

I Got an AI to Audit, Group, Caption, and Arrange 585 Photos for Instagram - Entirely Locally, Entirely Mine
A private, reproducible AI pipeline for photo curation, captioning, music tagging, and folder export. No cloud uploads. No subscriptions.


“I have 585 photos. They’re beautiful. They’re chaos. I want them to become 62 Instagram posts.”
One conversation later, I had exactly that. A local Python script, a Markdown file, and a six-phase workflow that became the source of truth for an entire year of my life in photos. No cloud uploads. No tagging API. No subscriptions.
The Problem Nobody Talks About
You have a folder. Maybe several. Files named IMG_20241103_182344.jpg stacked next to screenshot_edit_final_v3_REAL.png next to remini-enhanced-kgwv6b.jpg. You know the folder. Every photographer has The Folder.
The problem isn’t editing. Lightroom exists. The problem is curation at scale. It’s the cognitive overhead of:
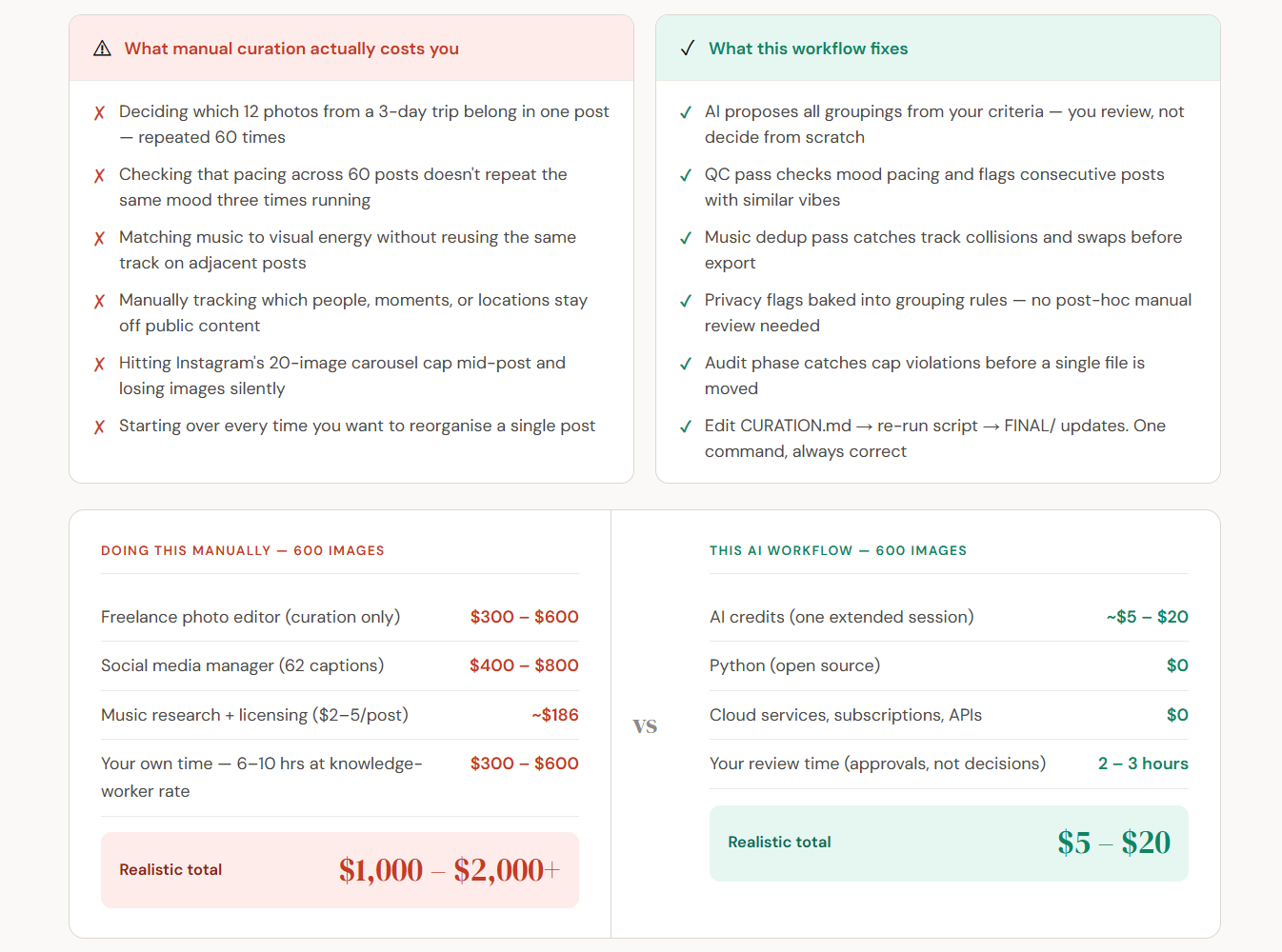
Deciding which 12 photos from a 3-day trip belong together
Making sure the pacing across 60 posts doesn’t repeat the same mood three times running
Matching music to visual energy without reusing the same track on adjacent posts
Keeping certain people, certain moments, certain locations off public-facing content
Actually getting a folder called
FINAL/that’s ready to drag into Buffer
AI closes that gap. If you know how to ask.
What I Actually Built
Over a single extended AI session, using only GitHub Copilot in VS Code and local Python 3, I went from a raw image dump to this.
