Lessons From Data Engineering @AccuKnox and Elantis
A compilation of 3 projects showcasing business use case, an architecture diagram, a tech stack, a setup guide, a step-by-step flow with real code, production challenges

I have been deeply embedded in data engineering at multiple organizations; this is a summary of the top projects I have been involved in and my takeaways and future notes from it.
Project 1, AI-enriched data pipeline on Databricks (Elantis.AI). AI-flavored.
Project 2, AI-powered RAG pipeline for GTM intelligence (AccuKnox). AI-flavored.
Project 3, Modern data stack RevOps pipeline (AccuKnox). Pure data engineering.
Project 1, AI-Enriched Data Pipeline on Databricks @Elantis
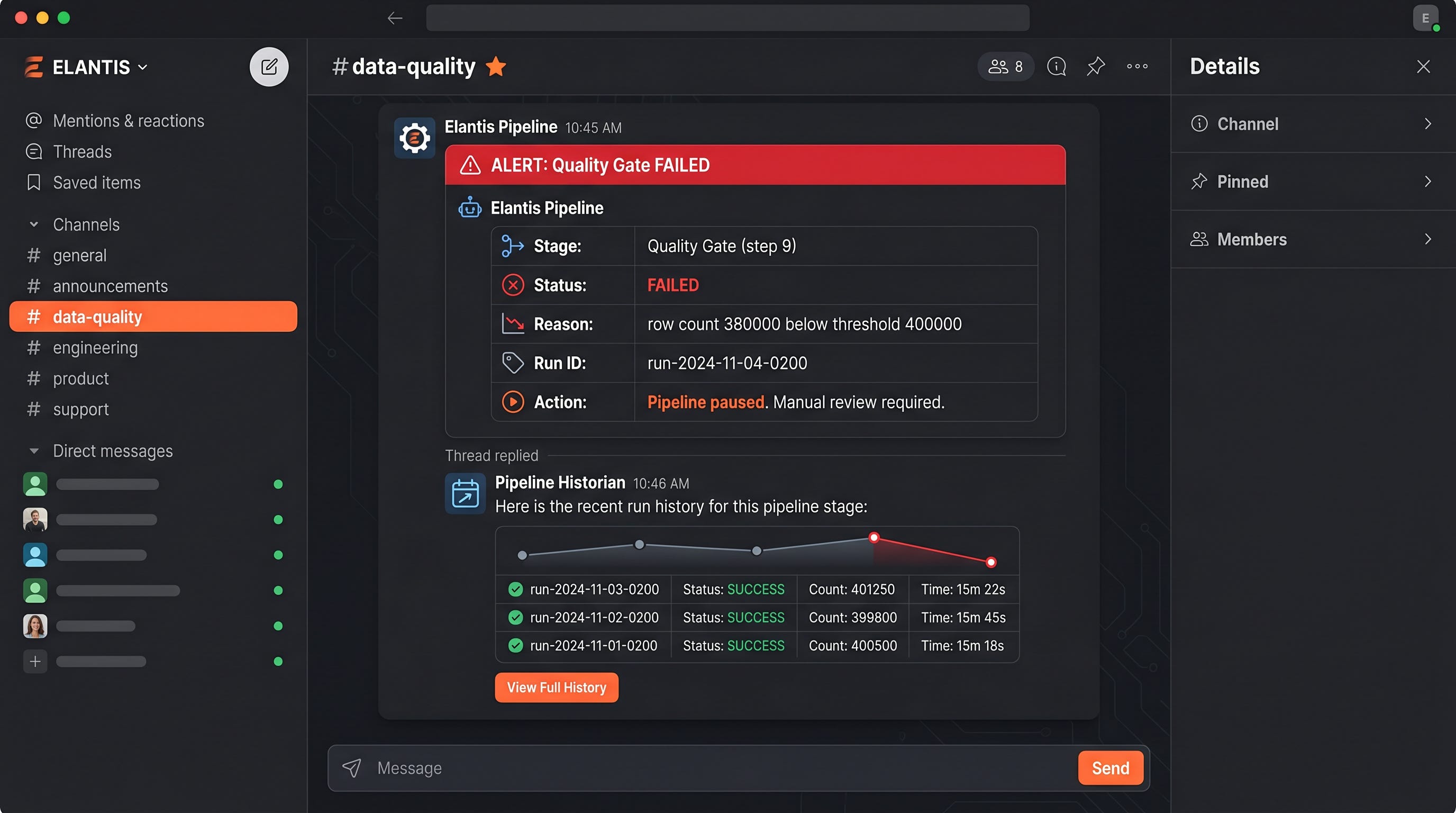
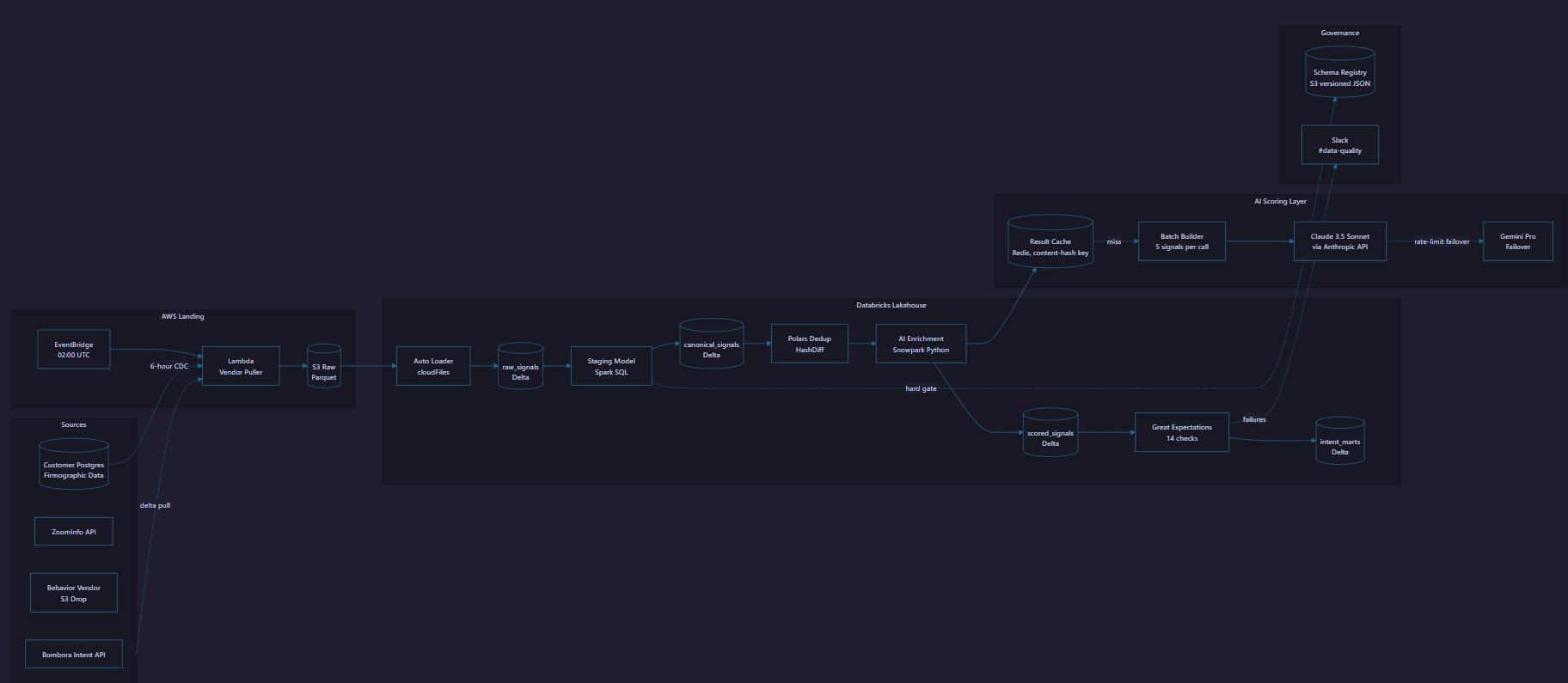
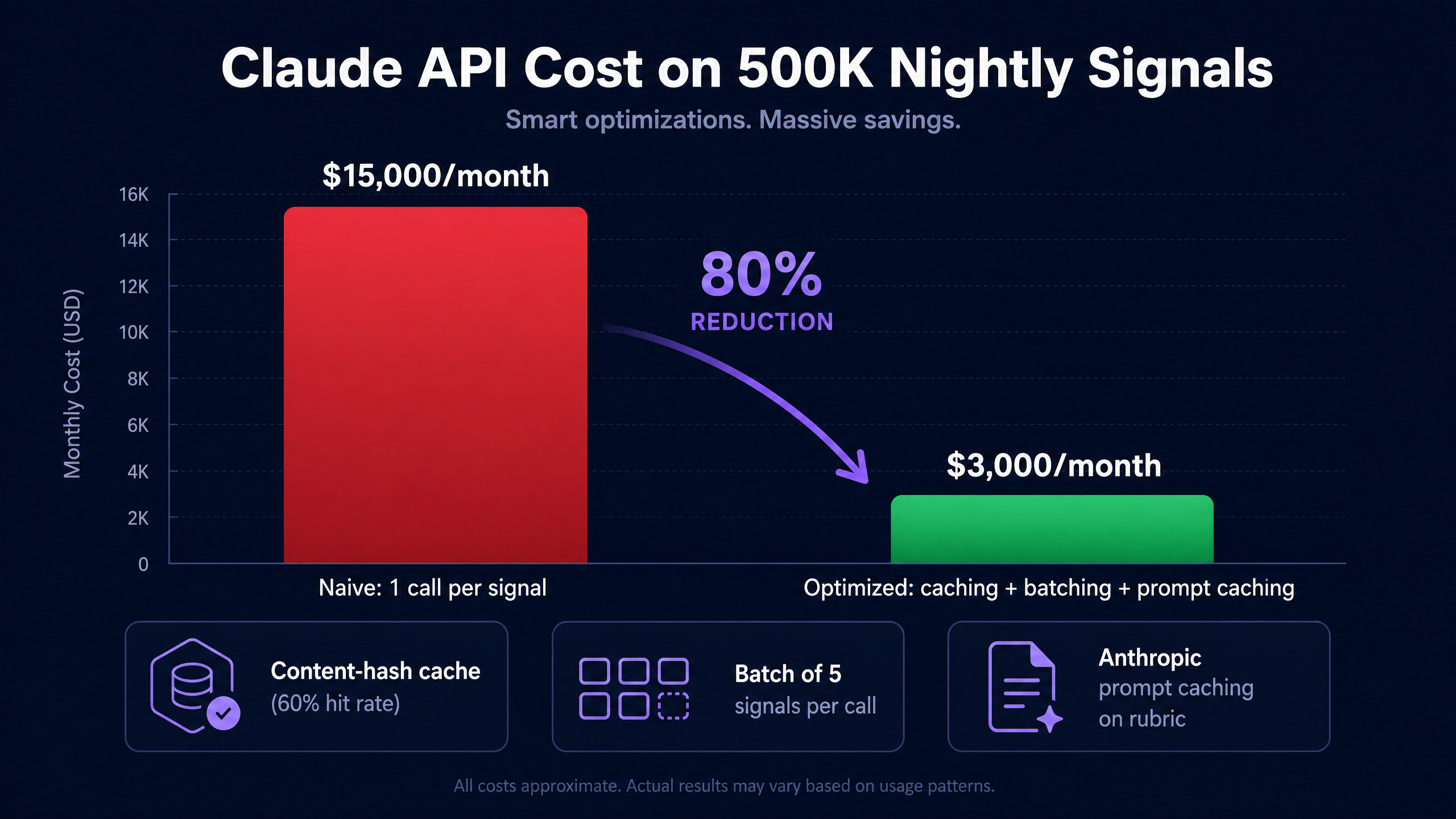
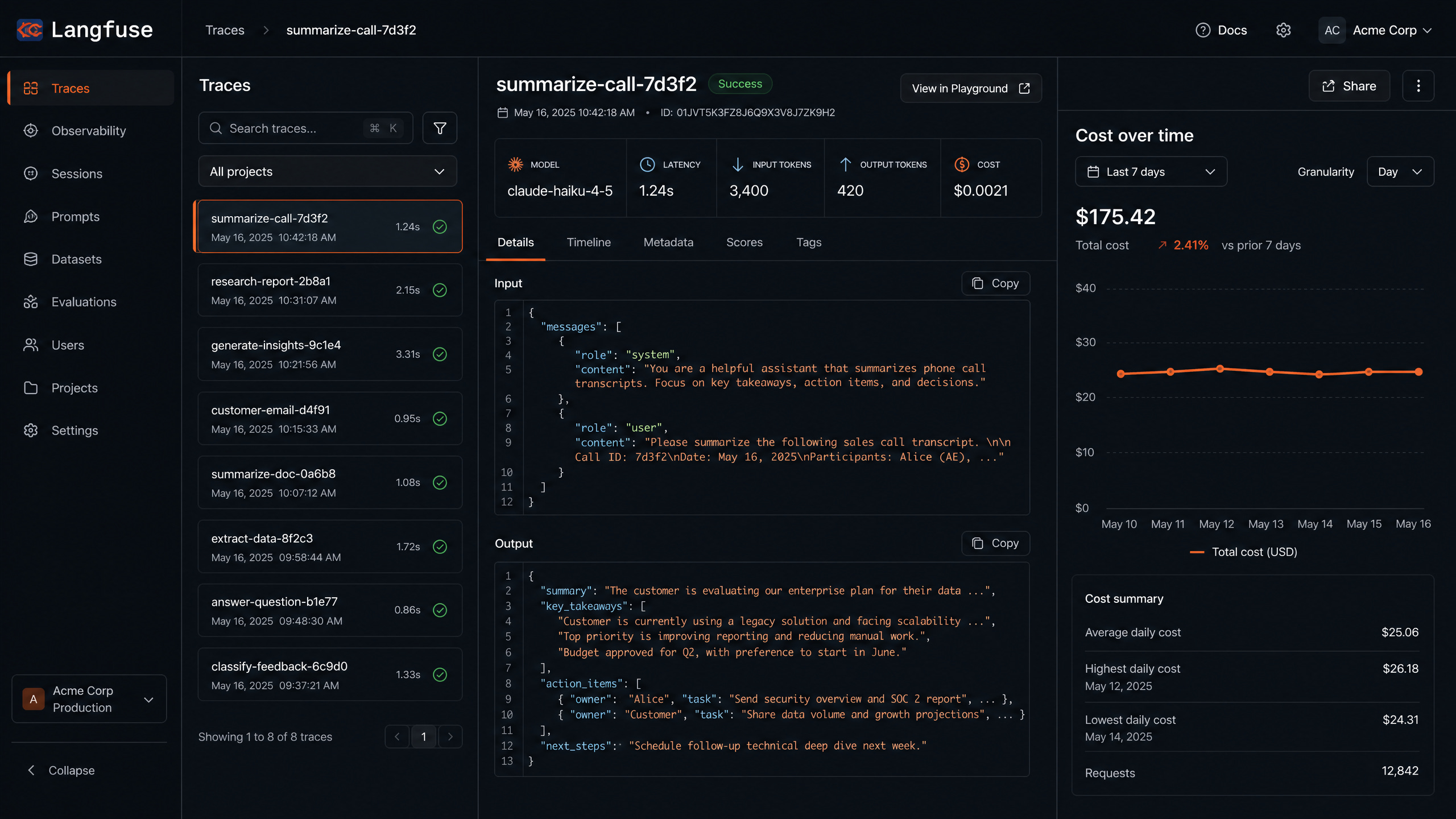
“At Elantis.AI I built a daily Databricks pipeline that enriches 500K B2B intent signals nightly with Claude 3.5 Sonnet. Step 1 was vendor delta ingestion into S3 then Auto Loader into Delta raw tables. Step 2 was a schema registry hard gate that paused batches on vendor drift. Step 3 was Polars dedup using HashDiff on canonical columns. Step 4 was a content-hash cache check before any Claude call. Step 5 was batched Claude scoring at 5 signals per API call. Step 6 was Anthropic prompt caching on the system rubric. Step 7 was Delta writeback. Step 8 was Great Expectations quality gates. Step 9 was publishing to mart tables. Step 10 was Slack alerting on any