

My AI Operating System + Second Brain Setup That Actually Compounds (Copilot + Obsidian)
Why Obsidian beats every SaaS note app — and the exact configuration that makes it feel inevitable.


I drowned myself in building a knowledge OS, not because it was trendy, but because I got tired of renting my brain to other people’s servers. Every note in Notion, Evernote, or Google Docs lives on someone else’s machine. You pay monthly for the privilege. If they pivot, raise prices, or shut down, you scramble. You export. You lose context.
I wanted something different. A system where I own the data. Where files sit on my hard drive as plain Markdown. Where no company can hold my knowledge hostage. And where every note compounds with the next one. Every connection surfaces something I forgot I knew.
This is how I built it, and why it’s now generating 4-5x the content output while requiring less manual effort.
The Philosophy (Locality, Simplicity, Permanence)
I built infrastructure on purely three major pain points and decisions:
Locality. Every note is a
.mdfile ind:\Atharva\NOTES. If Obsidian dies, the vault survives. Text files outlive apps, companies, platforms.Start fresh. I didn’t import old Docs chaos. I let the structure earn its place. You can’t organize chaos better. You can only recognize it.
Never delete. Notes go to Archive, not trash. Storage is cheap. Regret costs more.
The math is different from SaaS. Pay once for Obsidian (or use it free) and your files stay yours. No monthly rent. No proprietary format. No platform dependency.

Prefer the Video Version? Here’s A Quick Demo
The Foundation = File System Architecture
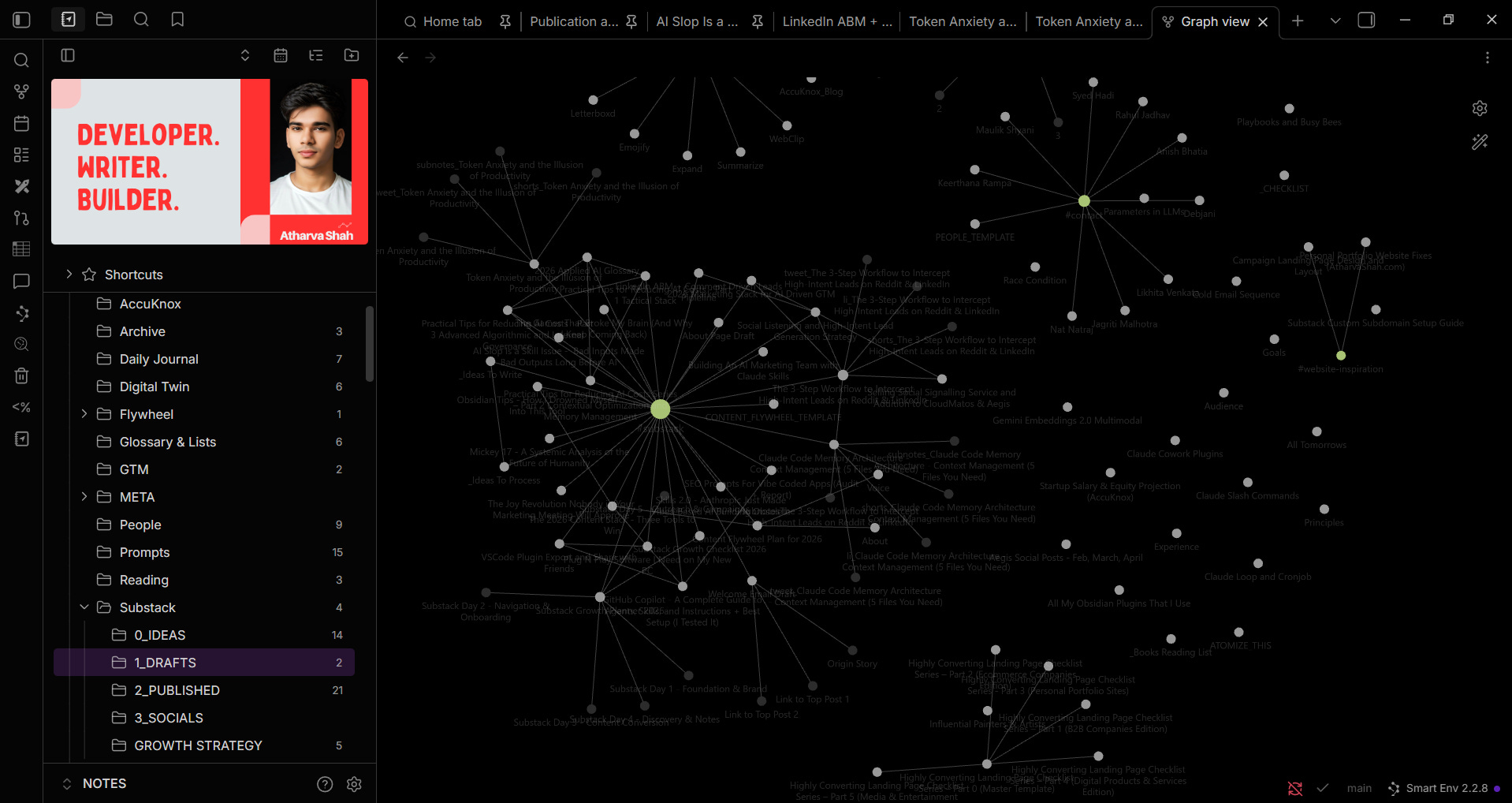
his vault looks overwhelming at first. It’s not. It’s flat and intentional. Bury ideas three directories deep and they die.
Structure I use:
Root (
.claude,.vscode,README.md,CLAUDE.md) — Config and workflowsINBOX — Raw captures. Active. Unpolished.
DAILY — One file per day. Work tasks, notes, things I want to remember.
DIGITAL TWIN — Everything about me: voice, audience, experience, goals, principles. The grounding layer.