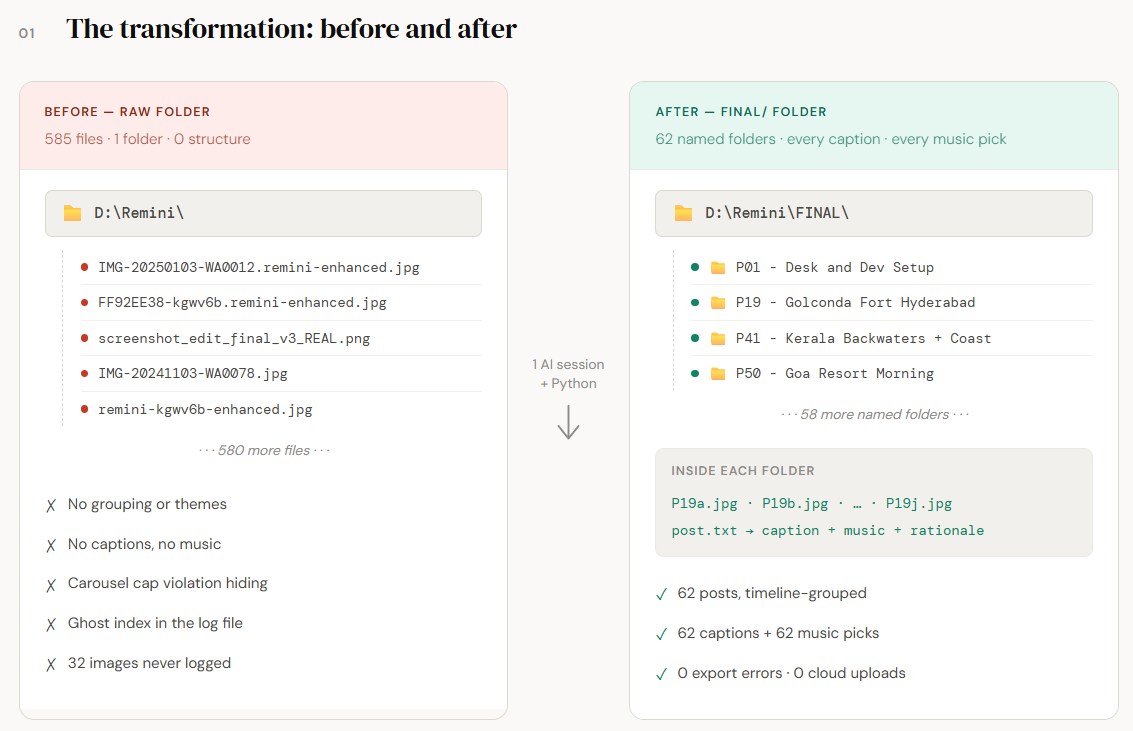
Everything happened locally. The AI never saw a pixel. It worked from filenames, descriptions I’d written in a log file, and my own curation criteria. My photos stayed on my machine the entire time.
Why This Is Different From Every Other “AI Photo Tool”

1. Nothing leaves your machine.
Every operation ran locally. Python read local files. The AI read filenames and text descriptions — not pixels. The export script copied files within the same machine. Zero cloud round-trips.
2. The AI works from your criteria, in your voice.
Standard AI photo tools auto-label “beach,” “portrait,” “food,” and hand you a folder of mislabeled false positives. This worked differently. The AI proposed groupings based on what you told it mattered. You reviewed every assignment before anything was finalized. The curation was yours.
3. The output is a first-class artifact.CURATION.md is not a temporary working file — it’s a permanent creative document. It contains every grouping decision, every caption, every music reasoning. Six months from now when you’re wondering why you put two images together, the rationale is there.
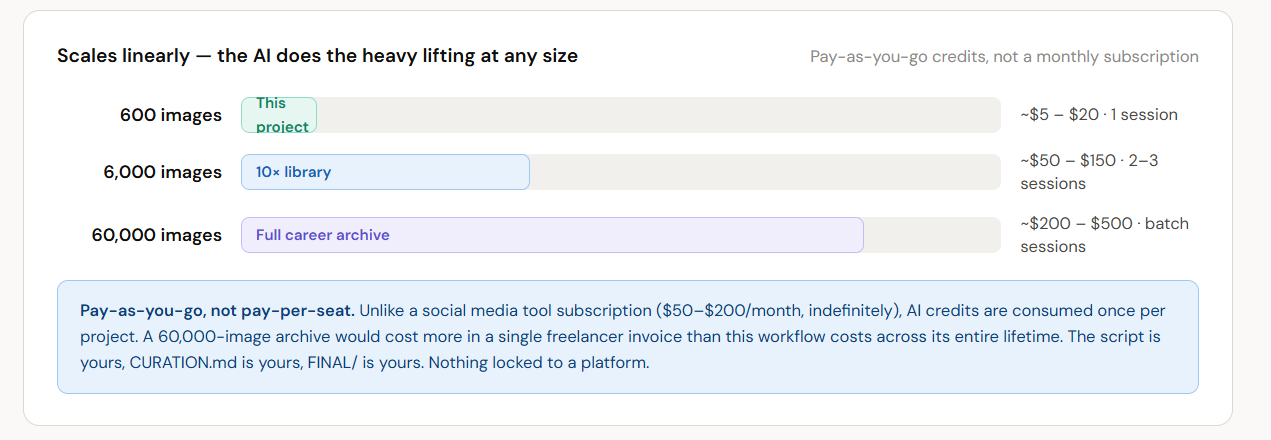
4. It scales.
The same workflow works for 100 images or 5,000. The export script handles filename chaos gracefully. CURATION.md can nest, extend, and reorganize. The QC pass scales with automated checks before the human visual review.
5. It’s yours to run again.
The next time I do a photo dump, I run the same prompt architecture. The script already handles all my filename variants. I update MANUAL_INDEX_TO_FILE for any new unlogged batch, update CURATION.md, and run export_final.py. The entire workflow is reproducible.
Who This Is For
If you have more than 50 photos you care about and no system for them, this is for you. Photographers, travelers, content creators, designers — the workflow doesn’t care. It also doesn’t care whether your target is Instagram, Substack, a portfolio, or a private archive. The structure holds.
The Input Prompt That Started Everything
Here’s the prompt architecture. Adapt it to your project:
I have [N] photos in [local folder path].
My goal: group them into [platform] posts for publishing over [timeframe].
Curation criteria:
- Timeline: roughly chronological, anchored to real events/trips
- Location: photos from the same place should travel together
- Vibe / mood: visual tone should be internally consistent per post
- People: flag posts that include [specific people] so I can decide on privacy
- Quality gate: no blurry, test shots, or obvious duplicates in any post
I have [an existing metadata log / no log — build one].