prior-stage failure. The hardest production problem was Claude cost. At naive rates the pipeline would have cost $15K per month. The caching plus batching plus prompt caching stack dropped it to $3K. The pipeline ran in production for 16 months and lifted scoring F1 by 15 to 20 percent over the rules-based baseline.”
Snapshot
Where: Elantis.AI, contract role as Founding AI Solutions Architect
Duration: August 2023 to December 2024 (16 months in production)
Scale: 500K records per nightly batch
Outcome: 15 to 20 percent F1 lift on lead scoring over the rules-based baseline. AI cost dropped 80 percent (from $15K to $3K per month).
The Business Use Case
The customer was a sales intelligence vendor selling B2B intent signals. They sourced raw signals from three data providers (Bombora-style intent vendor, ZoomInfo-style firmographic vendor, and a third behavior vendor), joined them against the customer’s own firmographic data, and resold scored leads. The original scoring was rules-based and stale. The product team wanted higher-quality scores grounded in LLM reasoning. The data engineering challenge was running 500K signals through an LLM nightly without blowing up cost or hitting rate limits.
Architecture Diagram
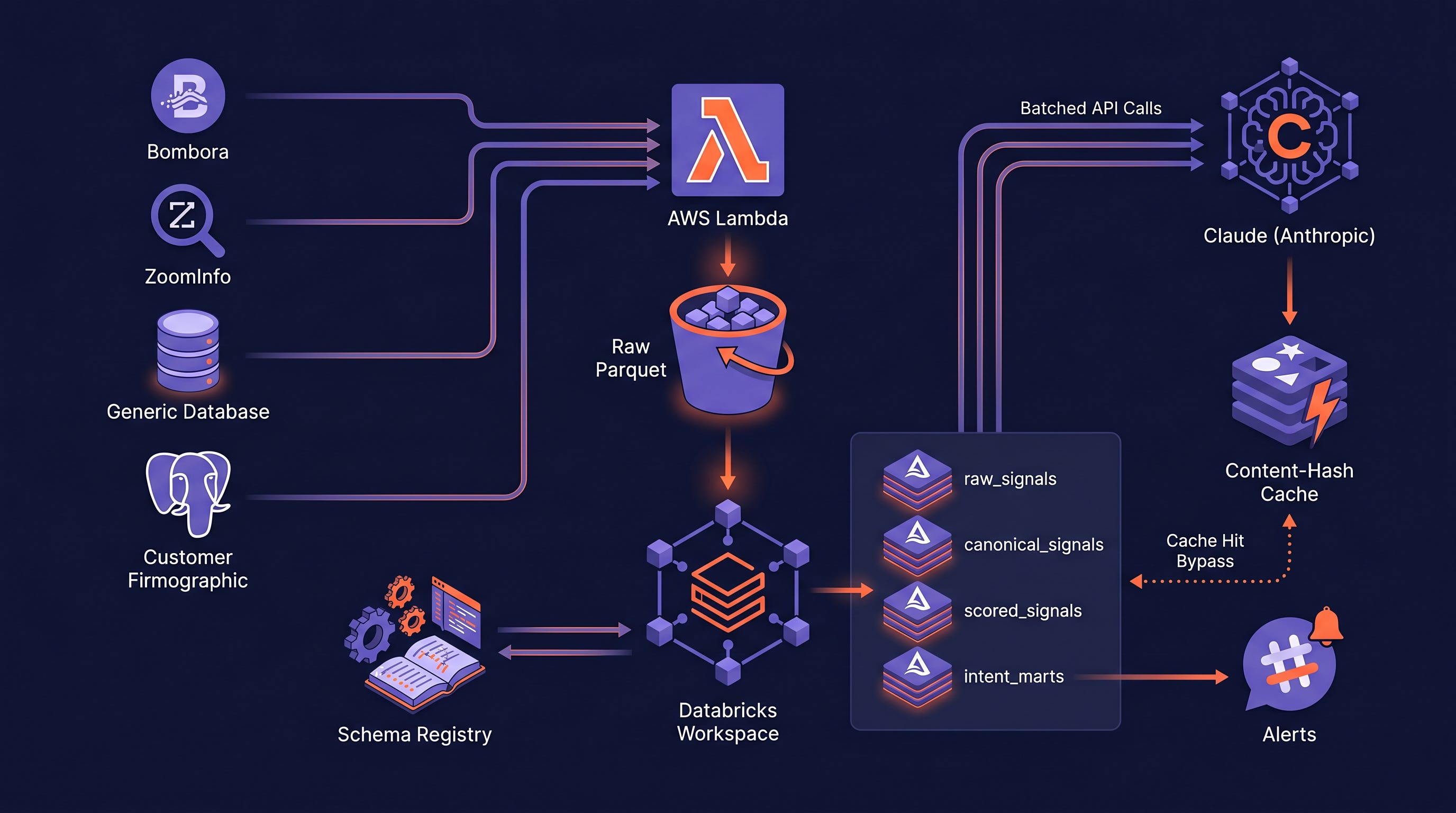
Tech Stack

Setup Guide I Followed
The Databricks workspace setup follows a standard pattern. The interesting parts are the cluster sizing, the secret scope for the Claude API key, and the schema-registry bucket structure.
Cluster configuration (cluster.json).