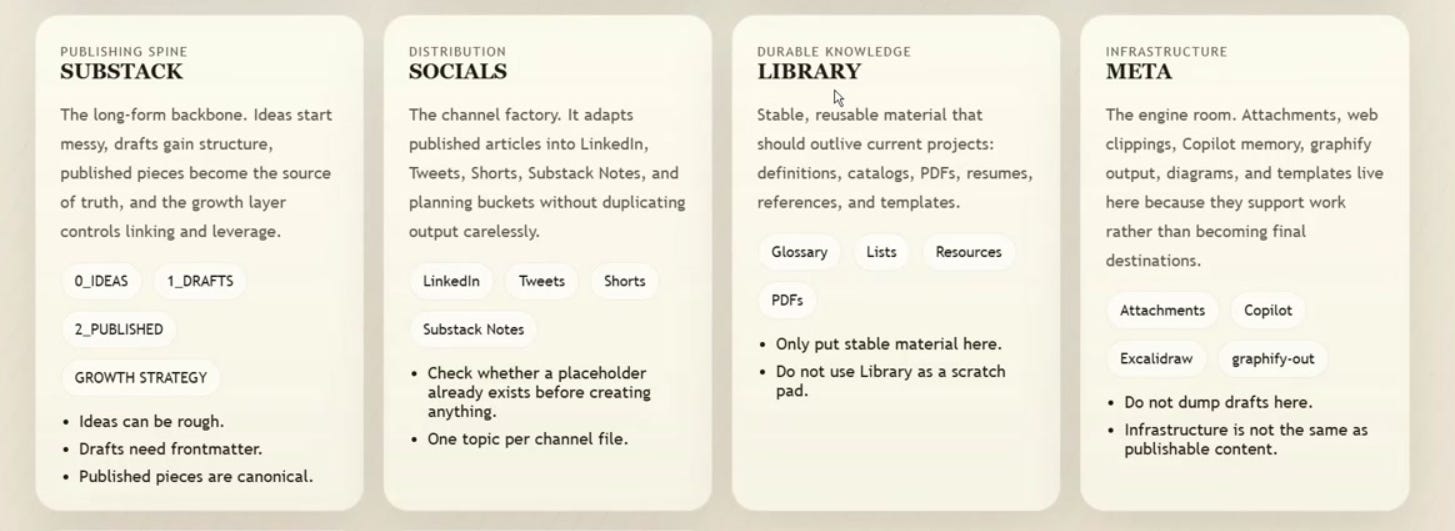
SUBSTACK — Ideas → Drafts → Published
SOCIALS — Twitter, LinkedIn, Shorts, Substack Notes (one per channel)
LIBRARY — Stable reference. Glossary, lists, resources.
META — Engine room. Templates, Copilot memory, Excalidraw, graphify.
I pin crucial folders with underscore prefixes (_INBOX) so they float to the top of file explorer. Iconize plugin adds folder emojis. Scanning the sidebar is instant.
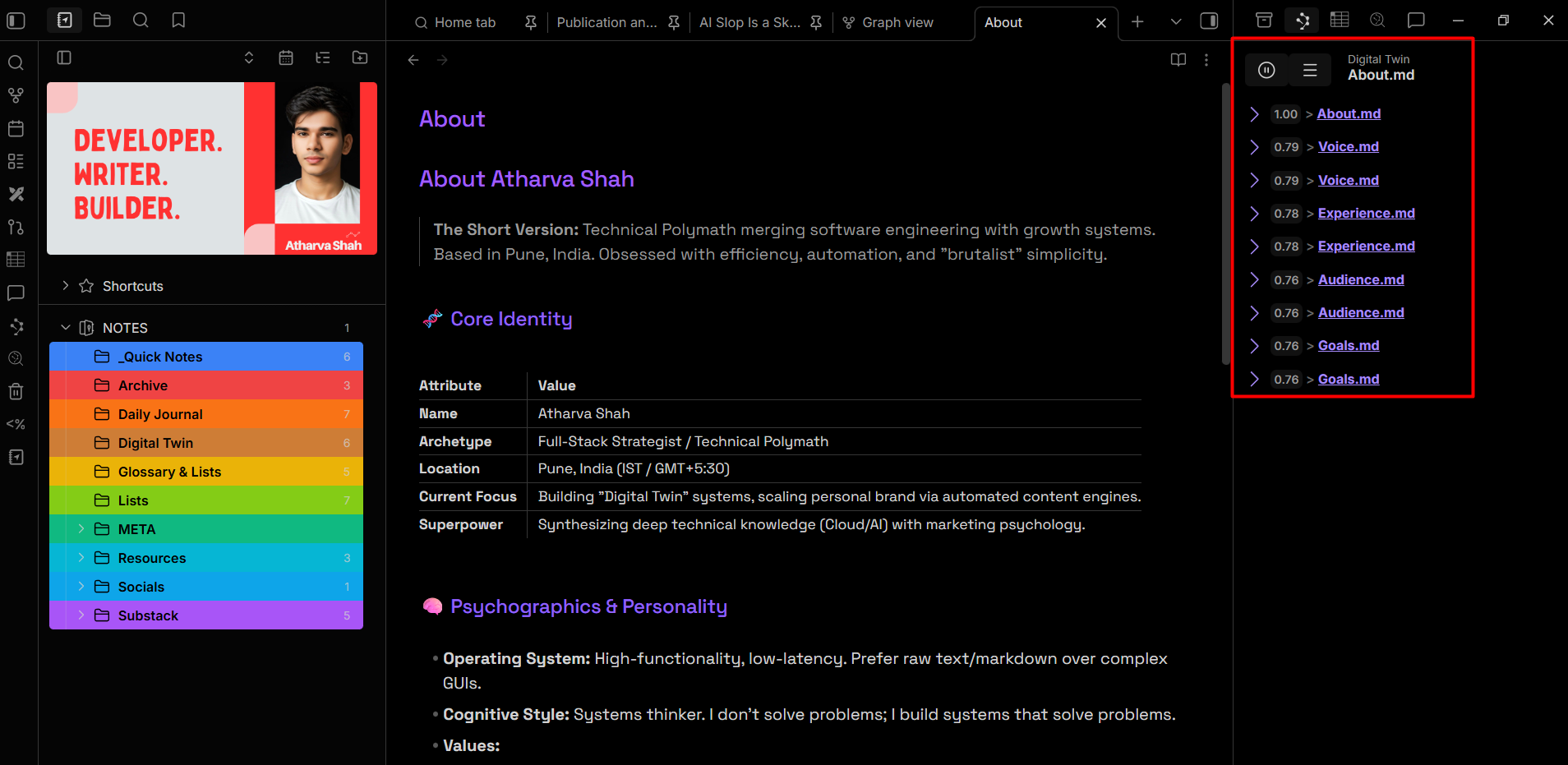
Below that sits META, the engine room. This holds my templates, web clippings, Copilot prompt files, and Excalidraw drawings. One of the most important thing it holds is the templates used by the Templater plugin.
I built an HTML visualization to make sense of this without forcing everything into one page. Vault Atlas has separate views for structure, publishing, automation, and recovery. It’s there for when you forget where things live.