My image folder is [path]. Compressed derivatives live at [path].
My music taste: [genres, artists, references].
Deliverables I want:
1. A CURATION.md with all posts, image assignments, captions, music picks
2. A Python export script that builds a FINAL/ folder from CURATION.md
3. A post.txt inside each FINAL folder with caption + music ready to paste
4. An audit flag if any post breaks the [platform] image cap
Privacy requirement: all processing must be local. No uploads.
The Six-Phase Workflow
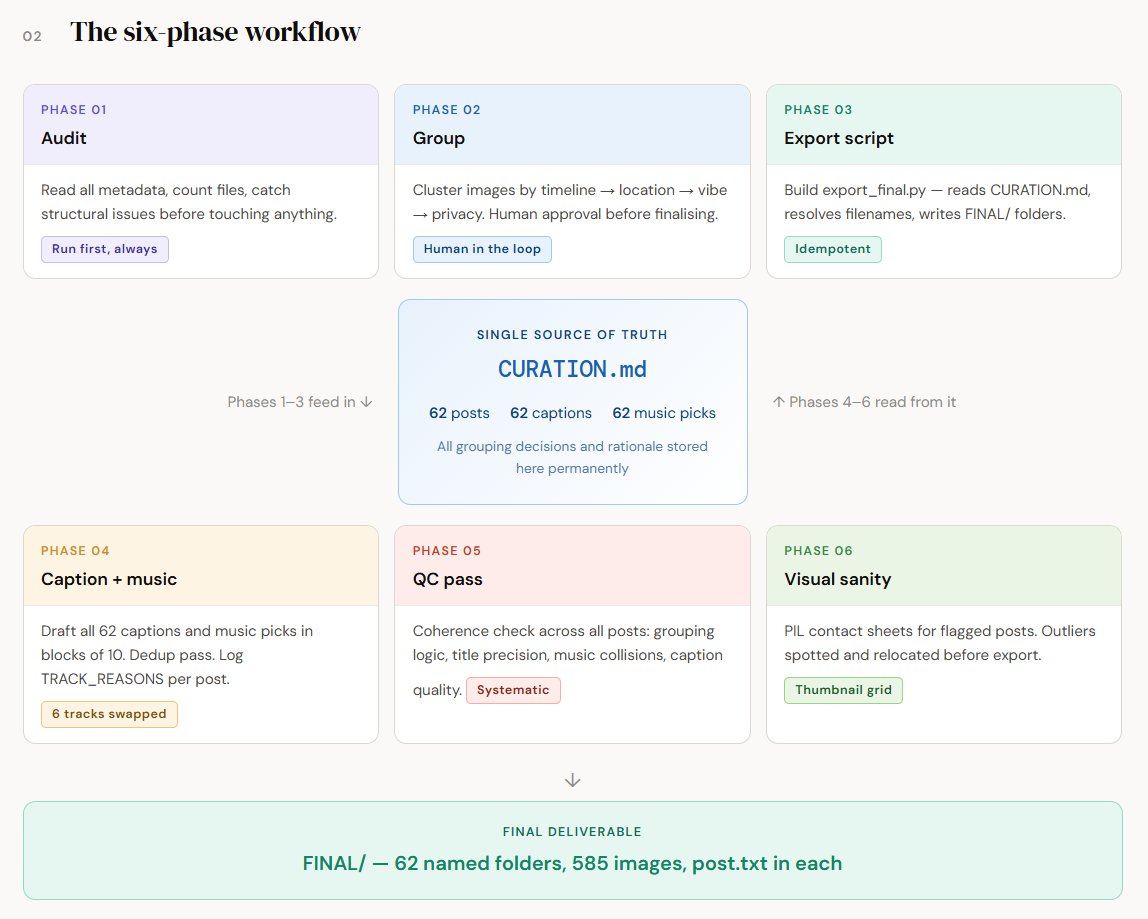
Phase 1 — Audit & Inventory (Don’t Skip This)
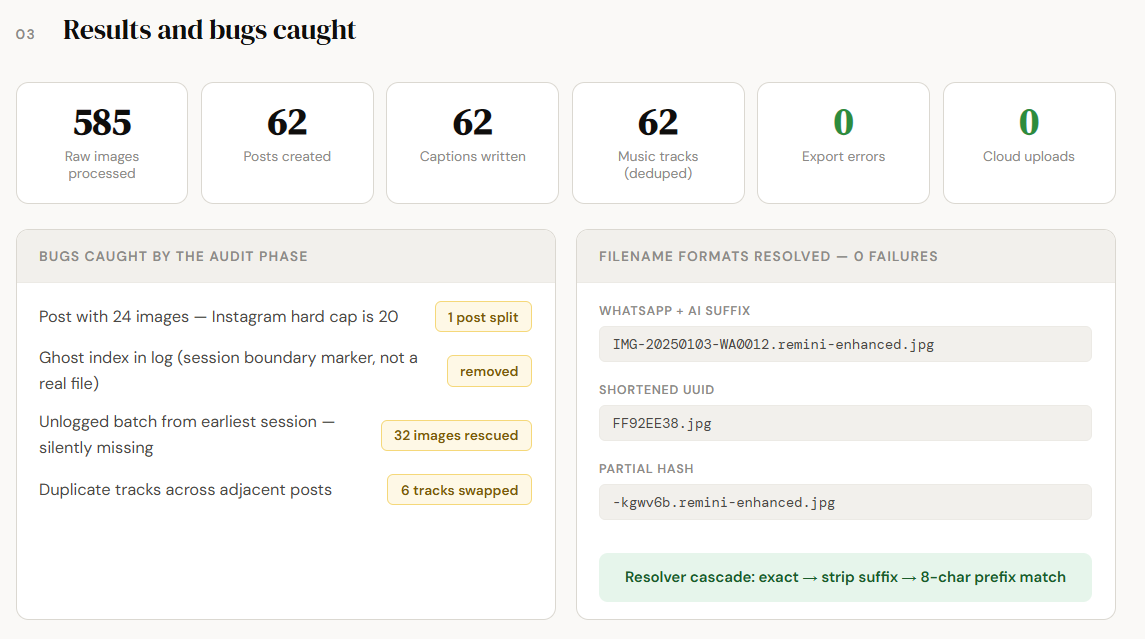
The AI didn’t start with grouping. It read the existing metadata, counted files, and ran a structural audit first.
