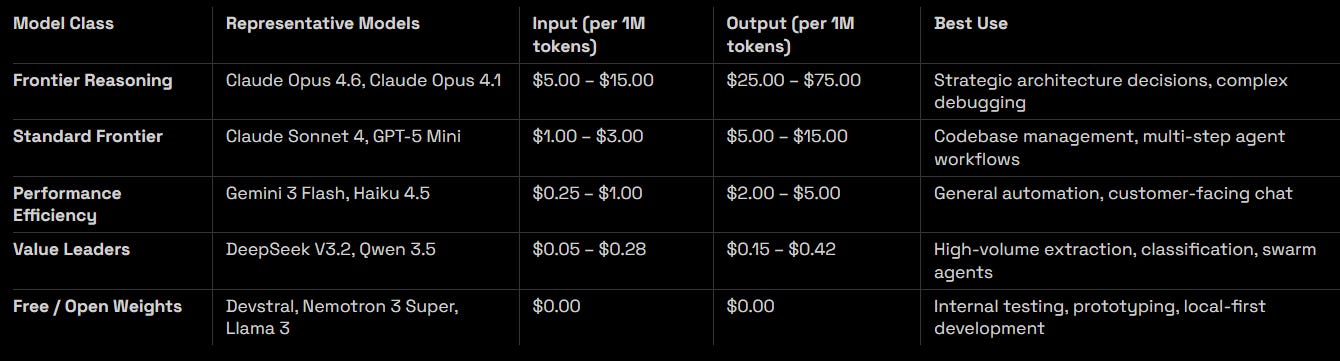
The number that matters most: sending one million tokens through Claude Opus 4.6 costs $5 in and $25 out. The same tokens through DeepSeek V3.2 cost $0.28 in and $0.42 out. With DeepSeek’s automatic caching on repeat inputs, that input price drops to $0.028 per million — roughly 178x cheaper on input alone. Even accounting for output, the all-in gap between frontier and value tiers ranges from 20x to well over 100x depending on the workload.
If you are still sending every task to a single frontier model, you are lighting money on fire.
Why OpenRouter Changes the Economics
Locking yourself into one provider is a financial and operational risk. When your primary model goes down or gets rate-limited, you are stuck. When a cheaper model could handle 90% of your workload, you are overpaying by an order of magnitude.
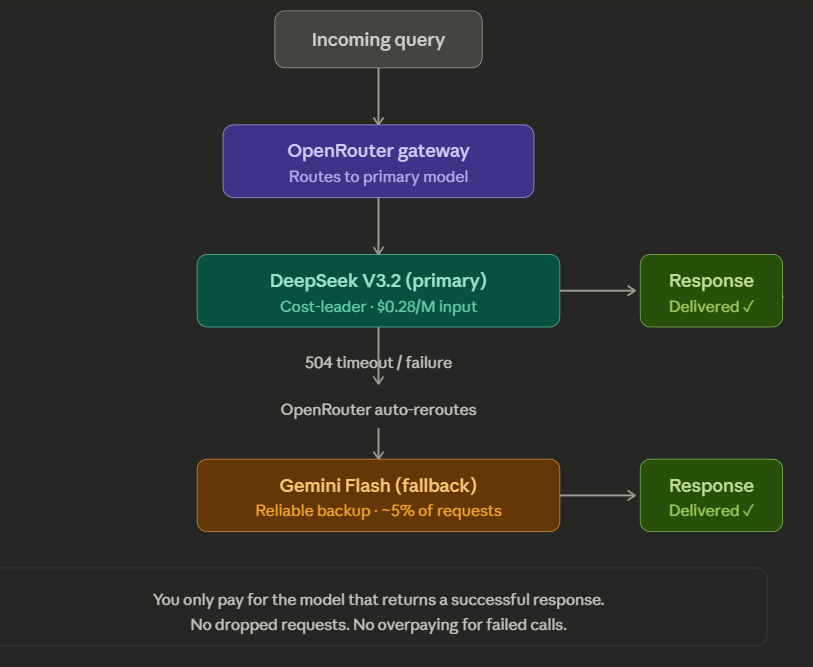
OpenRouter solves this by giving you a single API gateway to hundreds of models across providers. You get unified billing, automatic fallback routing, and provider-level load balancing — all behind one integration. If your primary model (say, DeepSeek) hits high latency or returns a 504, the system automatically rotates to a backup (say, Gemini Flash). You only pay for the successful response.