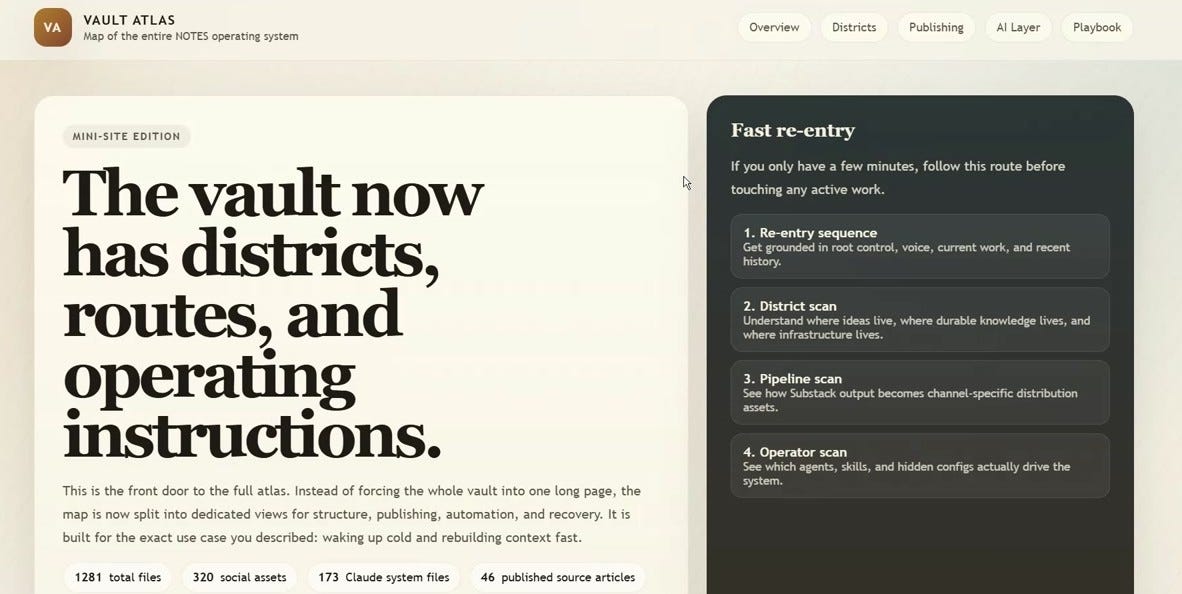
The System Model Has Four Layers
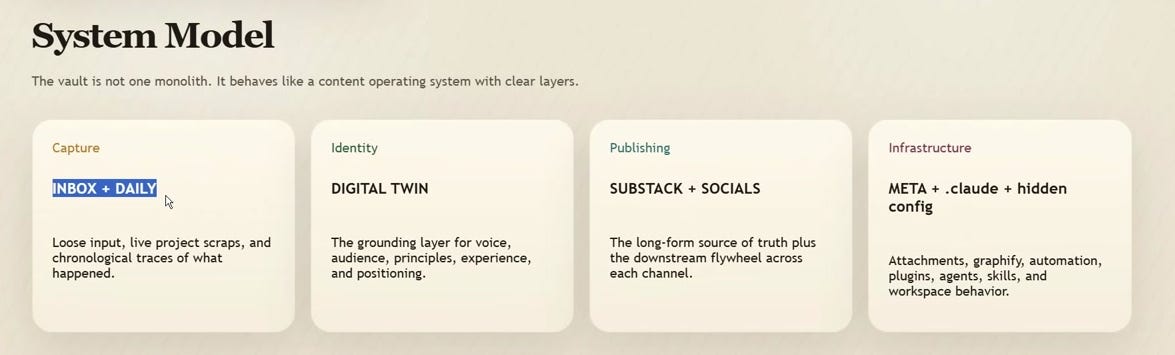
The vault behaves like an OS with four layers:
Capture (INBOX + DAILY) — Loose input and traces
Identity (DIGITAL TWIN) — Voice, audience, principles, experience
Publishing (SUBSTACK + SOCIALS) — Long-form source plus the distribution flywheel
Infrastructure (META + .claude + config) — Attachments, automation, skills, workspace behavior
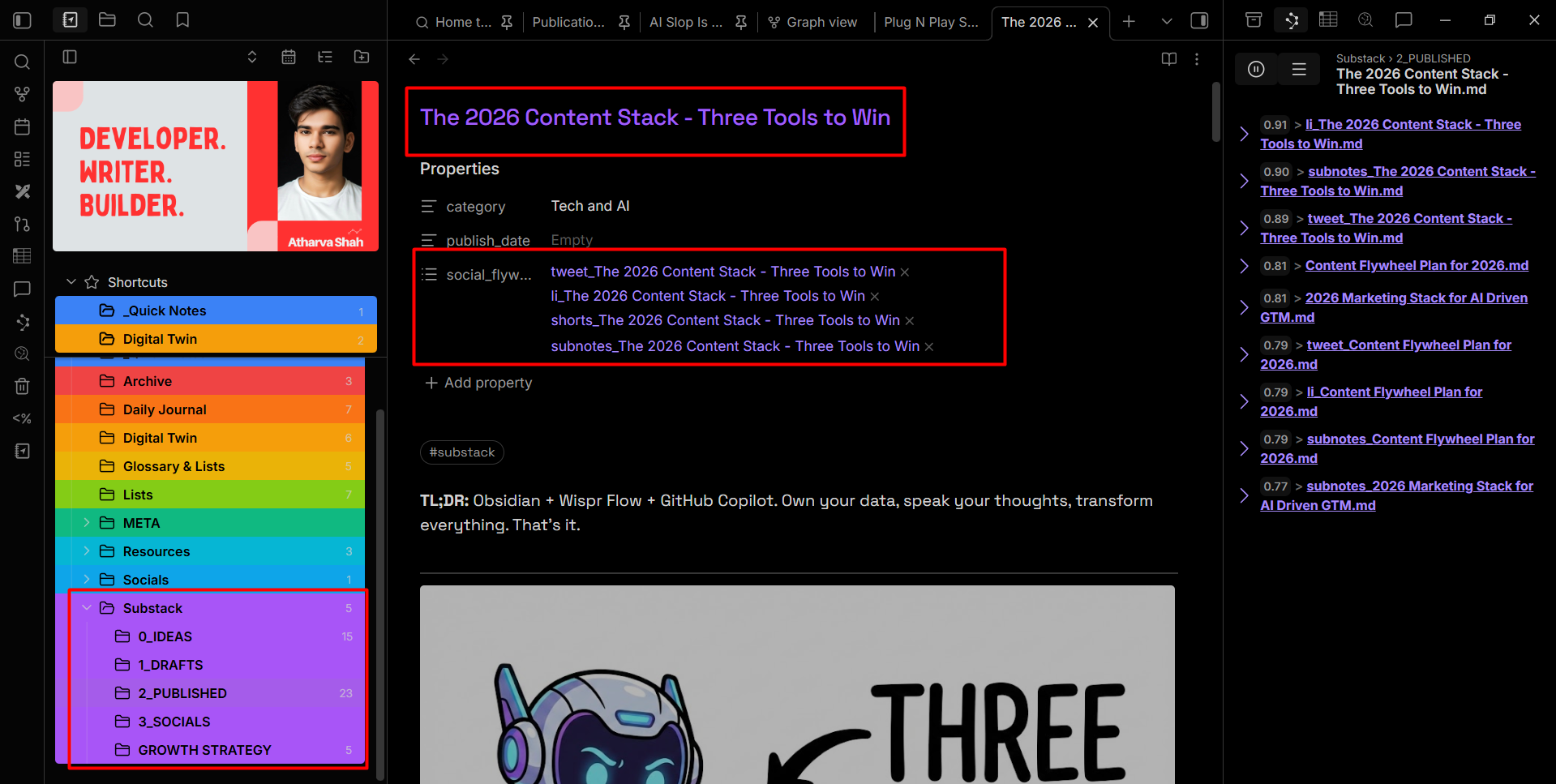
Content Flywheel Template against my blog yields 4x social links with those templates in place
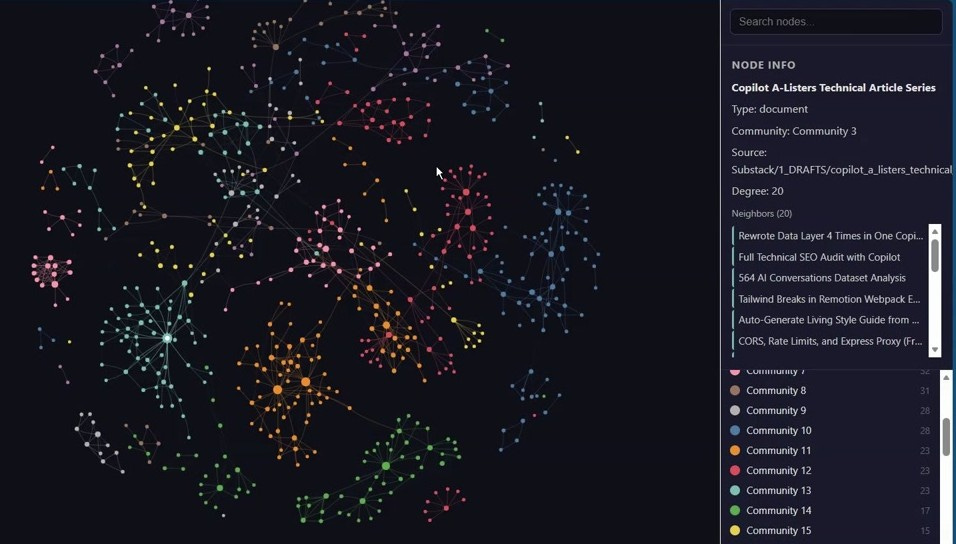
The Visualizations Show A Correlation Graph of All My Notes and Content Assets
Now here's where it gets powerful. I use Graphify to create a knowledge graph that auto-clusters my 2000+ files. The graph identifies patterns and trends. It correlates files you didn't consciously link.

Zoom in on any node and you see its full neighborhood. The info panel shows file type, community, source path, degree (number of connections), and every neighbor by