What it found:
One post had 24 images — Instagram’s hard cap is 20. It got split into two posts.
Index 208 in my image log was a session boundary marker, not a real image. It had been silently included in a post assignment.
32 images from my oldest batch had never been individually logged.
This audit phase saved me from shipping a broken export. The Instagram carousel would have silently dropped 4 images. The ghost index would have caused a file-not-found error at export time. Neither of these would have announced themselves without a deliberate check.
Lesson: Ask the AI to audit before it does anything else. “Read what I have, count what’s there, and tell me what’s broken” is worth doing first.

Phase 2 — Grouping by Timeline + Location + Vibe
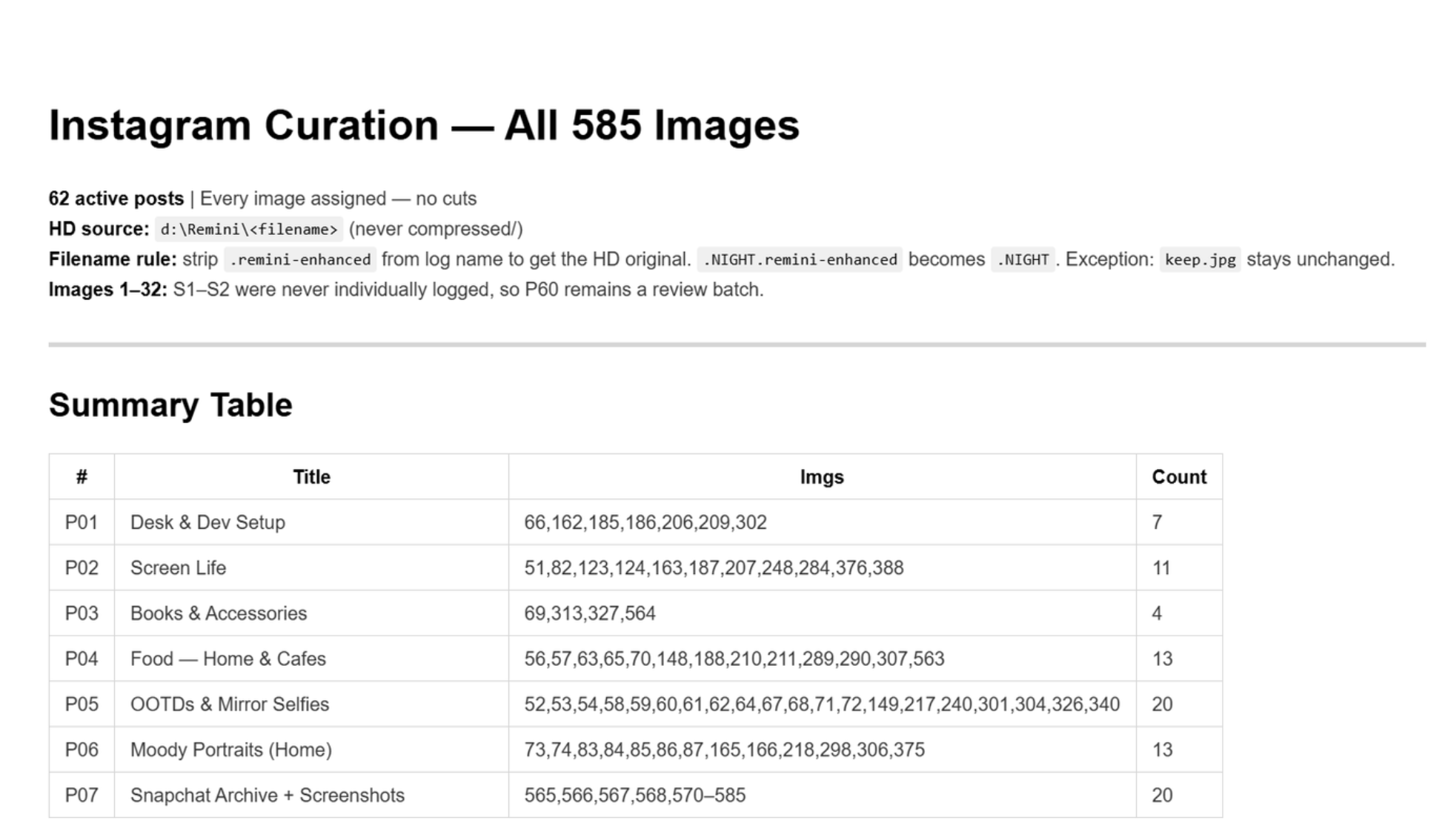
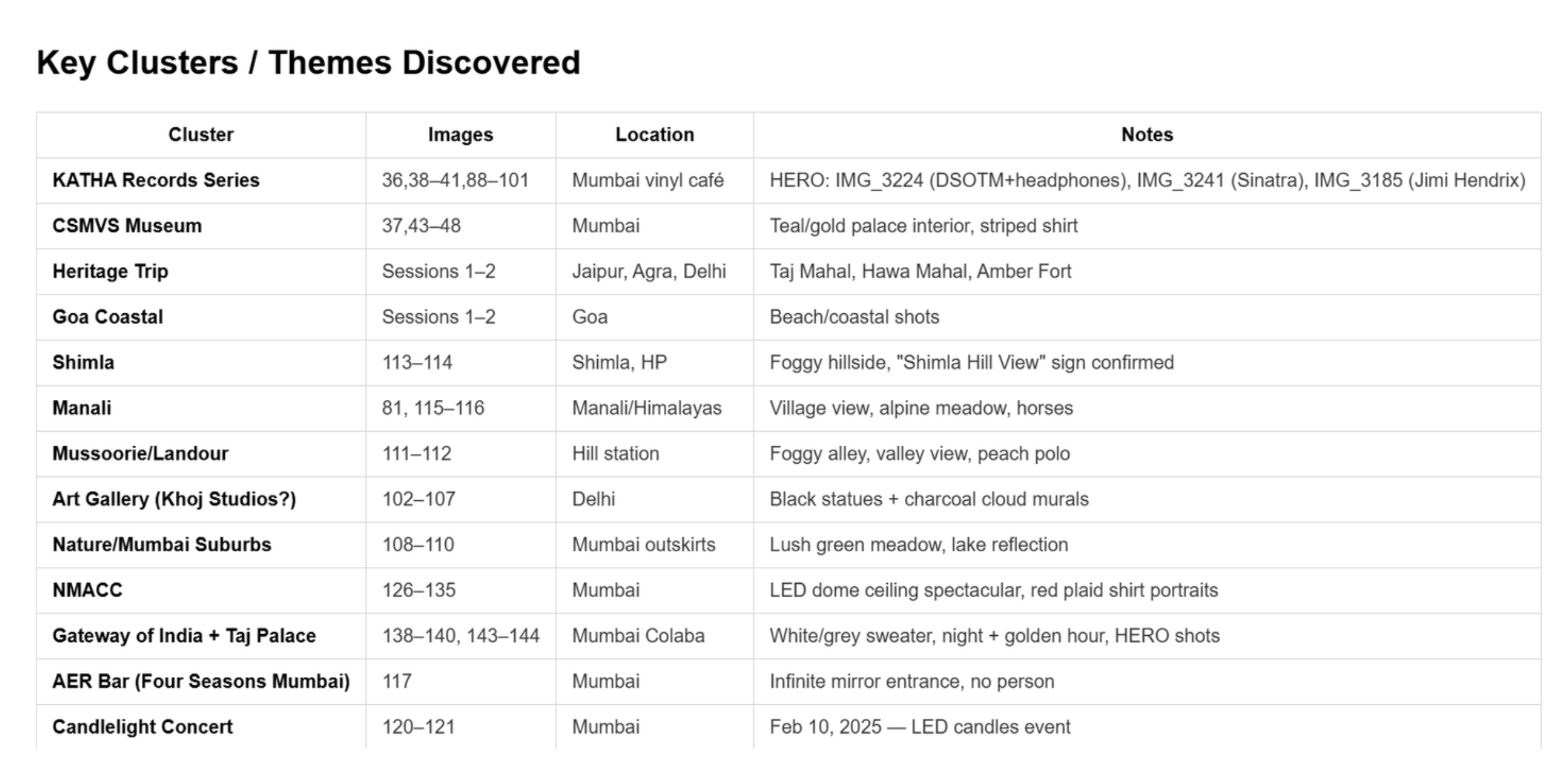
585 images. 18 months. The grouping pass was the hardest part. The criteria:
Timeline first: photos cluster naturally by trip or life phase
Location within timeline: a Mumbai weekend and a Goa weekend happen at similar times but look completely different — they need separate posts
Vibe as a tiebreaker: if two sets of images are from the same location but one is golden-hour outdoor and one is nightlife indoor, they go in different posts
People as a privacy gate: images with certain people were explicitly flagged for my review before being assigned to public posts
The AI proposed 60 posts initially. After the audit, that became 62 (two splits, plus resolving a 32-image unlogged batch into two dedicated archive posts).