This is not just about convenience. OpenRouter’s provider sorting lets you prioritize by price, throughput, or latency on a per-request basis. You can set performance thresholds — “route to the cheapest provider that delivers at least 50 tokens per second at the p90 level” — and the system handles the rest. For enterprise teams, there is EU data residency routing, zero-data-retention enforcement, and quantization filtering. You build one integration and get access to the full cost spectrum without managing individual provider SDKs.
Crucially, the fallback mechanism means you never pay for failed requests. When your cost-leader model has an outage, the request redirects to a reliable backup automatically. You get value-tier pricing 95% of the time and never drop a production request.
What to Build Based on Your Scale
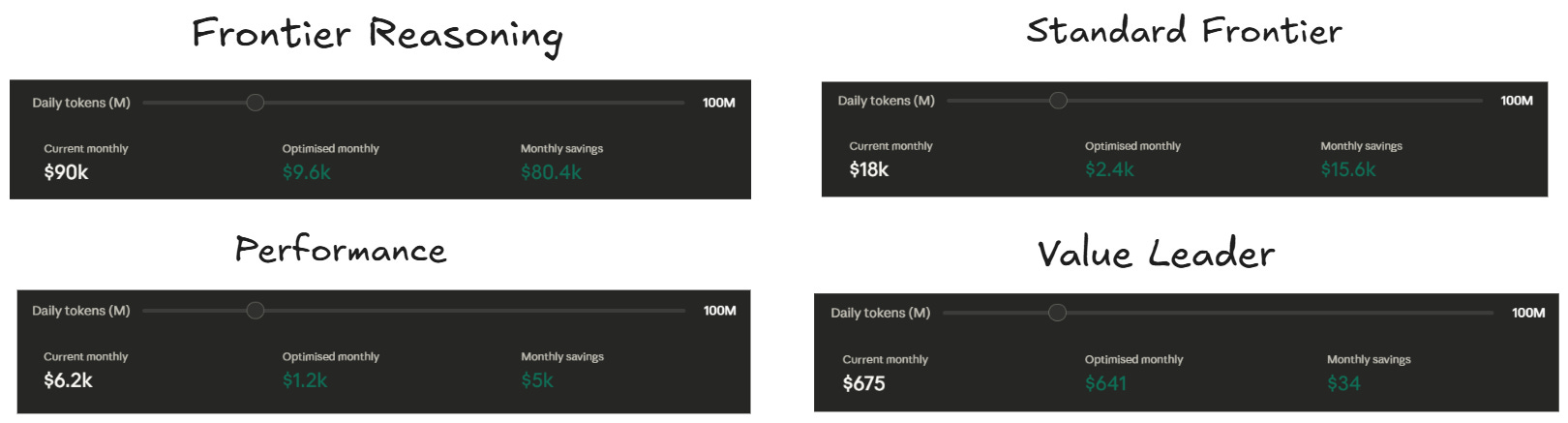
Your cost optimization strategy depends entirely on how much inference you run. A solopreneur burning $30 a month needs a different playbook than an enterprise processing billions of tokens daily.
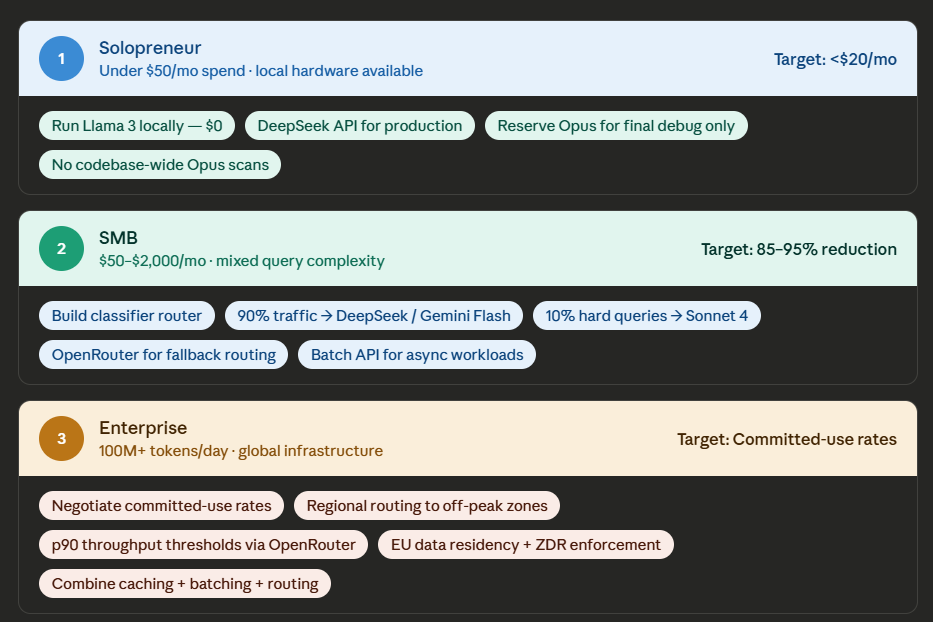
If You Are a Solopreneur, Go Local First
Run a capable open-weight model locally — Llama 3, Nemotron 3 Super, or Qwen 3.5 on a machine with 24GB+ VRAM. That gives you unlimited free inference for anything non-customer-facing: prototyping, code exploration, initial drafts. For production-quality output where reliability matters, route through DeepSeek’s API. With their automatic input caching at $0.028 per million cached tokens, you should be spending under $20 a month even with heavy daily usage.