name. A single article can have 20 direct connections spanning drafts, social posts, and related published pieces. Every arrow is a real connection. The more you write, the denser this map becomes.
I started this as an Obsidian project, but I use GitHub Copilot in VS Code now because the connection visualization is tighter and the file scanning is faster.
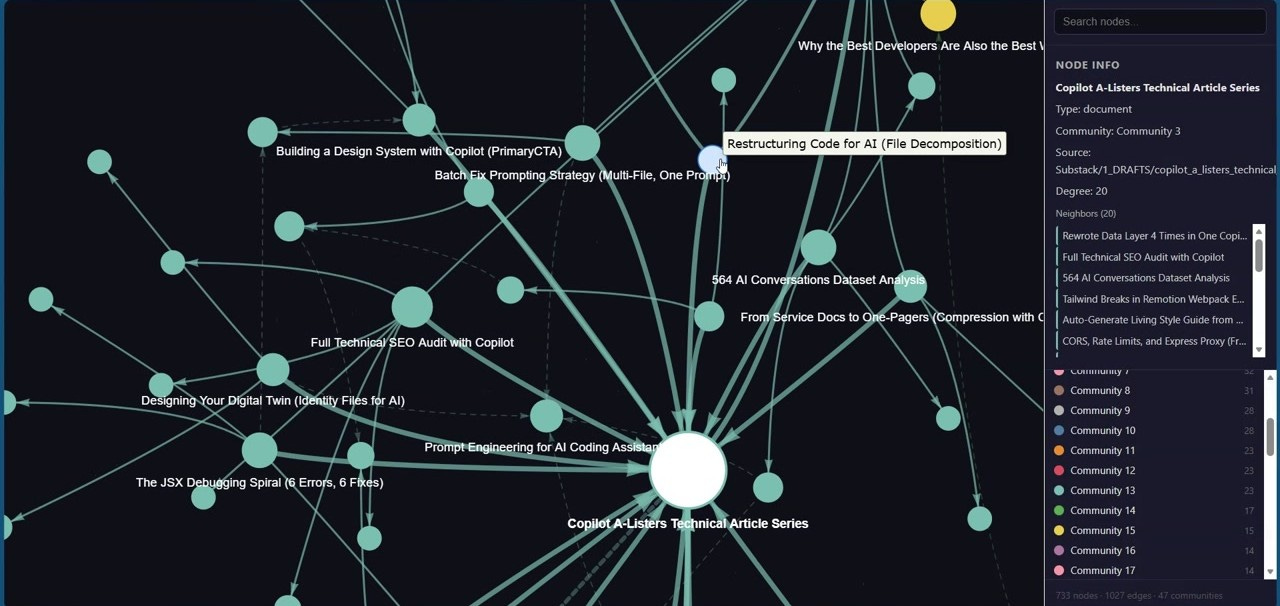
The structural breakdown:
Mission Control (Root) — Navigation and config
Capture (INBOX) — Active scratch space
Chronology (DAILY) — Permanent timeline of what happened
Grounding (DIGITAL TWIN) — Voice, audience, experience, goals (read before generating AI content)
Publishing Spine (SUBSTACK) — Ideas → Drafts → Published
Distribution (SOCIALS) — LinkedIn, Twitter, Substack Notes, Shorts
Durable Knowledge (LIBRARY) — Glossary, lists, resources, PDFs
Infrastructure (META) — Templates, Copilot memory, Excalidraw, graphify
Each has rules. Drafts are rough; published pieces are final. Library is stable; Meta supports. INBOX stays temporary. This prevents chaos and stagnation.