Each post got a name. Not a filename. A name. P41 — Kerala — Backwaters + Garage Café + Coast. That level of specificity came from going back and forth on titles until they reflected what was actually in the frame, not what I wished was in the frame.


Phase 3 — Building the Export Script
This is what made everything reusable. export_final.py is a Python script that:
Reads
CURATION.mdas the source of truthParses the image index list for each post
Resolves each index to the actual filename on disk (handling AI-enhanced variants, shortened UUIDs, WhatsApp-formatted names)
Copies the HD original into
FINAL/<PostID> - <Title>/P01a.jpg, P01b.jpg...Writes a
post.txtalongside the images with caption, music, and rationaleOutputs an
_EXPORT_REPORT.md— a full accounting of every post, file count, and any resolution errors
The resolver was the interesting part. My filenames came in three formats:
IMG-20250103-WA0012.remini-enhanced.jpg— full WhatsApp name + AI suffixFF92EE38.jpg— shortened UUID from a different app-kgwv6b.remini-enhanced.jpg— partial hash format
The resolver cascades: exact match → strip .remini-enhanced suffix → match on first 8 characters as prefix. Zero images failed to resolve.
Why this matters: The export script is idempotent. Every run wipes FINAL/ and rebuilds from CURATION.md. This means:
Edit a caption in
CURATION.md→ run the script → the change is live in FINAL/Move an image to a different post → run the script → the folders reflect it instantly
CURATION.mdis always correct.FINAL/is always a derived artifact.