{
"cluster_name": "elantis-enrichment-cluster",
"spark_version": "14.3.x-scala2.12",
"node_type_id": "i3.2xlarge",
"driver_node_type_id": "i3.4xlarge",
"num_workers": 4,
"autoscale": {"min_workers": 2, "max_workers": 8},
"spark_conf": {
"spark.databricks.delta.preview.enabled": "true",
"spark.databricks.delta.schema.autoMerge.enabled": "true"
}
}
Secret scope setup (Databricks CLI).
databricks secrets create-scope --scope elantis-prod
databricks secrets put --scope elantis-prod --key anthropic_api_key
databricks secrets put --scope elantis-prod --key gemini_api_key
databricks secrets put --scope elantis-prod --key redis_url
Schema registry layout in S3.
s3://elantis-schema-registry/
bombora/
v1.json
v2.json
current -> v2.json
zoominfo/
v1.json
current -> v1.json
behavior_vendor/
v3.json
current -> v3.json
Step-by-Step Flow with Code
Step 1, vendor ingestion. EventBridge fires the daily cron at 02:00 UTC. Lambda pulls the previous day’s delta from each vendor and lands Parquet into S3 partitioned by date plus vendor.
# lambda_handler.py (excerpt)
import boto3, pyarrow as pa, pyarrow.parquet as pq
from datetime import datetime, timedelta
def handler(event, context):
yesterday = (datetime.utcnow() - timedelta(days=1)).strftime("%Y-%m-%d")
for vendor in ["bombora", "zoominfo", "behavior"]:
signals = fetch_vendor_delta(vendor, yesterday)
table = pa.Table.from_pylist(signals)
s3_path = f"s3://elantis-raw/{vendor}/dt={yesterday}/part.parquet"
pq.write_table(table, s3_path)
return {"status": "ok", "date": yesterday}
Step 2, Auto Loader picks up the Parquet.
# notebook_01_ingest.py
raw_stream = (
spark.readStream
.format("cloudFiles")
.option("cloudFiles.format", "parquet")
.option("cloudFiles.schemaLocation", "/mnt/checkpoints/raw_signals")
.option("cloudFiles.schemaEvolutionMode", "rescue")
.load("s3://elantis-raw/")
)
(raw_stream.writeStream
.option("checkpointLocation", "/mnt/checkpoints/raw_signals/sink")
.trigger(availableNow=True)
.toTable("elantis.raw_signals"))
Step 3, schema registry gate. Unknown columns in _rescued_data pause the batch.
# notebook_02_schema_gate.py
import json, boto3
s3 = boto3.client("s3")
def assert_no_drift(vendor, df):
schema = json.loads(s3.get_object(
Bucket="elantis-schema-registry",
Key=f"{vendor}/current"
)["Body"].read())
rescued = df.filter("_rescued_data is not null").count()
if rescued > 0:
raise SchemaDriftError(f"{vendor}: {rescued} rows with unknown fields")
Step 4, normalize into the canonical schema.
-- notebook_03_normalize.sql
CREATE OR REPLACE TABLE elantis.canonical_signals AS
SELECT
vendor || ':' || vendor_signal_id AS signal_id,
vendor,
entity_name,
industry_code,
signal_type,
signal_strength,
CAST(signal_date AS DATE) AS signal_date,
vendor_confidence
FROM elantis.raw_signals
WHERE _rescued_data IS NULL
Step 5, Polars dedup using HashDiff.
# notebook_04_dedup.py
import polars as pl
import hashlib
def hash_row(row):
canon = f"{row['entity_name']}|{row['signal_type']}|{row['signal_date']}"
return hashlib.sha256(canon.encode()).hexdigest()
df = spark.read.table("elantis.canonical_signals").toPandas()
pdf = pl.from_pandas(df)
pdf = pdf.with_columns(pl.struct(["entity_name","signal_type","signal_date"])
.map_elements(hash_row).alias("hashdiff"))
pdf = pdf.unique(subset=["hashdiff"], keep="first")
Step 6, content-hash cache check before any Claude call.
# notebook_05_enrich.py (cache layer)
import redis, hashlib
r = redis.from_url(dbutils.secrets.get("elantis-prod","redis_url"))
def cache_key(signal):
payload = f"{signal['entity_name']}|{signal['signal_type']}|{signal['signal_strength']}"
return f"score:{hashlib.sha256(payload.encode()).hexdigest()[:16]}"
def get_cached_score(signal):
cached = r.get(cache_key(signal))
return float(cached) if cached else None
Step 7, batched Claude scoring with backoff and Gemini failover.
# notebook_05_enrich.py (Claude call)
from anthropic import Anthropic
client = Anthropic(api_key=dbutils.secrets.get("elantis-prod","anthropic_api_key"))
def score_batch(signals, retries=5):
prompt = build_scoring_prompt(signals) # embeds the customer rubric
for attempt in range(retries):
try:
resp = client.messages.create(
model="claude-3-5-sonnet-20241022",
max_tokens=1024,
system={"type": "text", "text": SCORING_RUBRIC,
"cache_control": {"type": "ephemeral"}},
messages=[{"role": "user", "content": prompt}],
)
return parse_scores(resp.content[0].text)
except RateLimitError:
time.sleep(min(0.25 * 2**attempt, 30))
return score_batch_gemini(signals) # failover