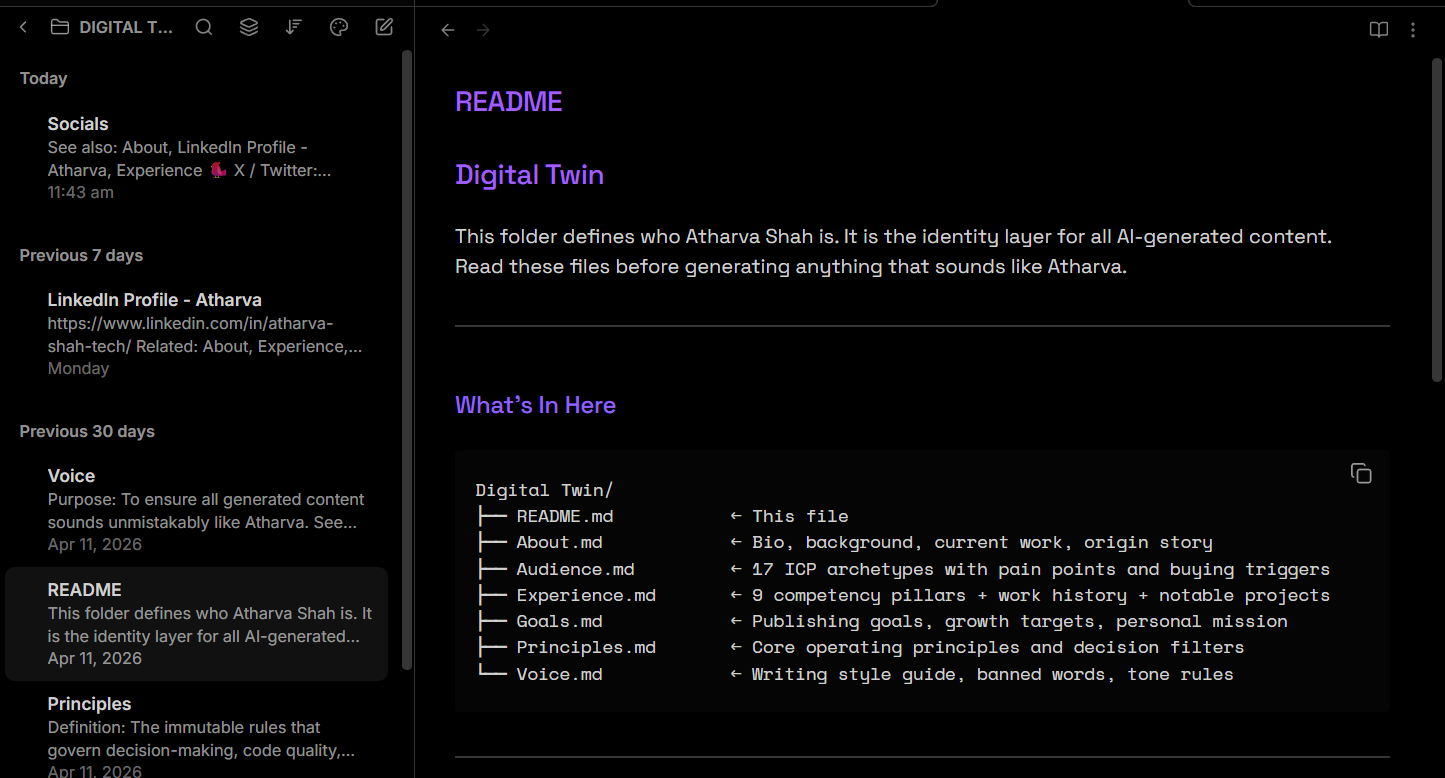
The Grounding Layer Is My Digital Twin Folder
Most AI outputs sound generic because the AI doesn’t know what you sound like.
I have a DIGITAL TWIN folder with:
voice.md — Writing style, banned words, sentence rhythm, what constitutes slop
audience.md — 17 archetypes with pain points and buying triggers
experience.md — 9 competency pillars
goals.md — What I’m shipping, in progress, unchecked
principles.md — Values and decision filters
When an agent generates a blog post in “my voice,” it reads voice.md first. When it suggests a content angle, it checks audience.md and experience.md.
The identity lives in files, not in prompt memory. That’s why outputs don’t feel like they were generated.
Bringing In The AI Automation Layer With Github Copilot
The vault isn’t passive. It’s programmable. Four components:
Grounding (DIGITAL TWIN) — Voice, audience, experience, goals, principles
Infrastructure (META) — Attachments, clippings, Copilot memory, templates, graphify