Phase 4 — Captions & Music
The caption philosophy:
Terse and atmospheric for travel/landscape posts — no need to explain the Taj Mahal
Warmer and more personal for portrait or home posts
No hashtag spam in the draft — that’s a posting-time decision
Captions should add something the image doesn’t already say
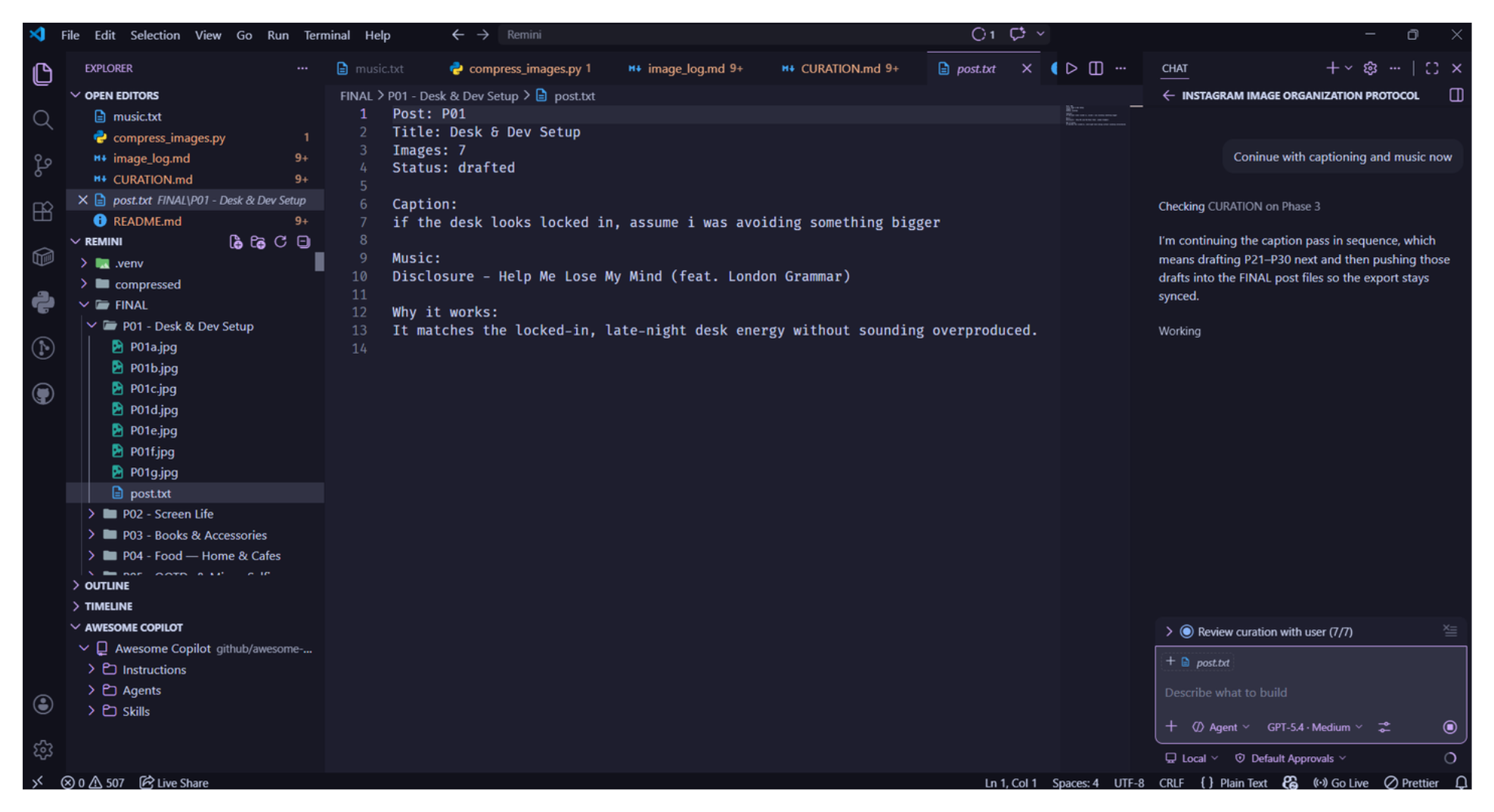
The music philosophy:
Each track’s mood should amplify the visual mood, not fight it
Varied enough that consecutive posts don’t feel like the same playlist
Personal enough to express something — no generic “lo-fi beats”
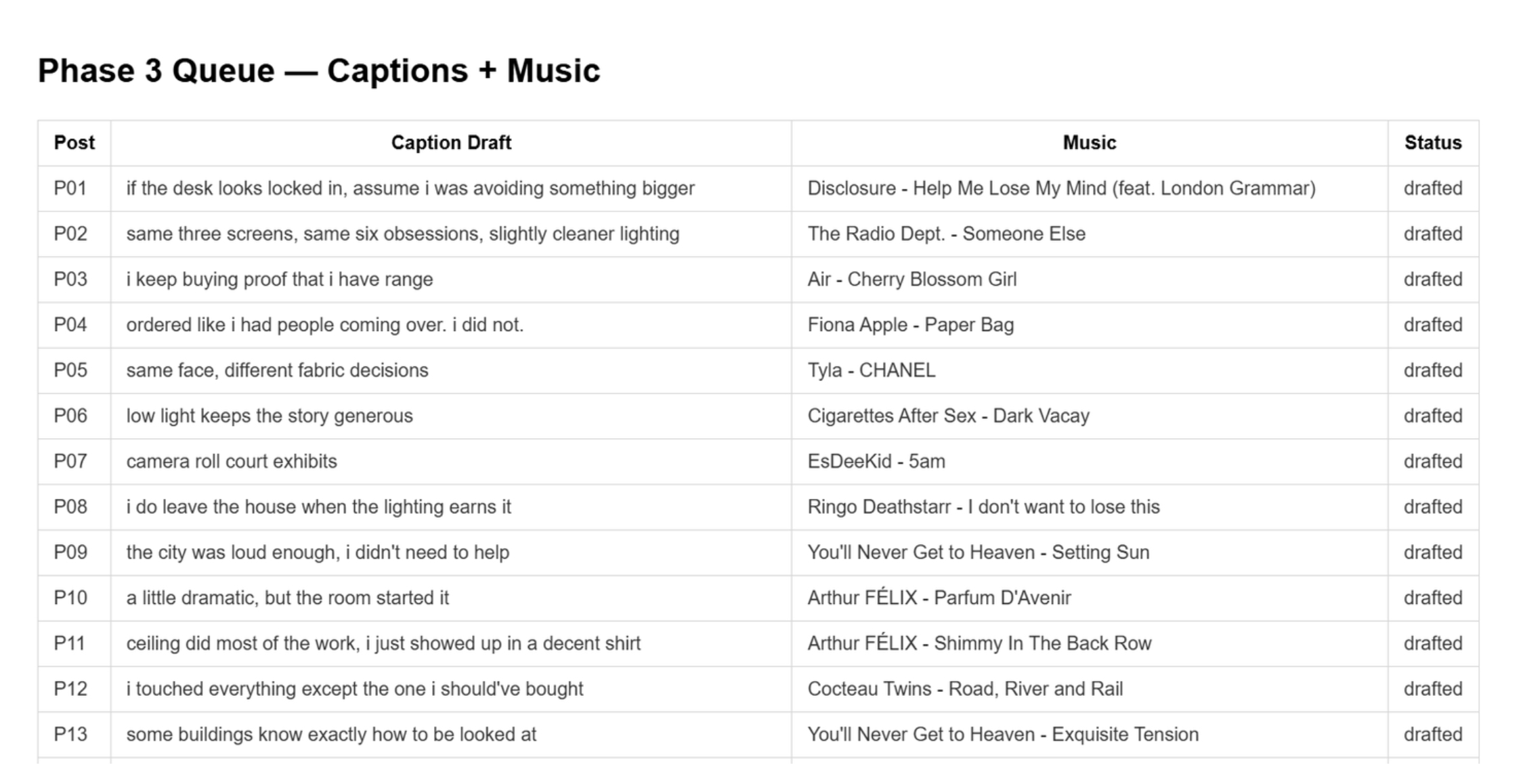
After all 62 posts were drafted, the AI ran a deduplication check. It found:
One track assigned to 3 different posts
Several tracks appearing twice on posts that were adjacent or thematically similar
Six swaps were made. Each replacement was a deliberate match — not just “anything else.”