Step 8, write enriched output to Delta.
# notebook_06_publish.py
scored_df = spark.createDataFrame(scored_signals)
(scored_df.write
.format("delta")
.mode("append")
.option("mergeSchema", "true")
.saveAsTable("elantis.scored_signals"))
Step 9, Great Expectations quality gate.
# notebook_07_quality.py
import great_expectations as gx
context = gx.get_context()
batch = context.sources.delta.get_batch("elantis.scored_signals")
expectations = [
batch.expect_column_values_to_not_be_null("signal_id"),
batch.expect_column_values_to_be_unique("signal_id"),
batch.expect_column_values_to_be_between("confidence_score", 0, 1),
batch.expect_table_row_count_to_be_between(
min_value=400_000, max_value=600_000
),
]
if any(not e.success for e in expectations):
raise QualityGateFailure(...)
Step 10, publish to mart tables and alert on failure.
# notebook_08_publish_mart.py
spark.sql("""
INSERT OVERWRITE TABLE elantis.intent_marts
SELECT * FROM elantis.scored_signals
WHERE signal_date = current_date() - INTERVAL 1 DAY
""")
# Slack alert on any prior-stage failure
if pipeline_state.has_failure():
post_to_slack(channel="#data-quality", message=pipeline_state.summary())
Production Challenges and Decisions
Claude cost would have been $15K per month at full price. Three layered fixes. Content-hash result caching cut 60 percent of calls by day 30. Packing 5 signals per call amortized input tokens. Anthropic prompt caching on the system rubric (the
cache_controlephemeral flag in the code above) cut the cached portion to 10 percent of full cost. Total dropped to $3K per month.Vendor schema drift was the most frequent failure mode. A schema registry checked into S3 plus a hard gate on the normalize step. Unknown columns paused the batch with a Slack alert. Paused batches over corrupted output, by design.
Why Databricks not Snowflake: Delta’s
_rescued_datacolumn was the cleanest answer to vendor drift. Snowpark Python was still maturing in late 2023. Team had stronger Databricks bench.Why Polars for dedup: 500K rows is single-machine territory. PySpark overhead dominated. Polars in-cluster was 4x faster.
Why Claude over a fine-tuned smaller model: scoring rubric changed bi-weekly with sales feedback. Prompt iteration was same-day. Fine-tuning would have meant 2 to 3 weeks per change.
Why Redis for the cache layer: managed AWS ElastiCache cluster already running for the application tier. One config change instead of standing up a new store.
Project 2, AI-Powered RAG Pipeline for GTM Intelligence
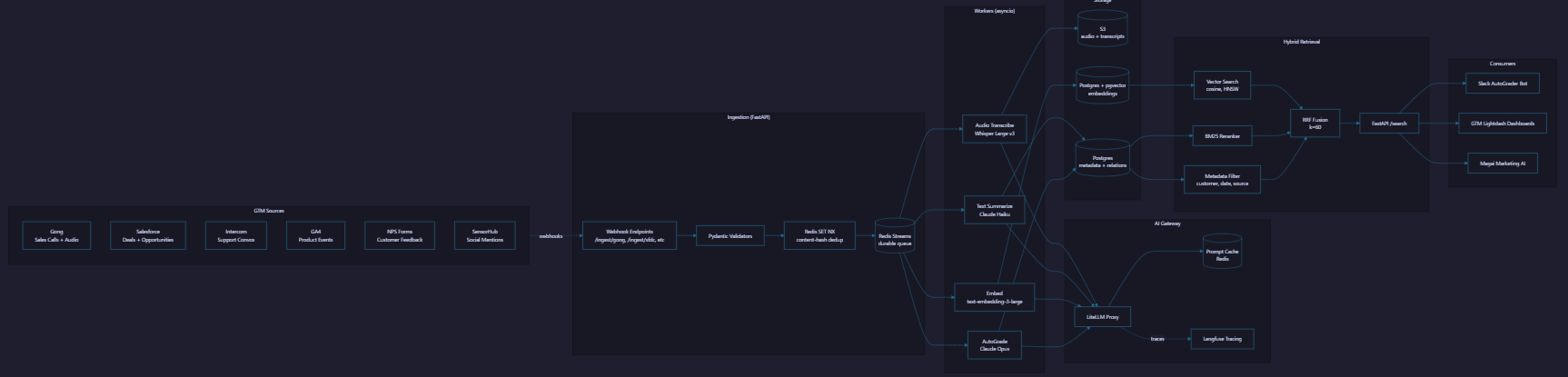
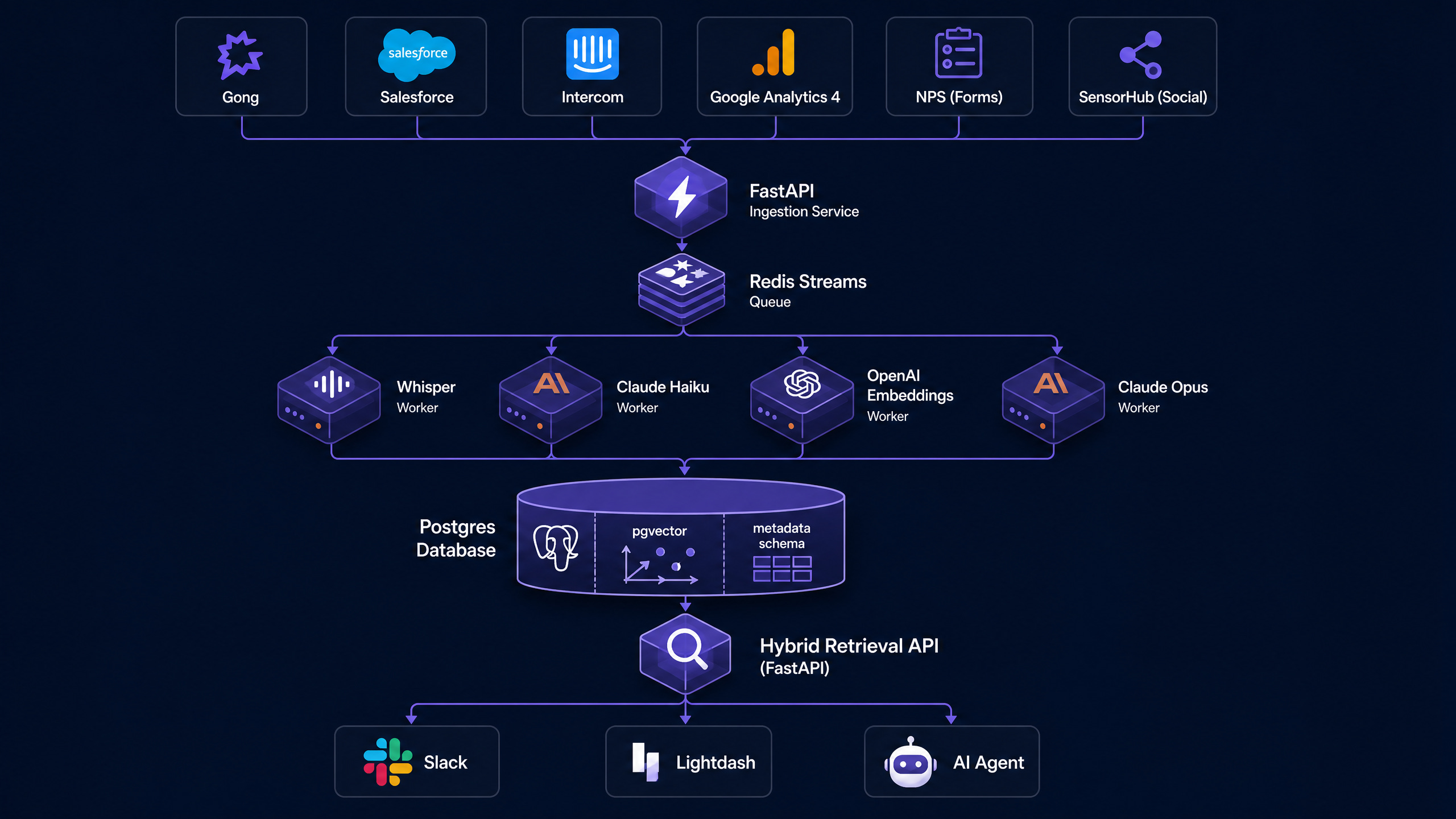
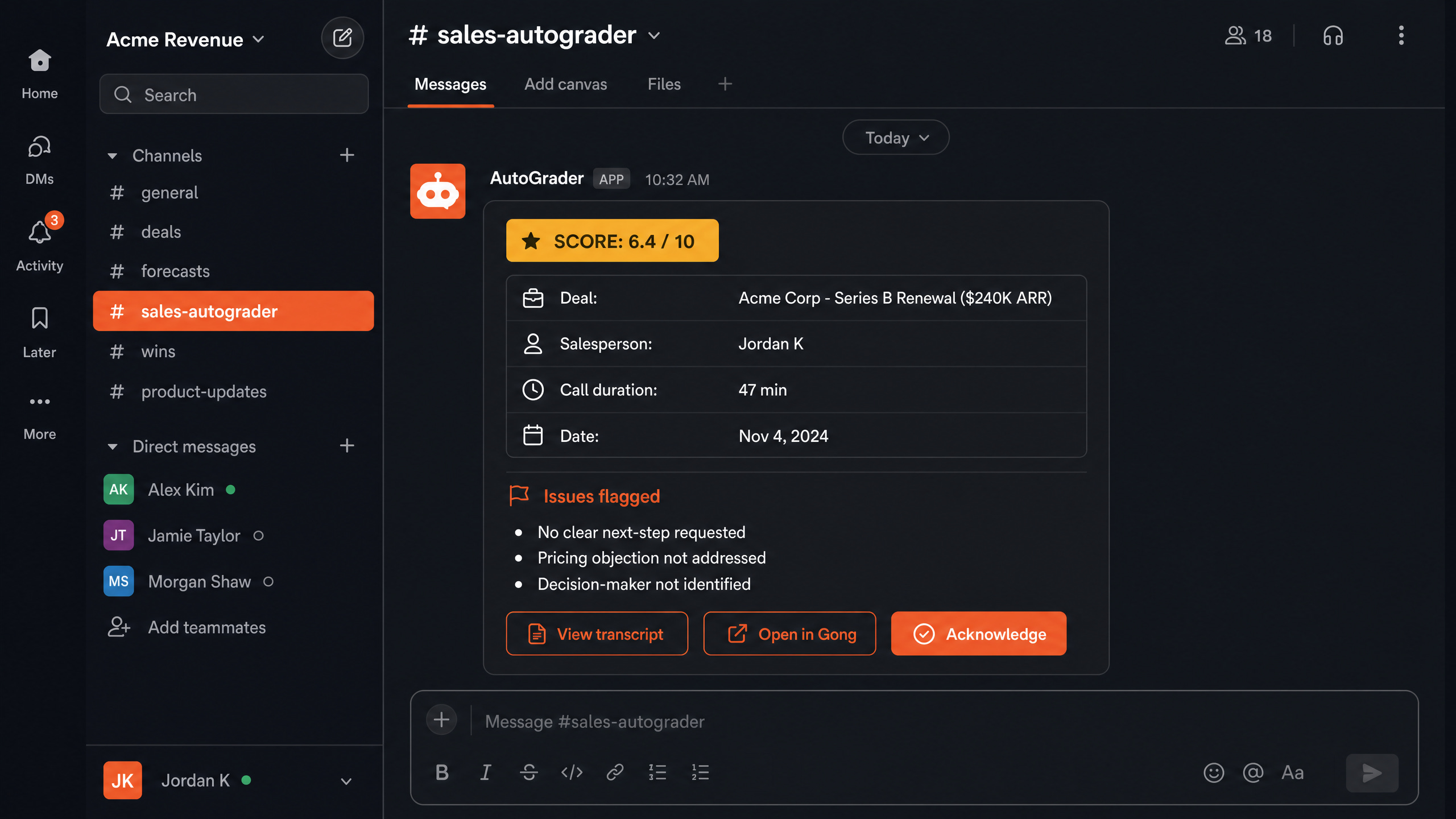
“At AccuKnox I built the GTM knowledge base. Step 1 was FastAPI webhook receivers for six sources: Gong, Salesforce, Intercom, GA4, NPS, SensorHub. Step 2 was Redis SET NX on a content hash to drop duplicates at the edge. Step 3 was Redis Streams as the durable queue. Step 4 was Whisper transcription for Gong audio. Step 5 was Claude Haiku summarization with prompt caching on the system prompt. Step 6 was OpenAI text-embedding-3-large into pgvector with HNSW indexing. Step 7 was a two-tier AutoGrader, Haiku for first pass and Opus only for the top 10 percent of deals by value. Step 8 was hybrid retrieval combining vector cosine, BM25 keyword, and metadata filter with Reciprocal Rank Fusion. The hardest production problem was late-arriving Gong transcripts. The webhook fires on call-end but the transcript URL stays empty for up to 48 hours. Fix was event versioning. The worker requeues until the transcript populates, then atomically overwrites the empty earlier summary. Production cycle time dropped 60 percent.”
Snapshot
Where: AccuKnox, internal data tooling
Duration: 2024 to present
Scale: 2M events per month across 6 sources, 800K embedded documents
Outcome: 60 percent reduction in content production cycles. Powers the AccuKnox sales AutoGrader and marketing RAG.
The Business Use Case
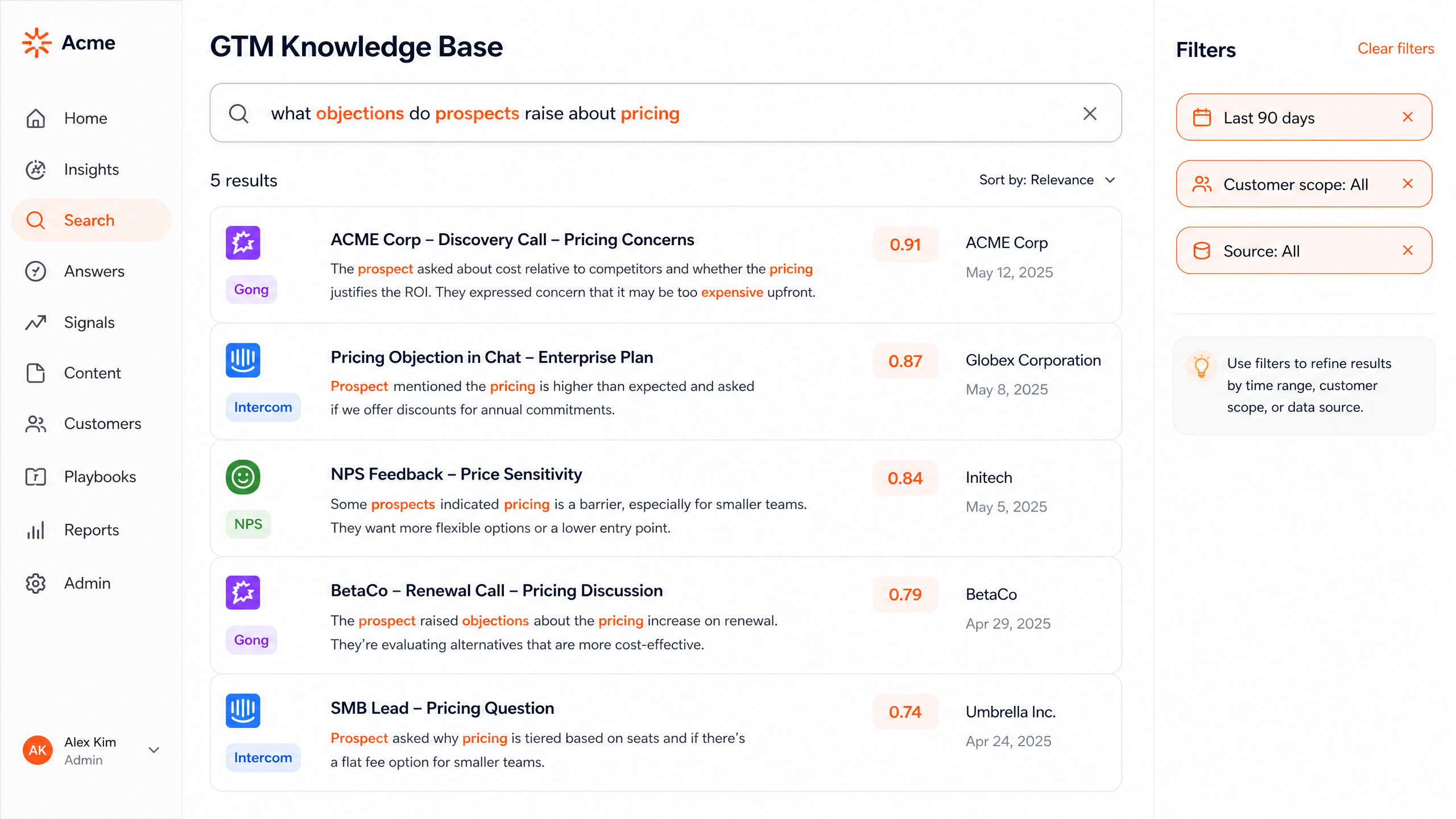
The AccuKnox GTM team needed a single queryable knowledge base across sales calls (Gong), support conversations (Intercom), product analytics (GA4), customer feedback (NPS forms), CRM (Salesforce), and social mentions (SensorHub). The goal was to ground sales coaching and marketing content in actual customer language. The data engineering challenge was running ingestion plus embedding plus retrieval reliably across multimodal sources (audio plus text) with idempotency under retries.