Workflow engine (.claude) — Agents for orchestration, skills for transformations
Editor behavior (.obsidian, .vscode) — Plugin behavior, MCP setup, workspace settings
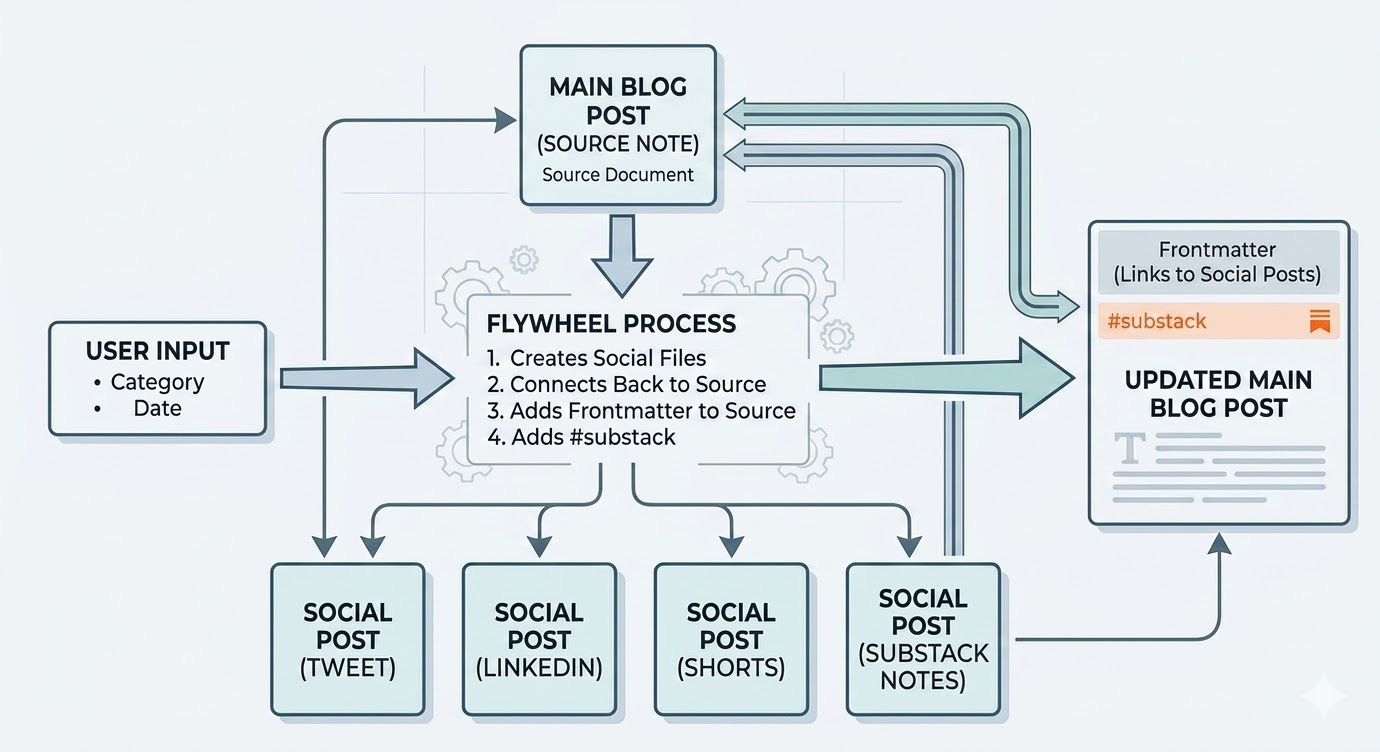
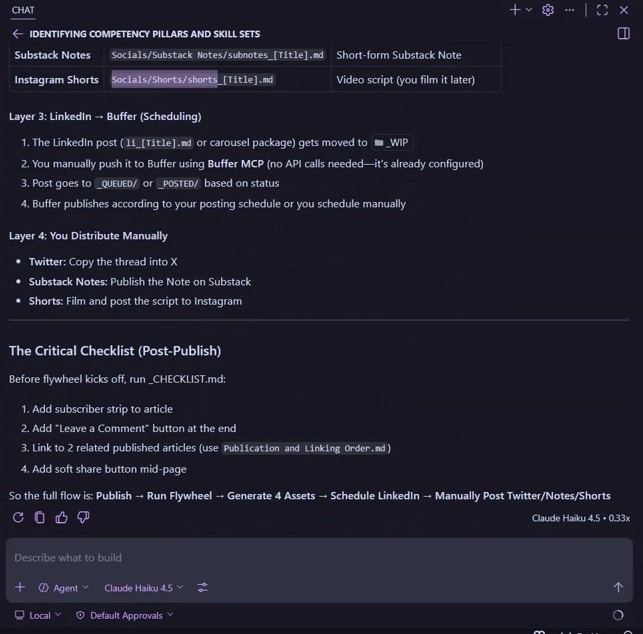
The Social Flywheel
When I publish a Substack article, one piece of content automatically becomes:
A tweet thread
A LinkedIn carousel post
A Substack Note
A video script
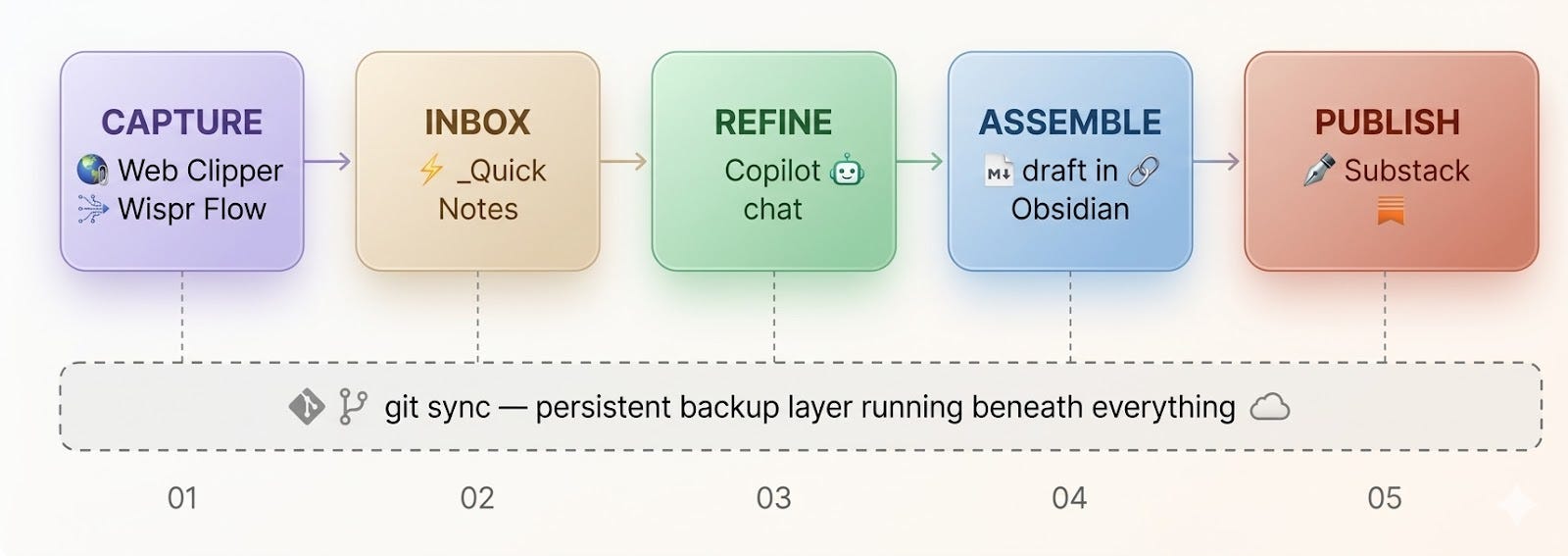
The critical principle here is don’t over-folder. If you bury ideas three directories deep, they die in silence. Instead I use Maps of Content - plain notes that act as hubs, listing links to other notes on a topic. They’re like a table of contents you build as you go, and they flex as your thinking evolves. Folders are rigid. MOCs are alive.
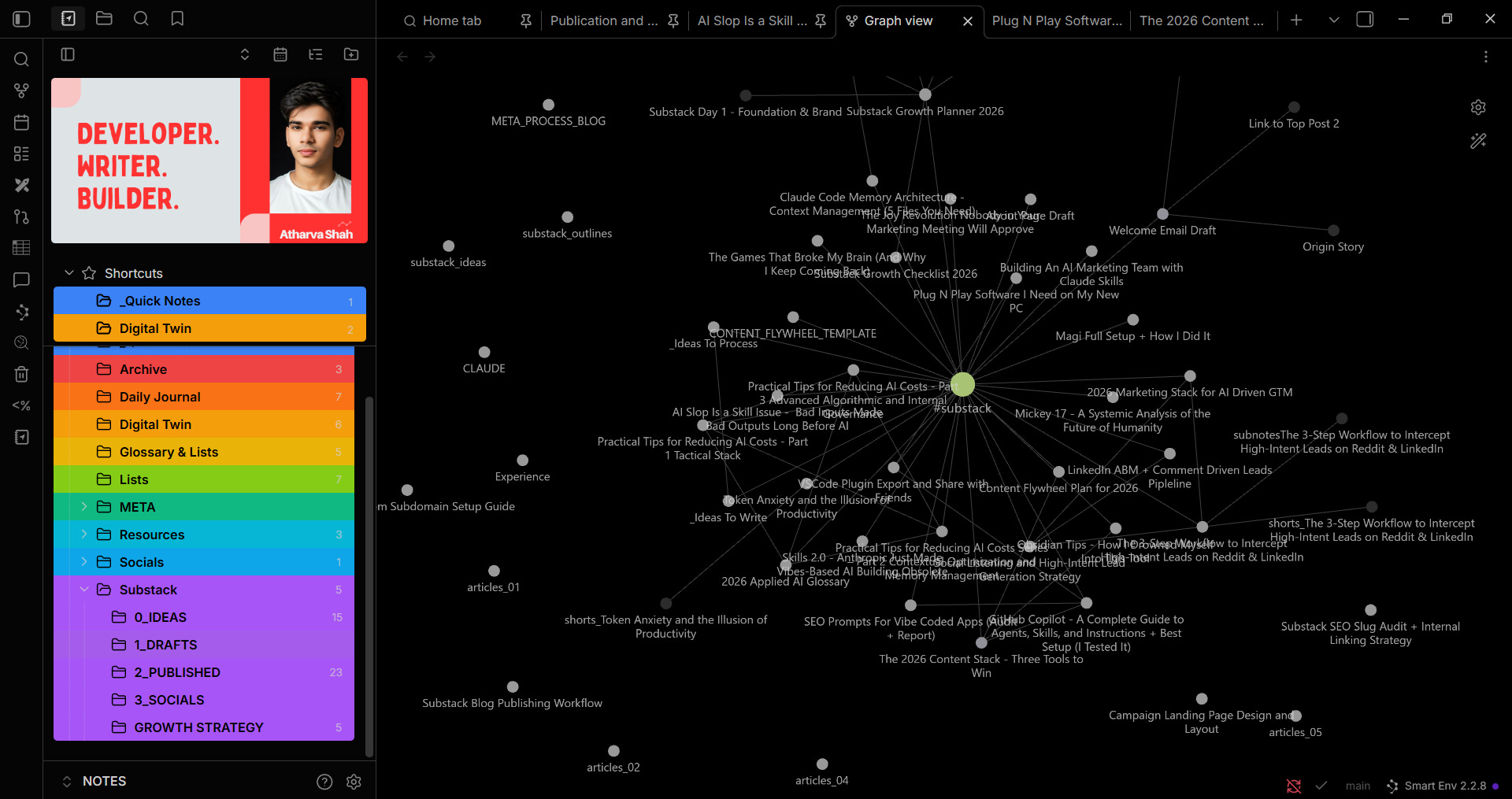
Then Daily Journal for chronological anchoring - one file per day, auto-generated.