A TRACK_REASONS dictionary was written into the export script for every post, explaining why the music works. This becomes a useful memory artifact: when you’re posting months later and you’ve forgotten the session, the rationale is right there.
Phase 5 — The QC Pass
Before calling the project done, we ran a coherence check. This covered:
Grouping coherence: does every image in a post have a through-line — visual, narrative, or emotional?
Title precision: does the title name what’s actually in the post, or just where you were?
Music deduplication: already handled in Phase 4, but confirmed clean
Caption quality: are there any captions that are too generic, too try-hard, or that over-explain?
One title fix came out of this: P41 — Kerala became P41 — Kerala — Backwaters + Garage Café + Coast because the images were three genuinely different subjects. The vague title would have been misleading both to viewers and to me looking at my own archive later.
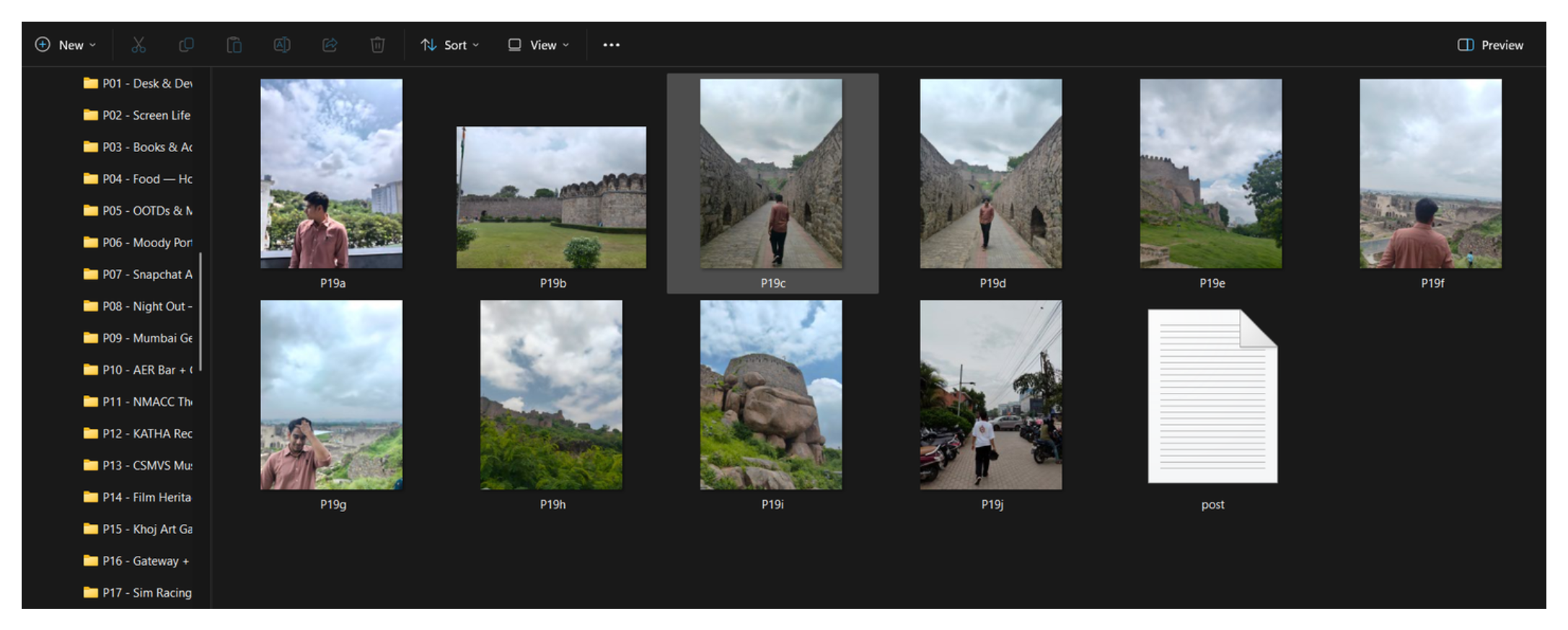
Phase 6 — Visual Sanity Check
The final step was visual. My eyes, but with AI-generated contact sheets.
For the two most uncertain posts, P60 (Early Heritage & Portrait Archive) and P62 (Early Interiors, Culture & Misc Vibes), we generated PIL contact sheets: a grid of all images in the post rendered at thumbnail size.
from PIL import Image
import os, math
def make_contact_sheet(folder, output_path, thumb_size=(300, 300), cols=5):
files = sorted([f for f in os.listdir(folder) if f.lower().endswith(('.jpg','.jpeg','.png'))])
imgs = [Image.open(os.path.join(folder, f)).convert('RGB') for f in files]
thumbs = [i.copy() for i in imgs]
for t in thumbs: t.thumbnail(thumb_size)
rows = math.ceil(len(thumbs) / cols)
w, h = thumb_size
sheet = Image.new('RGB', (cols * w, rows * h), (30, 30, 30))
for idx, t in enumerate(thumbs):
x, y = (idx % cols) * w, (idx // cols) * h
sheet.paste(t, (x, y))
sheet.save(output_path)
Within seconds of viewing the contact sheet, two images jumped out as visually incoherent with the rest of P60. A white fabric close-up and a lakefront scene had snuck in alongside Jantar Mantar stonework and Mughal architectural portraits. They were moved to P62, which had a looser, more eclectic brief anyway.