Architecture Diagram
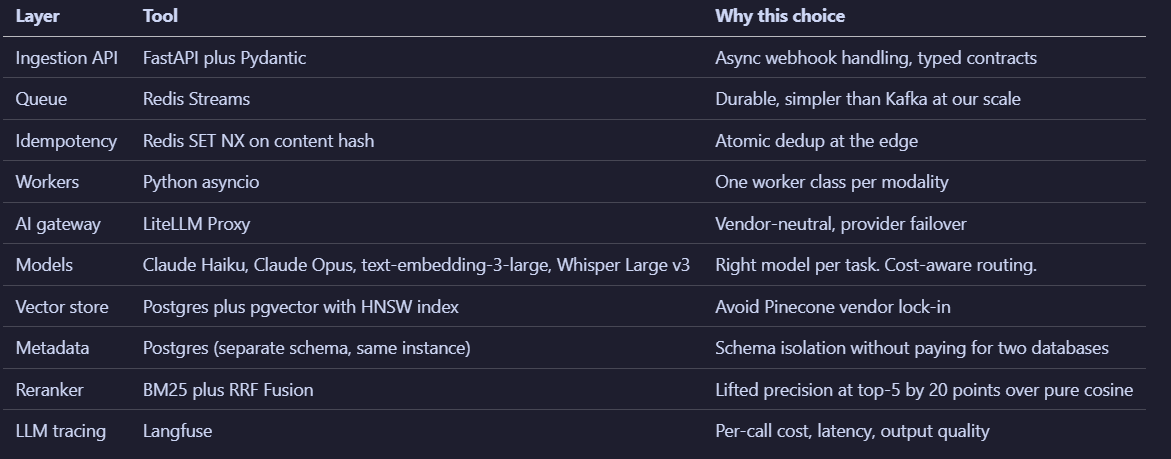
Tech Stack
Setup Guide
The interesting setup pieces are the pgvector HNSW index, the LiteLLM proxy config, the Redis Streams consumer groups, and the FastAPI webhook signature validation.
pgvector setup.
-- One-time database setup
CREATE EXTENSION IF NOT EXISTS vector;
CREATE TABLE embeddings (
doc_id UUID PRIMARY KEY,
embedding vector(3072), -- text-embedding-3-large dimensions
model_version TEXT NOT NULL DEFAULT 'v2',
created_at TIMESTAMPTZ DEFAULT now()
);
-- HNSW index for fast similarity search
CREATE INDEX embeddings_hnsw_idx
ON embeddings
USING hnsw (embedding vector_cosine_ops)
WITH (m = 16, ef_construction = 64);
LiteLLM Proxy config (config.yaml).
model_list:
- model_name: summarize
litellm_params:
model: anthropic/claude-haiku-4-5
api_key: os.environ/ANTHROPIC_API_KEY
- model_name: grade
litellm_params:
model: anthropic/claude-opus-4-5
api_key: os.environ/ANTHROPIC_API_KEY
- model_name: embed
litellm_params:
model: openai/text-embedding-3-large
api_key: os.environ/OPENAI_API_KEY
router_settings:
routing_strategy: simple-shuffle
fallbacks:
- summarize: ["grade"]
litellm_settings:
cache: true
cache_params:
type: redis
host: os.environ/REDIS_HOST
ttl: 86400
Redis Streams consumer group setup.
# bootstrap_streams.py
import redis
r = redis.from_url(REDIS_URL)
for stream in ["gtm-events"]:
for group in ["transcribe", "summarize", "embed", "grade"]:
try:
r.xgroup_create(stream, group, id="0", mkstream=True)
except redis.exceptions.ResponseError:
pass # already exists
Step-by-Step Flow with Code
Step 1, FastAPI webhook receiver.
# main.py
from fastapi import FastAPI, Header, HTTPException
from pydantic import BaseModel
import hashlib, hmac
app = FastAPI()
class GongCallEvent(BaseModel):
call_id: str
duration_seconds: int
audio_url: str | None
transcript_url: str | None
participants: list[dict]
deal_id: str | None
occurred_at: str
@app.post("/ingest/gong")
async def ingest_gong(event: GongCallEvent, x_gong_signature: str = Header(...)):
verify_signature(event.json(), x_gong_signature)
return await enqueue_event(source="gong", payload=event.dict())
Step 2, Redis SET NX content-hash dedup.
# dedup.py
import hashlib, json
async def enqueue_event(source: str, payload: dict):
canonical = json.dumps(payload, sort_keys=True)
content_hash = hashlib.sha256(canonical.encode()).hexdigest()
key = f"dedup:{source}:{content_hash}"
was_new = await redis.set(key, "1", nx=True, ex=86400 * 7) # 7-day TTL
if not was_new:
return {"status": "duplicate", "hash": content_hash}
await redis.xadd("gtm-events", {"source": source, "payload": canonical})
return {"status": "accepted", "hash": content_hash}
Step 3, worker dispatch by modality.
# worker_dispatch.py
async def consume_loop(consumer_group: str, handler):
while True:
msgs = await redis.xreadgroup(
consumer_group, "worker-1", {"gtm-events": ">"}, count=10, block=5000
)
for stream, messages in msgs:
for msg_id, fields in messages:
payload = json.loads(fields["payload"])
try:
await handler(payload)
await redis.xack("gtm-events", consumer_group, msg_id)
except Exception as e:
log_failure(msg_id, e) # leaves in PEL for retry
Step 4, Whisper transcription for audio.
# worker_transcribe.py
import boto3
from litellm import atranscription
async def transcribe_handler(payload):
if payload["source"] != "gong" or not payload.get("audio_url"):
return # skip non-audio
audio_bytes = download_s3(payload["audio_url"])
result = await atranscription(
model="whisper-1",
file=audio_bytes,
language="en",
)
transcript_s3_key = f"transcripts/{payload['call_id']}.txt"
upload_s3(transcript_s3_key, result["text"])
await redis.xadd("gtm-events", {
"source": "gong",
"payload": json.dumps({**payload, "transcript_text": result["text"], "stage": "summarize"})
})
Step 5, Claude Haiku summarization with prompt caching.
# worker_summarize.py
from litellm import acompletion
SYSTEM_PROMPT = """You are a sales call summarizer. ...
Output JSON with keys: summary, key_quotes, pain_points, next_steps, sentiment.
"""
async def summarize_handler(payload):
text = payload.get("transcript_text") or payload.get("body")
if not text or payload.get("stage") not in ("summarize", None):
return
resp = await acompletion(
model="summarize", # routes to Claude Haiku via LiteLLM
messages=[
{"role": "system", "content": SYSTEM_PROMPT,
"cache_control": {"type": "ephemeral"}},
{"role": "user", "content": text},
],
response_format={"type": "json_object"},
)
summary = json.loads(resp.choices[0].message.content)
await store_metadata(doc_id=payload["call_id"], source="gong", summary=summary)
Step 6, OpenAI embedding into pgvector.
# worker_embed.py
from litellm import aembedding
import uuid, psycopg
async def embed_handler(payload):
text_for_embedding = build_embed_text(payload) # summary + key passages
resp = await aembedding(
model="embed", # text-embedding-3-large via LiteLLM
input=[text_for_embedding],
)
vec = resp.data[0]["embedding"]
async with pg_pool.connection() as conn:
await conn.execute("""
INSERT INTO embeddings (doc_id, embedding, model_version)
VALUES (%s, %s, 'v2')
ON CONFLICT (doc_id) DO UPDATE
SET embedding = EXCLUDED.embedding,
model_version = EXCLUDED.model_version
""", (payload["call_id"], vec))
Step 7, AutoGrader Claude Opus for top deals only.
# worker_grade.py
async def grade_handler(payload):
deal_value = payload.get("deal_value", 0)
if deal_value < TOP_TIER_THRESHOLD:
return # only top 10% by deal value get Opus
resp = await acompletion(
model="grade",
messages=build_grader_prompt(payload),
response_format={"type": "json_object"},
)
grade = json.loads(resp.choices[0].message.content)
if grade["score"] < grade_threshold(payload):
post_to_slack("#autograder", f"Low-quality call on deal {payload['deal_id']}")
Step 8, hybrid retrieval API (vector plus BM25 plus filter plus RRF).
# rag_api.py
from fastapi import FastAPI
@app.post("/search")
async def search(query: str, customer_id: str, top_k: int = 5):
# Vector branch
q_vec = (await aembedding(model="embed", input=[query])).data[0]["embedding"]
vec_results = await pg.execute("""
SELECT doc_id, embedding <=> %s AS distance
FROM embeddings
WHERE doc_id IN (SELECT doc_id FROM documents WHERE customer_id = %s)
ORDER BY embedding <=> %s
LIMIT 50
""", (q_vec, customer_id, q_vec))
# BM25 branch
bm_results = await pg.execute("""
SELECT doc_id, ts_rank(search_vector, plainto_tsquery(%s)) AS rank
FROM documents
WHERE customer_id = %s
ORDER BY rank DESC LIMIT 50
""", (query, customer_id))
# RRF fusion
fused = rrf_fuse([vec_results, bm_results], k=60)
return fused[:top_k]
def rrf_fuse(rankings, k=60):
scores = {}
for ranked_list in rankings:
for rank, item in enumerate(ranked_list, start=1):
scores.setdefault(item["doc_id"], 0)
scores[item["doc_id"]] += 1 / (k + rank)
return sorted(scores.items(), key=lambda x: -x[1])
Production Challenges and Decisions
Late-arriving Gong transcripts (sometimes 48 hours after the call-end webhook). Fix: event versioning. The worker requeues the event with an exponential delay until the transcript field populates, then overwrites the empty earlier summary atomically.
Cost on Claude Opus if used on every grade. Fix: two-tier AutoGrader. Haiku for first-pass scoring. Opus only for the top 10 percent of deals by value. Stayed under $800 per month.
Multimodal handling. Audio plus text plus numeric needed different processing. Fix: per-modality workers with a shared metadata schema. Workers diverge. Downstream RAG treats sources uniformly.
RAG retrieval relevance. Pure cosine similarity hit 62 percent precision at top-5. Adding BM25 plus metadata filter plus the larger embedding model lifted it to 82 percent.
Embedding model upgrade. When OpenAI released text-embedding-3-large, the cosine distances became incomparable with the v1 vectors. Fix: versioned embeddings table with a
model_versioncolumn. Background re-embed plus atomic config flip after 100 percent v2 coverage.Why pgvector not Pinecone: already running Postgres for metadata. One config change instead of a new managed service. Acceptable performance at 800K embeddings under 100ms p99.