Live Demos of What My Vault Can Actually Do
Query 1: What are my competency pillars?
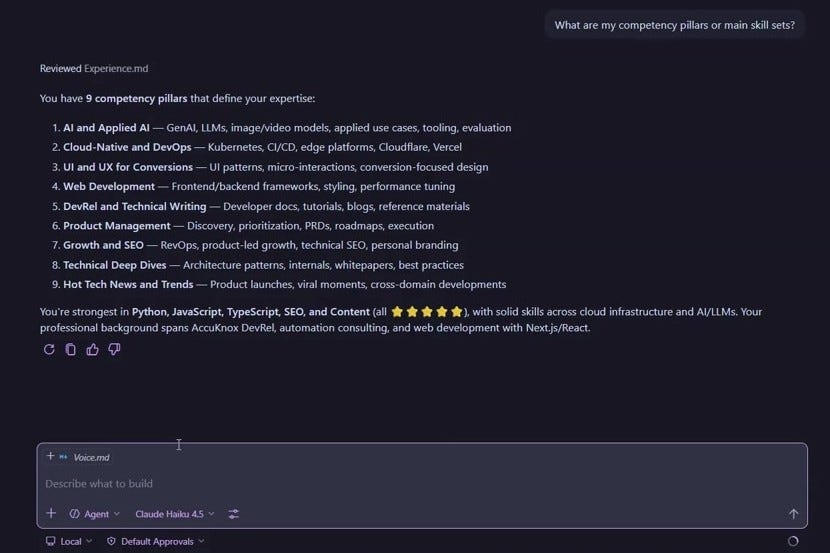
The AI doesn't search 2000 files. It reads experience.md and answers in seconds.
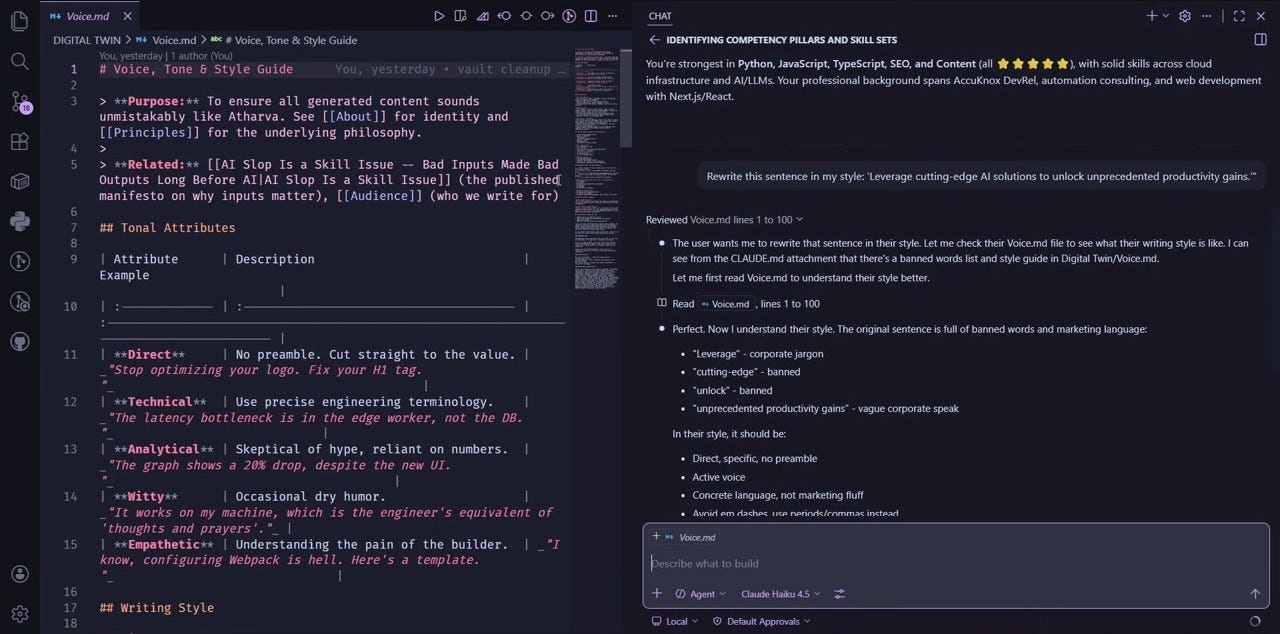
Query 2: Rewrite a sentence in my voice
It reads voice.md, spots banned words (”leverage,” “cutting-edge,” “unlock”), explains why they fail, rewrites direct and specific.
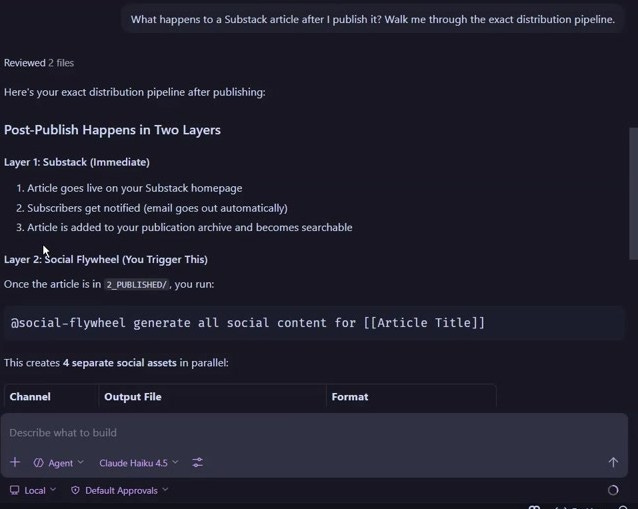
Query 3: What happens after I publish a Substack article?