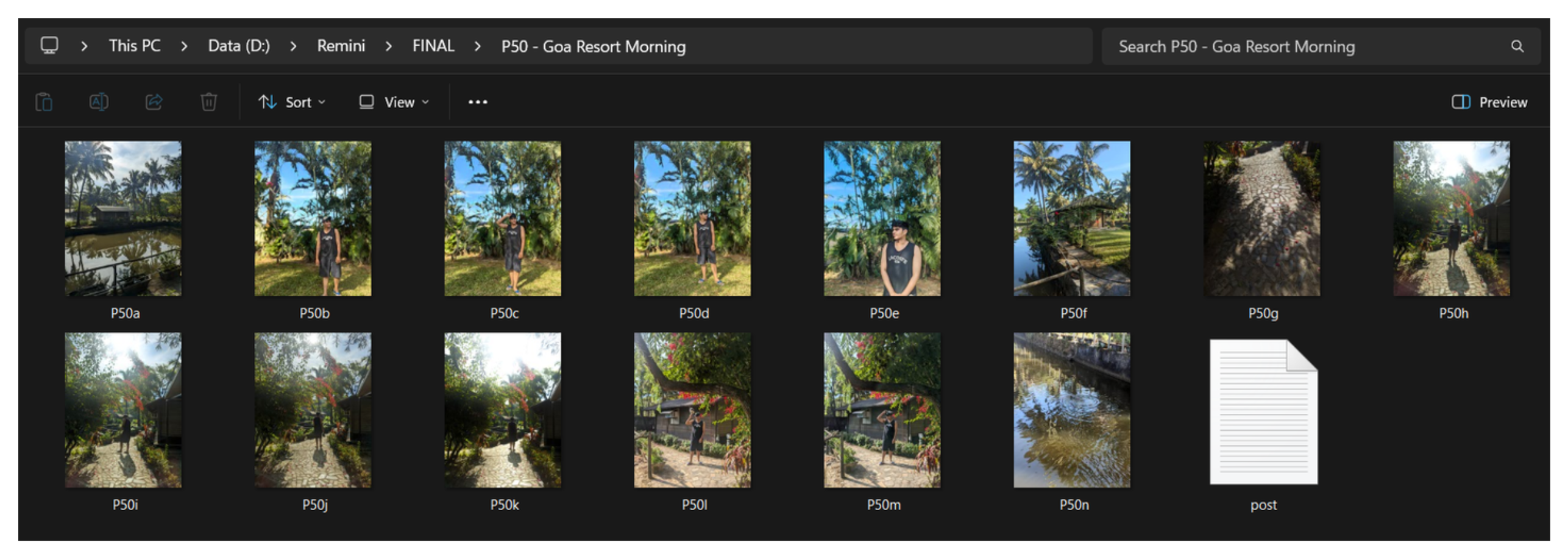
That’s the power of visual review at thumbnail scale: patterns that don’t show up in a filename list become instantly obvious in a grid.
The Final Numbers
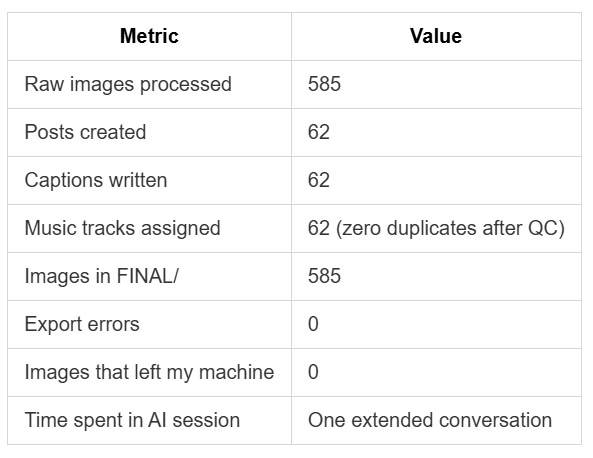
Take It With You
I’ve packaged the entire workflow into a SKILL.md, a structured instruction set that any AI assistant supporting the VS Code Copilot skill format can invoke. It contains the six-phase workflow, the CURATION.md schema, the export script skeleton, and documented fixes for every common failure point.
Drop it into your VS Code setup. Point it at your folder. One conversation.
Run It Yourself
Here’s the full starter prompt:
I have [N] photos in [local folder path].
My target platform is [Instagram / Substack / portfolio / personal archive].
Curation criteria:
- Timeline: [yes/no, describe the date range]
- Location: [yes/no, describe the geography]
- Vibe/mood: [describe your visual style — e.g., "film grain, golden hour, blue interiors"]
- People: [flag posts with [names] for my privacy review]
I have [an existing metadata log at path / no log — build one from filenames].
Compressed derivatives are at [path / same folder].
Music: I like [genre / artists / specific tracks file at path].
Please:
1. Audit: count files, find cap violations, flag ghost indices
2. Group: propose posts with names, index assignments, and image counts
3. Export: write export_final.py that builds FINAL/ from CURATION.md
4. Caption + Music: draft all posts, log TRACK_REASONS
5. QC: flag music collisions, title vagueness, grouping incoherence
6. Visual: generate PIL contact sheets for any flagged posts
All processing must be local. No uploads.
That’s the full cycle.
Atharva Shah builds AI tools and workflows. This project was built entirely locally using GitHub Copilot in VS Code. If you want the SKILL.md file or want to adapt this workflow for your own image library, reach out.