Why LiteLLM Proxy not direct SDKs: provider failover during Anthropic maintenance windows. Per-task model selection cleaner through one config file.
Project 3, Modern Data Stack RevOps Pipeline
“At AccuKnox I built the RevOps pipeline. Step 1 was Lambda webhook receivers landing 7 SaaS sources into S3 with conditional PUT for idempotent dedup. Step 2 was Snowpipe auto-loading into Snowflake RAW. Step 3 was dbt staging models that normalize each source’s variant payload into typed columns, with unknown fields preserved in a
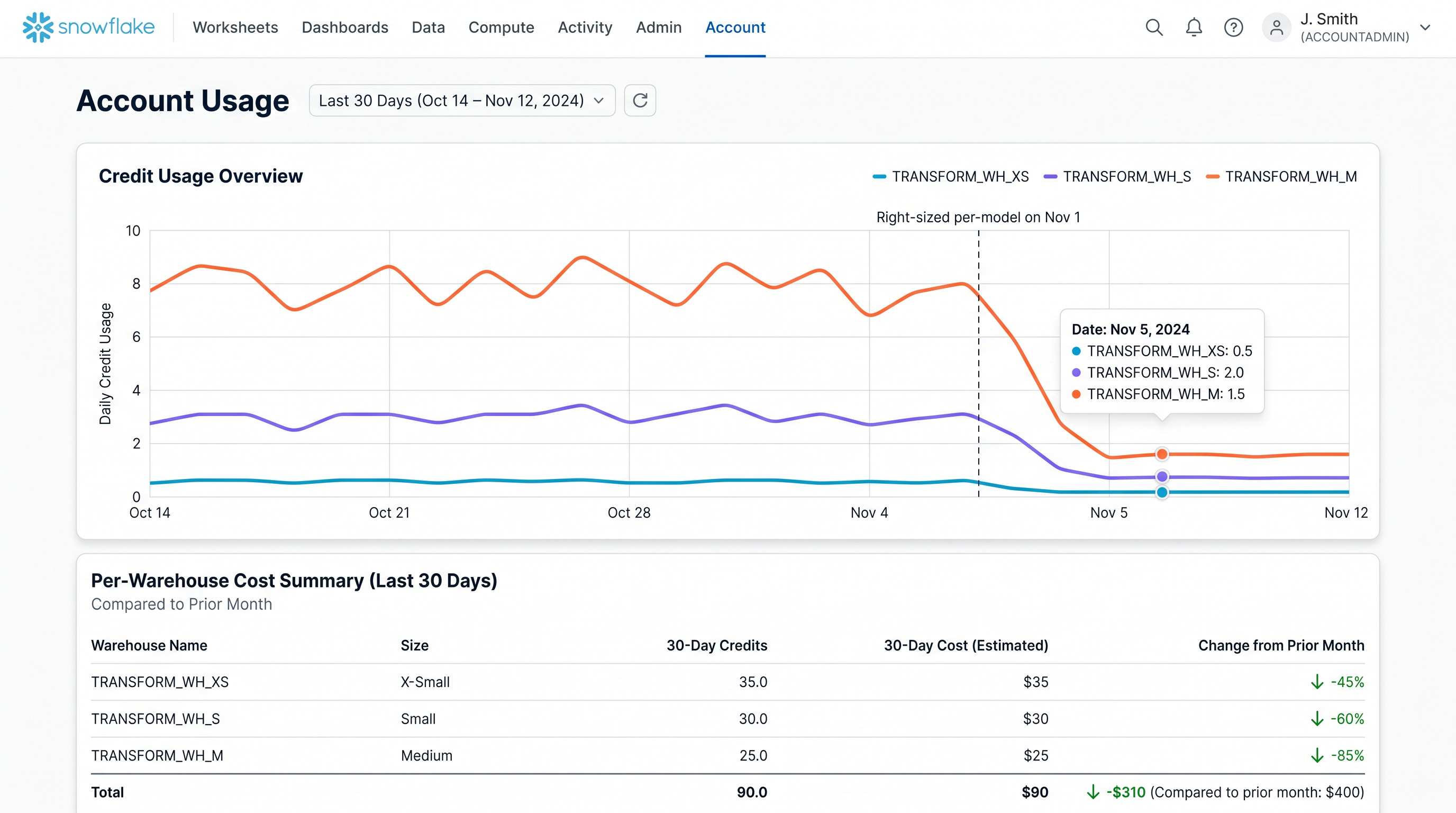
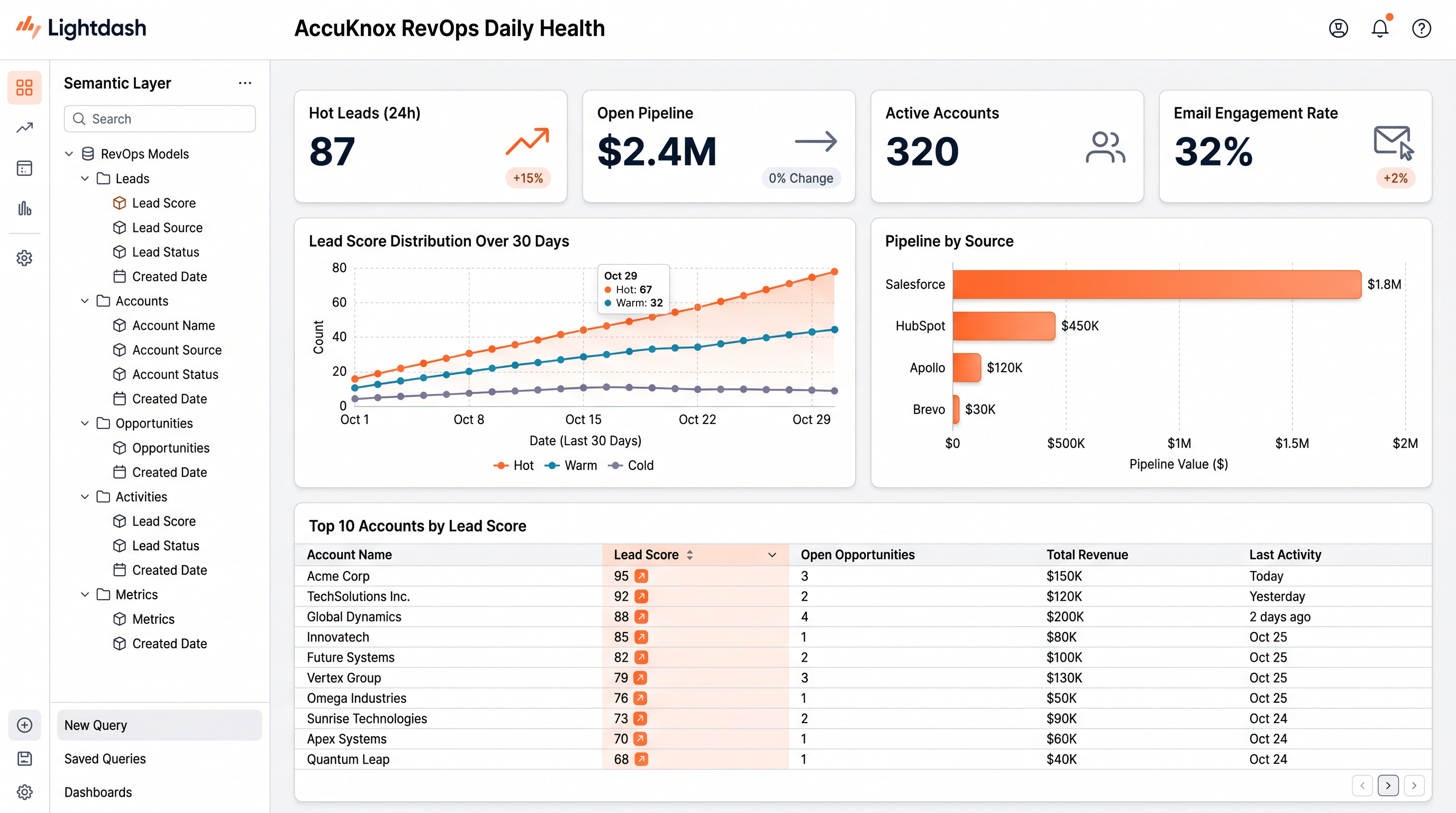
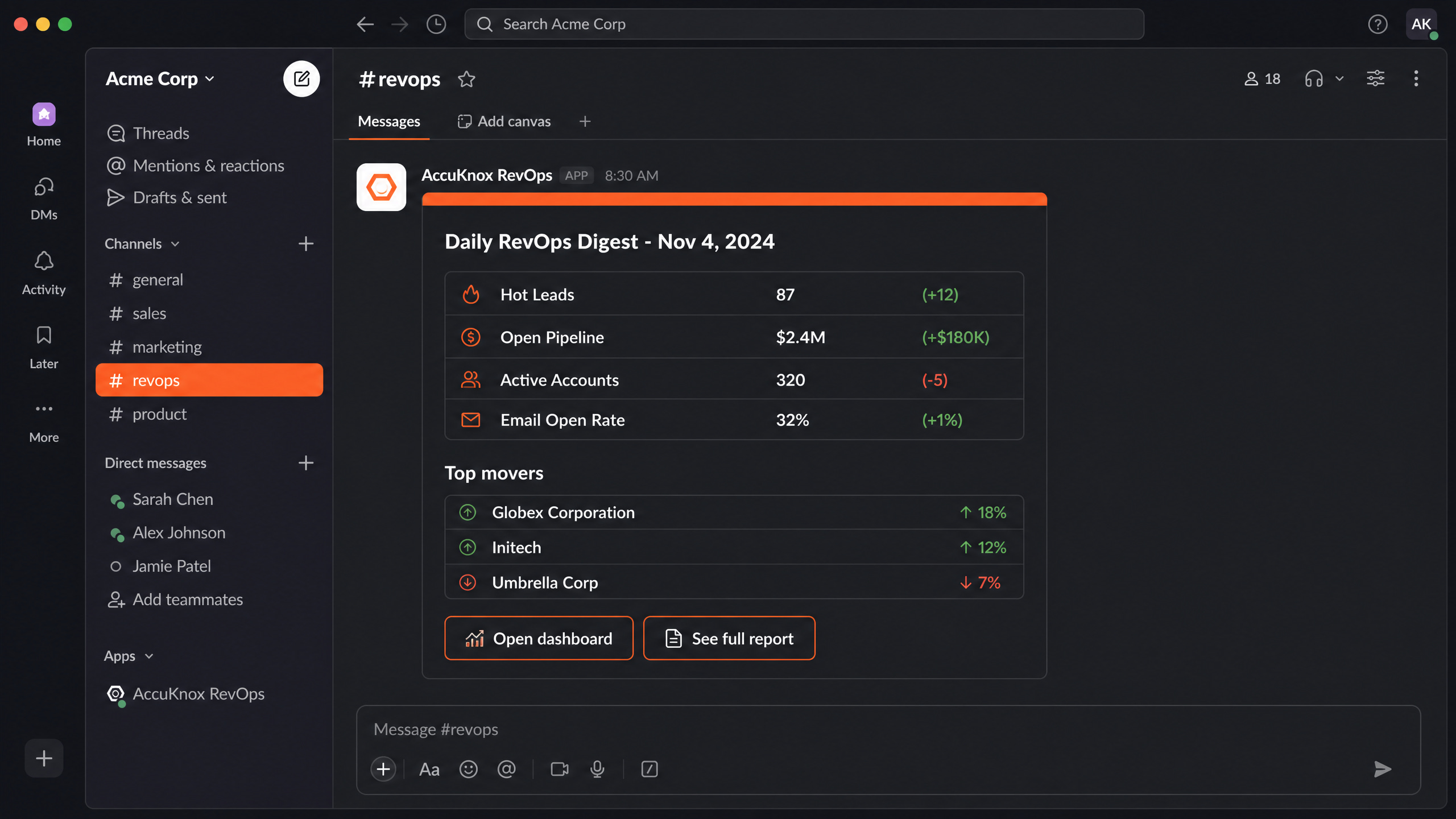
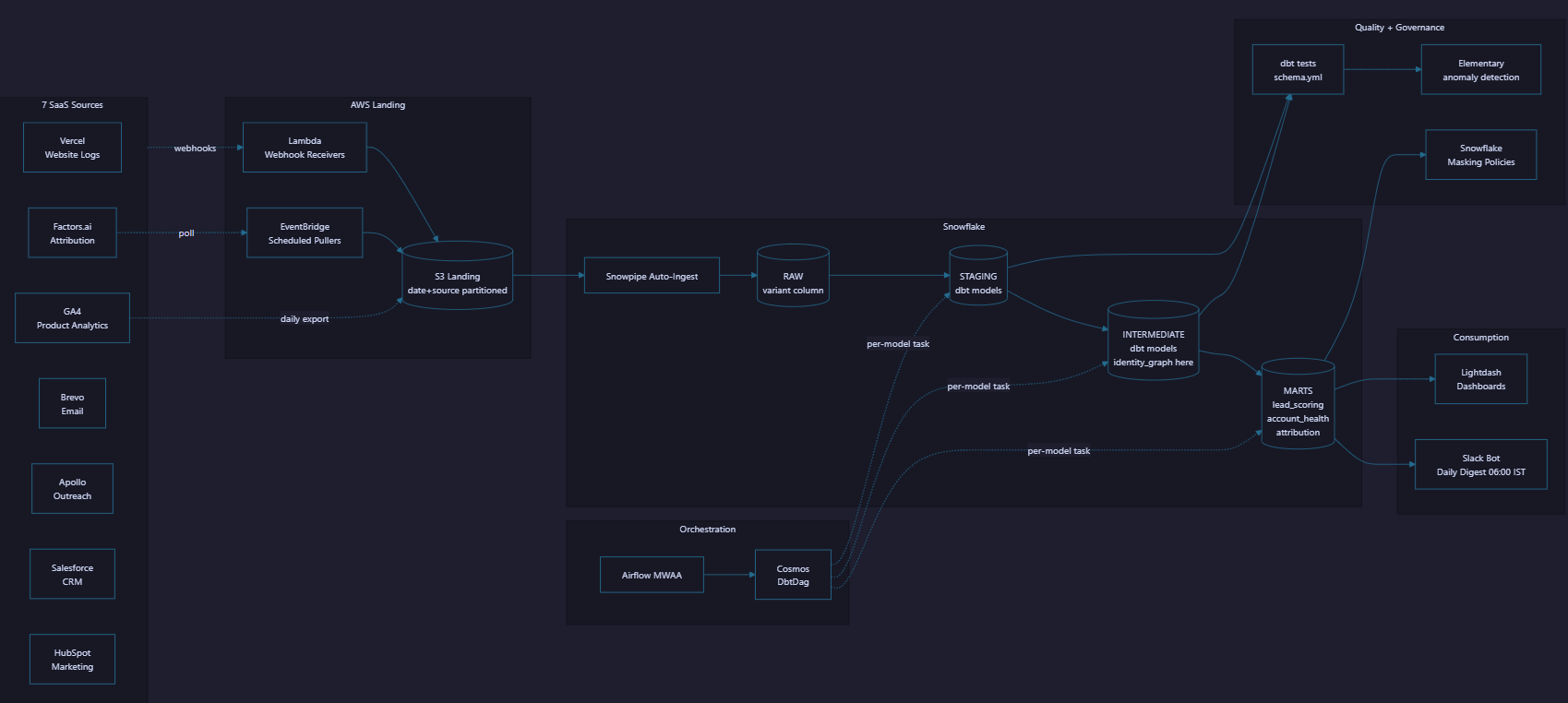
_raw_payloadJSON column. Step 4 was dbt tests inline after each staging model. Step 5 was the intermediate identity-resolution model that canonicalizes humans across all 7 systems using MD5 of the lowercased email. Step 6 was mart models for lead scoring, attribution, account health. Step 7 was Elementary anomaly detection. Step 8 was a Slack bot running one Snowflake query at 06:00 IST and posting the daily digest. The whole thing runs through Airflow MWAA plus Cosmos for per-model task granularity. The hardest production problem was Snowflake cost. The attribution mart on a large warehouse was $400 per month. Right-sizing per-model with XS for staging, S for intermediate, and M for the attribution mart dropped it to $90 with a 30 percent runtime increase. The full marketing stack went from $4K per month to $400.”
Snapshot
Where: AccuKnox, marketing and revenue operations
Duration: 2024 to present
Scale: 7 SaaS sources, 5M monthly events, daily marts on Snowflake
Outcome: Marketing stack cost dropped from $4K to $400 per month. Daily Slack digest replaced manual reporting.
The Business Use Case
The AccuKnox marketing team needed unified analytics across seven SaaS tools (Vercel website logs, GA4, Brevo email, Apollo outreach, Salesforce CRM, HubSpot marketing automation, Factors.ai attribution). Before this pipeline, the team read seven dashboards and reconciled manually. The data engineering challenge was reliable ingestion across all sources into Snowflake, modular dbt transformations, layered quality checks, PII governance, and a daily Slack digest the executive team could act on.
Architecture Diagram
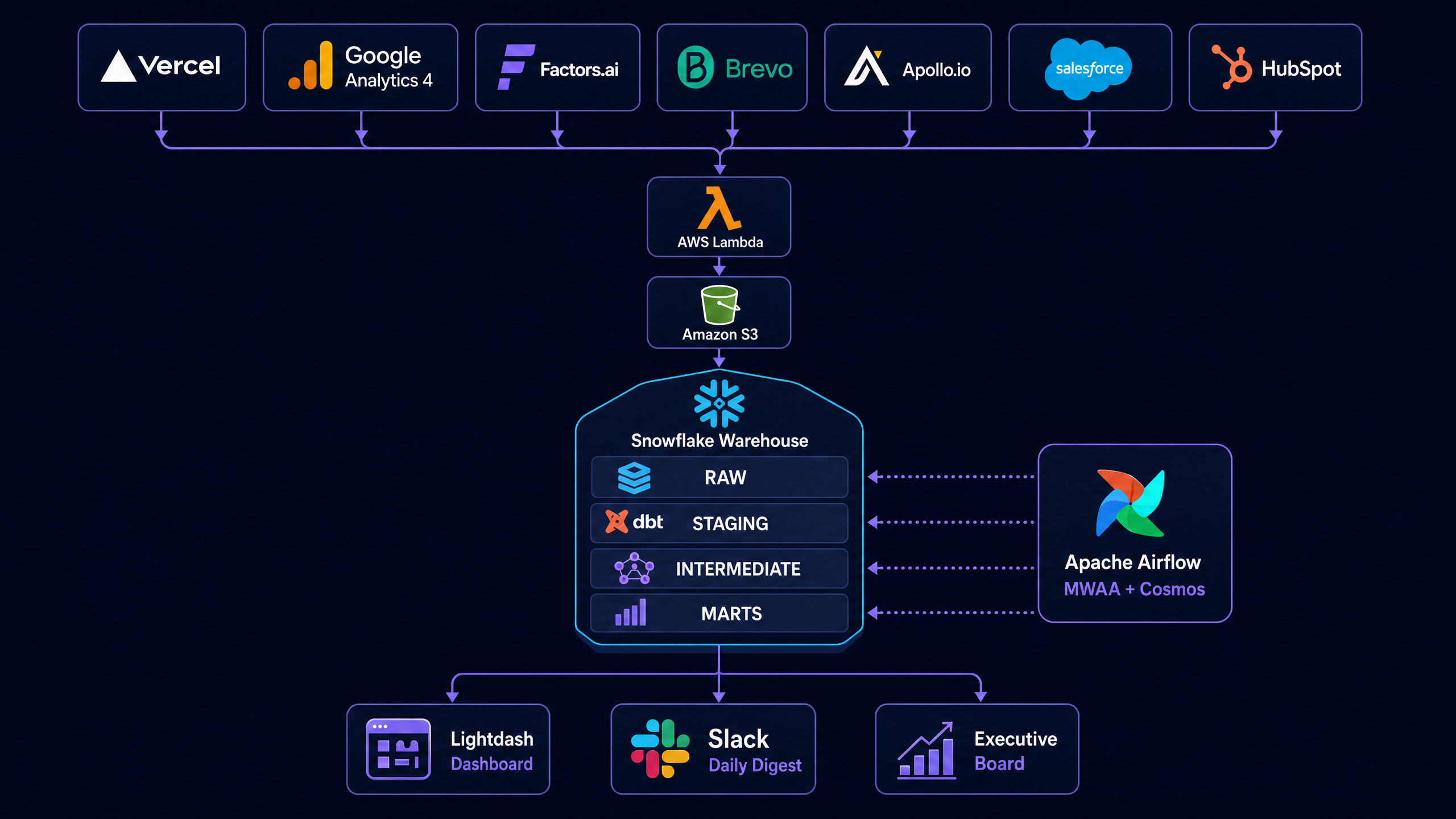
Tech Stack
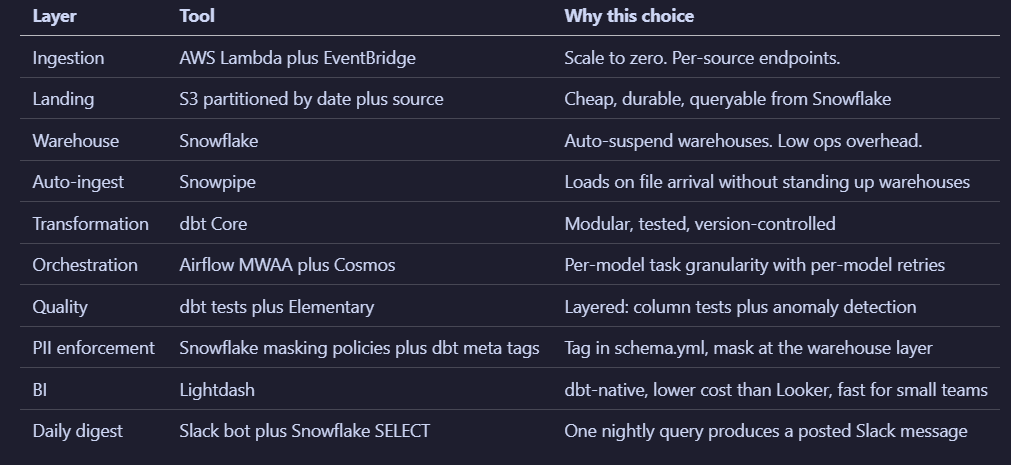
Setup Guide
The interesting setup pieces are the Snowflake masking policies, the Snowpipe configuration, the Cosmos DAG file, and the Lambda webhook signature validation.