The mistake most solo developers make is using Claude Opus or a frontier model inside Cursor or Replit for entire codebase scans. I did this. It cost me over $100 a day. Moving initial discovery and boilerplate generation to free local models, and reserving the frontier model for final debugging passes only, cut that to under $5 daily.
If You Are an SMB, Build a Classifier Router
Set up a lightweight classifier at the front of your pipeline. Simple tasks — FAQ responses, status checks, classification — go to ultra-budget models like Gemini Flash or DeepSeek in non-thinking mode. Complex analysis gets escalated to Claude Sonnet 4 or GPT-5 Mini.
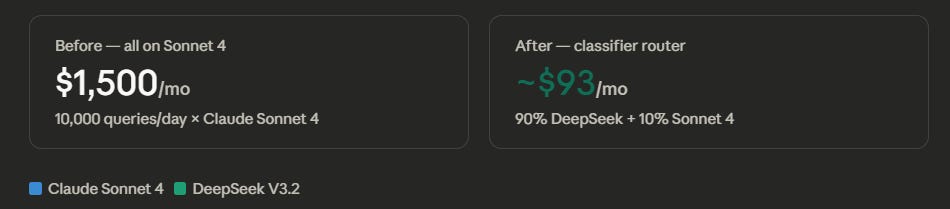
Consider the math: a support bot processing 10,000 queries a day on Claude Sonnet 4 at $3 per million input and $15 per million output costs roughly $1,500 a month. Route 90% of that traffic to DeepSeek at $0.28/$0.42 per million, and your monthly bill drops under $100.
Add prompt caching on top (covered in detail in Part 2 of this series), and you reduce costs by another 50–90% on repetitive customer interactions.
If You Run Enterprise, Negotiate and Route Regionally
At scale, you negotiate. Commit to specific throughput levels through OpenRouter or directly with providers, and you get rates well below pay-as-you-go. Layer in regional routing to push non-urgent work to off-peak time zones where providers offer lower priority-tier pricing. A global fintech firm processing 100 million tokens daily can meaningfully trim their bill by pinning data enrichment tasks to US-East servers at 3:00 AM when throughput is high and demand is low.
OpenRouter supports this natively with performance threshold settings — you can require minimum throughput at the p90 level, sort by price, and let the system find the cheapest provider that meets your latency SLA.
How This Plays Out in Practice
All of the above sounds good in theory. Here is how it works across four real scenarios.
The Vibe-Coding MVP
You are building an MVP and using Claude Opus for everything inside your AI-powered IDE. Full codebase scans, auto-completion, architecture advice — all hitting a model that charges $25 per million output tokens. You are spending $100 a day and wondering if AI-assisted development is worth the cost.
The fix is straightforward. Move initial code exploration and boilerplate generation to a free local model. Use something like Devstral or Nemotron 3 Super for the first pass — they handle scaffolding and basic edits well enough. Reserve Opus for the moments that actually need it: debugging subtle logic errors, reviewing complex architectural decisions, catching security vulnerabilities. This approach cut my daily spend from $100 to under $5 without any noticeable drop in development speed.
The Support Bot Drowning in Costs
An SMB runs a customer support bot processing 10,000 queries daily. Every query hits Claude Sonnet 4 ($3 input, $15 output per million tokens). Monthly cost: $1,500 and climbing.
The fix is a mini-router. A lightweight classifier reads each incoming query and categorizes it. “Easy” queries — password resets, order status, return policies — get routed to DeepSeek at $0.42 per million output. “Hard” queries — billing disputes, nuanced complaints — stay on Sonnet. When 90% of your traffic is simple and only 10% needs the expensive model, your bill drops from $1,500 to under $100.