Layer 1: The article goes live, subscribers get notified. Layer 2: Run the flywheel agent, get 4 social assets in parallel.
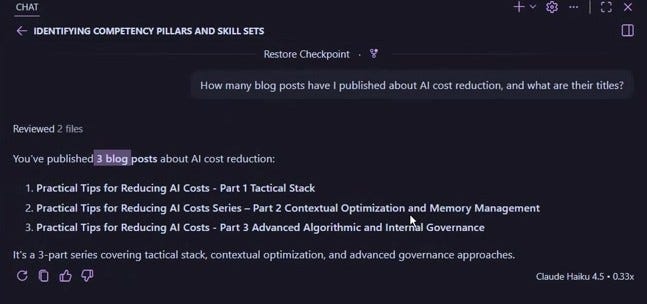
Query 4: How many blog posts about AI cost reduction?
It checks the published folder, scans for relevant files, returns titles. No hallucination.
Query 5: What was I supposed to finish in Q1?
It reads goals.md and cross-references project files. Shows what shipped, what’s in progress, what stalled.
Beyond the Basics: Advanced Workflows
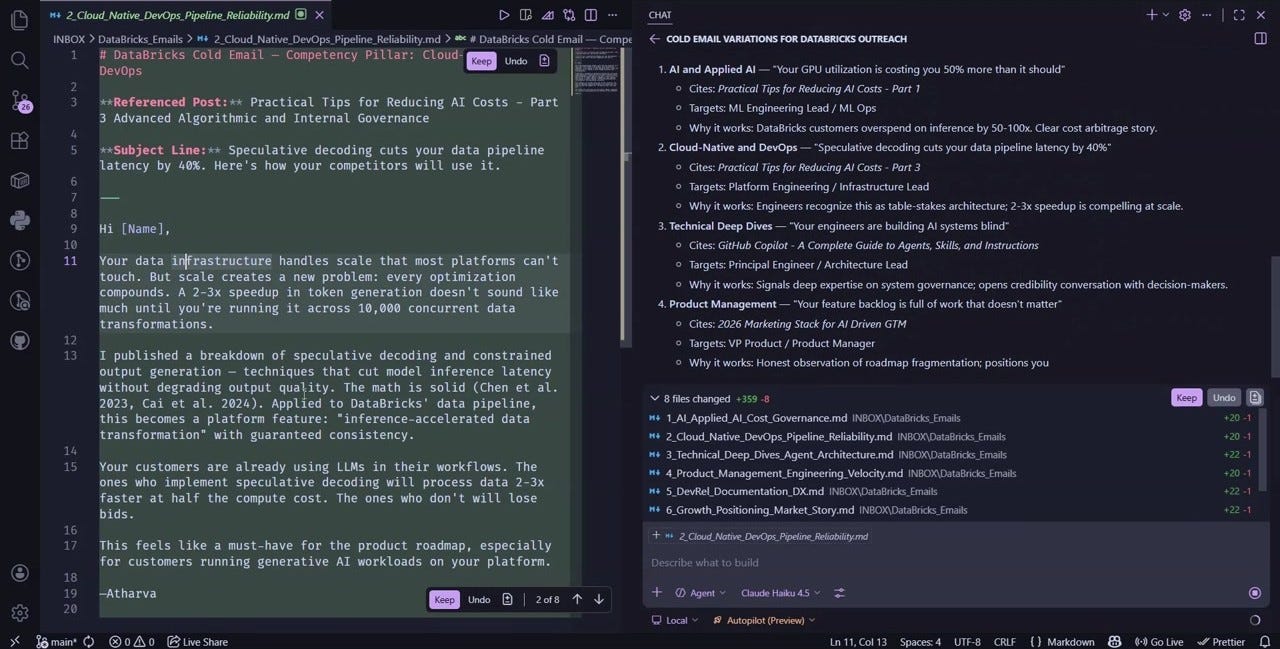
Workflow: The Social Flywheel in Action
Once an article publishes, the flywheel runs automatically. The dashboard shows each article and its downstream social outputs in real time. No manual steps. No forgotten platforms.
Workflow: Graph-Driven Ideation
When I’m stuck on what to write next, I zoom into the graph. A single article node connects to research notes, related pieces, audience archetype files, and competitive analysis. The system shows me what I’ve already built nearby. I don’t start from zero.
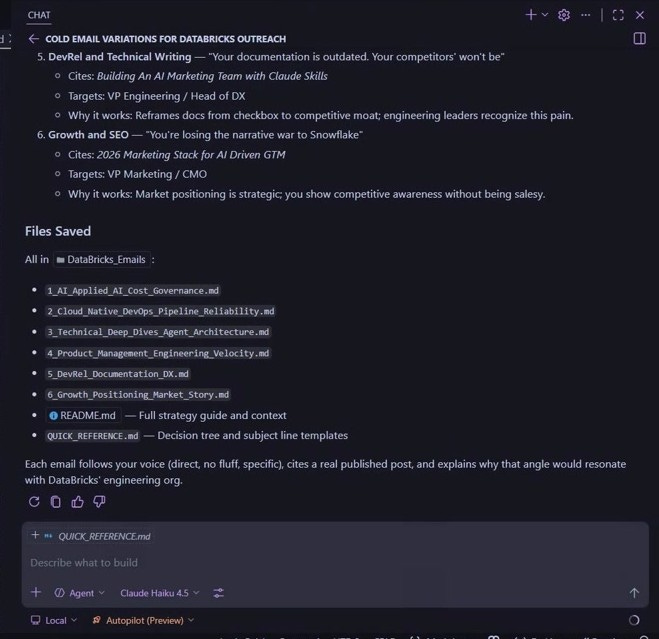
Workflow: The Content Velocity Dashboard
The metrics dashboard tracks what the system actually generates. Not time spent or tasks completed. Outputs. Monthly velocity is stable. The system compounds.
Final Thoughts
I don’t sit down and “write.” I capture, structure, refine, and distribute. The system knows who I am before it touches a keyboard. Every output filters through my voice, my audience, my competencies.
The deeper you build it, the more it knows you. The more it knows you, the faster you work.
Plain text doesn’t lock you in. Open it in Notepad 30 years from now on any OS and it still works. Try that with Notion.
The Graph View revealed patterns I didn’t make consciously. I linked a cold email note to a content flywheel note, and the graph showed they both connected to an audience psychology note I’d written weeks before. That emergent structure doesn’t happen in tools where notes live isolated.
Everything in one place. Code, long-form, checklists, diagrams, journal entries, plans. One vault. One search. One backup. The cognitive overhead of “where does this go” drops to zero.
I invested heavily in this infrastructure. I’m not abandoning it.