The Unreliable Provider Problem
DeepSeek V3.2 is the cost leader, but it occasionally suffers from 504 timeouts during peak traffic. You cannot afford dropped requests in production.
The answer is non-billed fallback routing through OpenRouter. Set DeepSeek as your primary and Gemini Flash as your automatic backup. If DeepSeek fails to respond within your timeout window, OpenRouter re-routes to the backup. You only pay for the model that actually returns a successful response. You get DeepSeek pricing 95% of the time and never drop a request.
The Non-Urgent Data Backlog
Your team needs to process 50 million tokens of log data for a quarterly security audit. Nobody needs these results in real time — you just need them before Monday.
Skip the synchronous API entirely. Both OpenAI and Anthropic offer Batch API endpoints with a flat 50% discount on all tokens — input and output. You submit your requests as a .jsonl batch file, the provider processes them within a 24-hour window during off-peak capacity, and you download the results. A $5,000 synchronous bill becomes $2,500. The only trade-off is latency, and for non-urgent analytical work, that trade-off is free money.
The common thread across all of these scenarios is the same: stop treating AI inference as a single price. It is a spectrum, and the right model for the right task is always cheaper than the best model for every task.
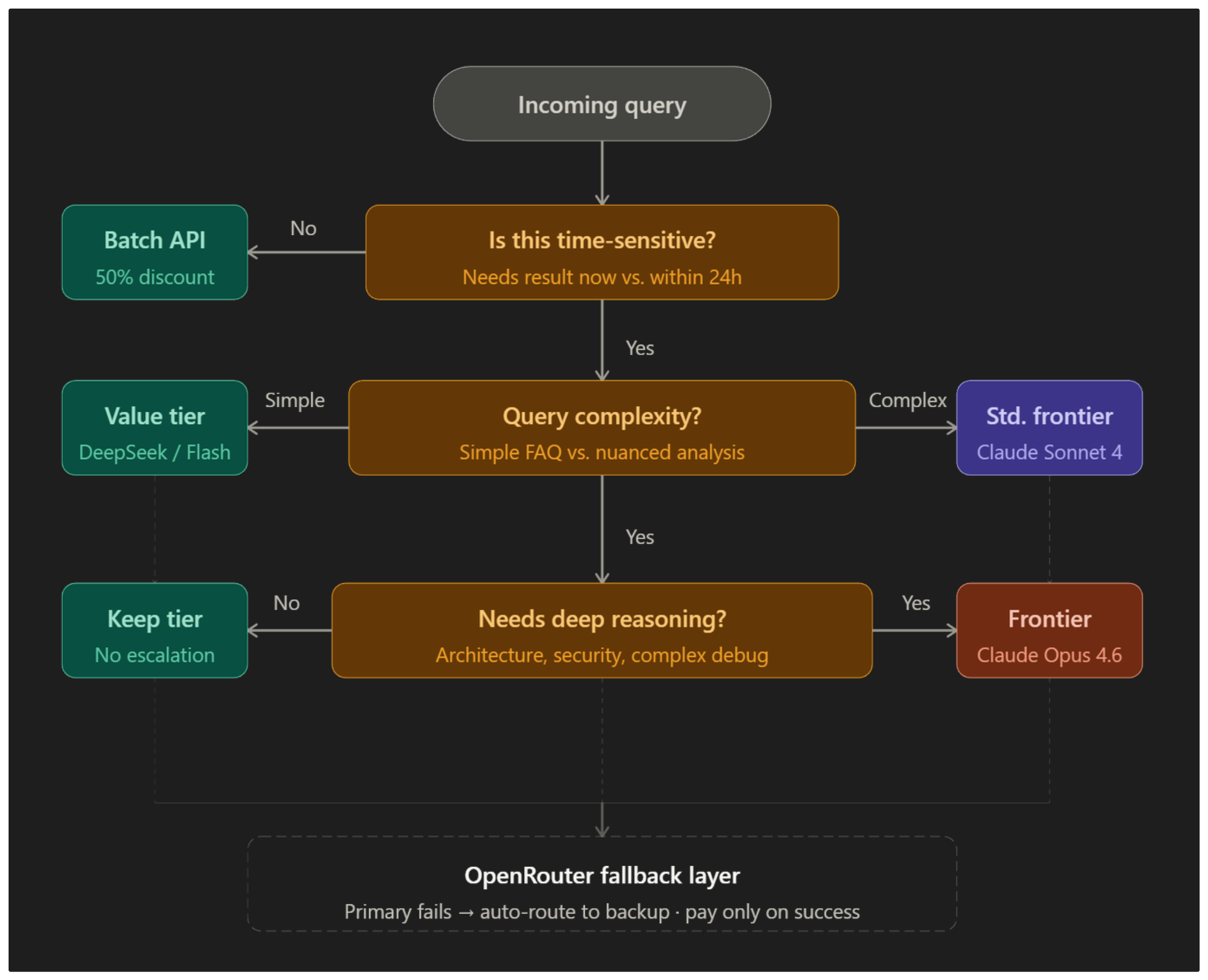
The Model Routing Playbook
If the scenarios above still leave you unsure which model tier to pick for your specific situation, use this decision playbook. Find your scenario, follow the recommendation.

You are prototyping or exploring code locally.
Use a free open-weight model (Devstral, Nemotron 3 Super, Llama 3). Zero cost, instant feedback, no API dependency. Upgrade to DeepSeek V3.2 only when you need higher quality or longer context than local hardware supports.
You are building a customer-facing chatbot with mostly repetitive queries.
Route through a classifier. Easy queries (password resets, order status, FAQs) go to DeepSeek or Gemini Flash at $0.28–$1.00 per million input. Hard queries (billing disputes, complaints needing judgment) escalate to Claude Sonnet 4 or GPT-5 Mini. Expected savings: 85–95% vs. running everything on a standard frontier model.
You need complex reasoning, debugging, or architecture review.
This is the only scenario where a frontier reasoning model (Claude Opus 4.6, Opus 4.1) is worth the premium. Use it surgically — single focused prompts, not open-ended codebase scans. Pair with a cheaper model for initial discovery so the frontier model only sees the refined problem.
Your production API depends on a single cost-leader provider.
Set up fallback routing through OpenRouter. Primary: your cost-leader (DeepSeek). Backup: a reliable alternative (Gemini Flash, Haiku 4.5). You only pay for whichever model actually returns the response. No more dropped requests during outages.
You have a large batch of non-time-sensitive work (log analysis, data enrichment, quarterly reports).
Use the Batch API from OpenAI or Anthropic for a flat 50% discount. Submit as .jsonl, get results within 24 hours. There is no reason to pay synchronous prices for work that does not need real-time responses.
You are an enterprise processing 100M+ tokens daily.
Negotiate committed-use rates through OpenRouter or directly with providers. Layer in regional routing to push non-urgent tasks to off-peak time zones. Combine with prompt caching (Part 2) and batching (Part 3) for compounding savings.
You are not sure which tier a new use case needs.
Start with the cheapest viable model and test quality. Run 100 sample requests through DeepSeek V3.2, then the same 100 through Claude Sonnet 4. If quality is comparable for your use case, stay on the cheap tier. Only escalate when you can demonstrate a measurable quality gap that justifies the 10–50x price premium.
Part 1 Checklist
Audit your current model usage — which model handles which tasks and what does each cost per million tokens?
Identify tasks that do not need a frontier model (boilerplate generation, classification, FAQ, status checks) and move them to a value-tier model (DeepSeek V3.2, Qwen 3.5, Gemini Flash)
Set up OpenRouter (or equivalent gateway) with fallback routing so you never pay for failed requests
Run a local open-weight model (Devstral, Nemotron 3 Super, Llama 3) for internal prototyping and exploration — zero cost
Build a lightweight classifier router if you handle mixed-complexity traffic (route easy queries cheap, escalate hard ones)
Use the Batch API for any non-urgent analytical work — flat 50% discount, no quality trade-off
Default to the cheapest viable model for new use cases — only escalate when you can prove a measurable quality gap
Track your per-task cost, not just your monthly bill — the savings are in routing decisions, not bulk discounts
Coming Up in Part 2!

Once you have picked the right model, the next biggest cost lever is how much context you send it. Context bloat — re-sending the same system prompts, ballooning conversation histories, bloated documents full of noise — is the silent budget killer of 2026. Part 2 covers the technical mechanisms that fix it: prompt caching that cuts repeat input costs by 90%, semantic caching that bypasses the model entirely for common queries, prompt compression that trims dynamic inputs by 2–6x, and intelligent RAG chunking that halves your retrieval token usage. If your system prompt is longer than 1,000 tokens and you send it with every request, you are almost certainly overpaying.