Snowflake masking policy (one-time setup).
-- Create a masking policy for email columns
CREATE OR REPLACE MASKING POLICY pii_email_mask
AS (val STRING) RETURNS STRING ->
CASE
WHEN CURRENT_ROLE() IN ('COMPLIANCE_ROLE', 'SUPPORT_ROLE') THEN val
ELSE REGEXP_REPLACE(val, '^(.).+(@.+)$', '\\1***\\2')
END;
-- Apply to specific columns
ALTER TABLE marts.mart_lead_scoring
MODIFY COLUMN contact_email
SET MASKING POLICY pii_email_mask;
Snowpipe configuration.
CREATE OR REPLACE STAGE raw_s3_stage
URL = 's3://accuknox-revops-landing/'
STORAGE_INTEGRATION = aws_s3_int
FILE_FORMAT = (TYPE = JSON);
CREATE OR REPLACE PIPE raw.salesforce_pipe
AUTO_INGEST = TRUE
AS
COPY INTO raw.salesforce_events
FROM @raw_s3_stage/salesforce/
FILE_FORMAT = (TYPE = JSON)
ON_ERROR = CONTINUE;
Cosmos DAG file (dags/revops_daily.py).
from datetime import datetime
from cosmos import DbtDag, ProjectConfig, ProfileConfig, ExecutionConfig
from cosmos.profiles import SnowflakeUserPasswordProfileMapping
from pathlib import Path
profile_config = ProfileConfig(
profile_name="accuknox_revops",
target_name="prod",
profile_mapping=SnowflakeUserPasswordProfileMapping(
conn_id="snowflake_prod",
profile_args={
"database": "ANALYTICS",
"schema": "MARTS",
"warehouse": "TRANSFORM_WH_M",
},
),
)
revops_dag = DbtDag(
project_config=ProjectConfig(Path("/usr/local/airflow/dbt/accuknox_revops")),
profile_config=profile_config,
execution_config=ExecutionConfig(execution_mode="local"),
schedule="0 1 * * *", # 01:00 IST
start_date=datetime(2024, 6, 1),
catchup=False,
dag_id="accuknox_revops_daily",
default_args={"retries": 2, "retry_delay_seconds": 300},
)
Step-by-Step Flow with Code
Step 1, Lambda webhook receiver writes JSON to S3.
# lambda_webhook.py
import json, boto3, hashlib
from datetime import datetime
s3 = boto3.client("s3")
def handler(event, context):
source = event["pathParameters"]["source"]
body = json.loads(event["body"])
content_hash = hashlib.sha256(event["body"].encode()).hexdigest()
key = f"{source}/dt={datetime.utcnow():%Y-%m-%d}/{content_hash}.json"
try:
s3.put_object(
Bucket="accuknox-revops-landing",
Key=key,
Body=event["body"],
IfNoneMatch="*" # conditional PUT, drops duplicate
)
return {"statusCode": 200, "body": "accepted"}
except s3.exceptions.PreconditionFailed:
return {"statusCode": 200, "body": "duplicate"}
Step 2, Snowpipe auto-loads on S3 arrival (handled by the Snowpipe config above).
Step 3, dbt staging model with the _raw_payload pattern.
-- models/staging/salesforce/stg_sfdc_opportunities.sql
{{ config(materialized='view') }}
WITH source AS (
SELECT $1 AS raw_event,
$1:event_id::STRING AS event_id,
METADATA$FILENAME AS source_file,
CURRENT_TIMESTAMP() AS ingested_at
FROM raw.salesforce_events
)
SELECT
event_id,
raw_event:opportunity_id::STRING AS opportunity_id,
raw_event:account_id::STRING AS account_id,
raw_event:amount::NUMBER(18,2) AS opportunity_amount,
raw_event:stage_name::STRING AS stage_name,
raw_event:close_date::DATE AS close_date,
raw_event:owner_id::STRING AS owner_id,
raw_event AS _raw_payload, -- preserves unknown fields
ingested_at
FROM source
Step 4, dbt tests in schema.yml.
# models/staging/salesforce/schema.yml
version: 2
sources:
- name: salesforce_raw
schema: raw
tables:
- name: salesforce_events
loaded_at_field: ingested_at
freshness:
warn_after: {count: 6, period: hour}
error_after: {count: 24, period: hour}
models:
- name: stg_sfdc_opportunities
description: "One row per Salesforce opportunity event."
columns:
- name: event_id
tests: [not_null, unique]
- name: opportunity_id
tests: [not_null]
- name: opportunity_amount
tests:
- dbt_utils.accepted_range:
min_value: 0
max_value: 10000000
- name: stage_name
tests:
- accepted_values:
values: ['Prospecting','Qualification','Closed Won','Closed Lost']
Step 5, intermediate identity-resolution model.
-- models/intermediate/int_identity_graph.sql
{{ config(materialized='table') }}
WITH all_identities AS (
SELECT email, NULL AS apollo_id, salesforce_contact_id AS sfdc_id, NULL AS hubspot_id
FROM {{ ref('stg_sfdc_contacts') }}
UNION ALL
SELECT email, apollo_id, NULL, NULL
FROM {{ ref('stg_apollo_contacts') }}
UNION ALL
SELECT email, NULL, NULL, hubspot_contact_id
FROM {{ ref('stg_hubspot_contacts') }}
),
canonical AS (
SELECT
MD5(LOWER(TRIM(email))) AS canonical_person_id,
LOWER(TRIM(email)) AS canonical_email,
SPLIT_PART(email, '@', 2) AS domain,
MAX(apollo_id) AS apollo_id,
MAX(sfdc_id) AS sfdc_id,
MAX(hubspot_id) AS hubspot_id
FROM all_identities
WHERE email IS NOT NULL
GROUP BY 1, 2, 3
)
SELECT * FROM canonical
Step 6, mart model joining against the identity graph.
-- models/marts/mart_lead_scoring.sql
{{ config(materialized='table', cluster_by=['scored_at']) }}
WITH email_engagement AS (
SELECT canonical_person_id,
COUNT(*) AS emails_opened,
MAX(opened_at) AS last_opened_at
FROM {{ ref('int_email_opens') }}
GROUP BY 1
),
site_visits AS (
SELECT canonical_person_id,
COUNT(*) AS pageviews,
MAX(visited_at) AS last_visited_at
FROM {{ ref('int_site_visits') }}
GROUP BY 1
),
deal_signal AS (
SELECT canonical_person_id,
SUM(opportunity_amount) AS open_pipeline
FROM {{ ref('int_open_opportunities') }}
GROUP BY 1
)
SELECT
g.canonical_person_id,
g.canonical_email AS contact_email,
g.domain,
COALESCE(e.emails_opened, 0) AS emails_opened,
COALESCE(v.pageviews, 0) AS pageviews,
COALESCE(d.open_pipeline, 0) AS open_pipeline,
-- Simple scoring formula
(LEAST(COALESCE(e.emails_opened,0), 20) * 1.0
+ LEAST(COALESCE(v.pageviews,0), 50) * 0.5
+ LEAST(COALESCE(d.open_pipeline,0)/10000, 100) * 2.0) AS lead_score,
CURRENT_TIMESTAMP() AS scored_at
FROM {{ ref('int_identity_graph') }} g
LEFT JOIN email_engagement e USING (canonical_person_id)
LEFT JOIN site_visits v USING (canonical_person_id)
LEFT JOIN deal_signal d USING (canonical_person_id)Step 7, Elementary anomaly detection (in dbt_project.yml).
# dbt_project.yml (Elementary config)
vars:
elementary:
test_default_config:
severity: warn
anomaly_score_threshold: 3
days_back: 14
models:
elementary:
+schema: elementary-- models/marts/schema.yml (Elementary tests)
models:
- name: mart_lead_scoring
tests:
- elementary.volume_anomalies:
time_bucket: {period: day, count: 1}
sensitivity: 3
- elementary.freshness_anomalies:
time_bucket: {period: hour, count: 1}Step 8, the daily Slack digest query.
# slack_digest.py
import snowflake.connector
from slack_sdk import WebClient
def daily_digest():
rows = snowflake.cursor().execute("""
SELECT
COUNT(*) FILTER (WHERE lead_score >= 80) AS hot_leads,
COUNT(*) FILTER (WHERE lead_score BETWEEN 50 AND 79) AS warm_leads,
SUM(open_pipeline) AS total_pipeline,
COUNT(DISTINCT domain) AS active_accounts
FROM analytics.marts.mart_lead_scoring
WHERE scored_at >= CURRENT_DATE() - 1
""").fetchone()
msg = format_digest(rows)
WebClient(token=SLACK_TOKEN).chat_postMessage(channel="#revops", text=msg)
Production Challenges and Decisions
Schema drift across 7 sources (silent, vendor-driven). Fix:
_raw_payloadpattern. Known fields extracted in the staging model. Unknown fields preserved as a JSON column. Nightly Elementary job samples unknowns and alerts on new keys.Webhook retries from Brevo and HubSpot causing duplicates (2-3x on roughly 5 percent of events). Fix: idempotency at Lambda layer using S3 conditional PUT with
IfNoneMatch="*". Atomic dedup at the edge.Snowflake cost spikes on weekly attribution aggregates. The attribution mart on a large warehouse cost $400 per month alone. Fix: per-model warehouse sizing. XS for staging, S for intermediate, M for the attribution mart. Result: $90 per month with a 30 percent runtime increase. Latency was not critical.
PII surfacing unexpectedly in support free-text fields where customers typed phone numbers. Fix: regex scan plus pre-emptive column masking via Snowflake masking policies. Unmask only for the compliance role.
Late-arriving GA4 data (24-hour batch delay). Fix: 7-day look-back window on the GA4 incremental model plus daily reconciliation that retroactively updates prior-day rows.
Cross-source identity resolution (same human, 4 different IDs across systems). Fix: identity graph mart using
MD5(LOWER(TRIM(email)))as canonical key. False-positive rate around 3 percent, accepted because the manual cross-system alternative does not scale.Why Snowflake over Databricks for this pipeline: auto-suspend warehouses gave the lowest ops burden for the daily cadence. dbt-snowflake adapter was the most mature at decision time.
Why dbt Core not dbt Cloud: cost. Core ran cleanly under Airflow MWAA plus Cosmos. Power User for dbt in VS Code closed most of the IDE gap.
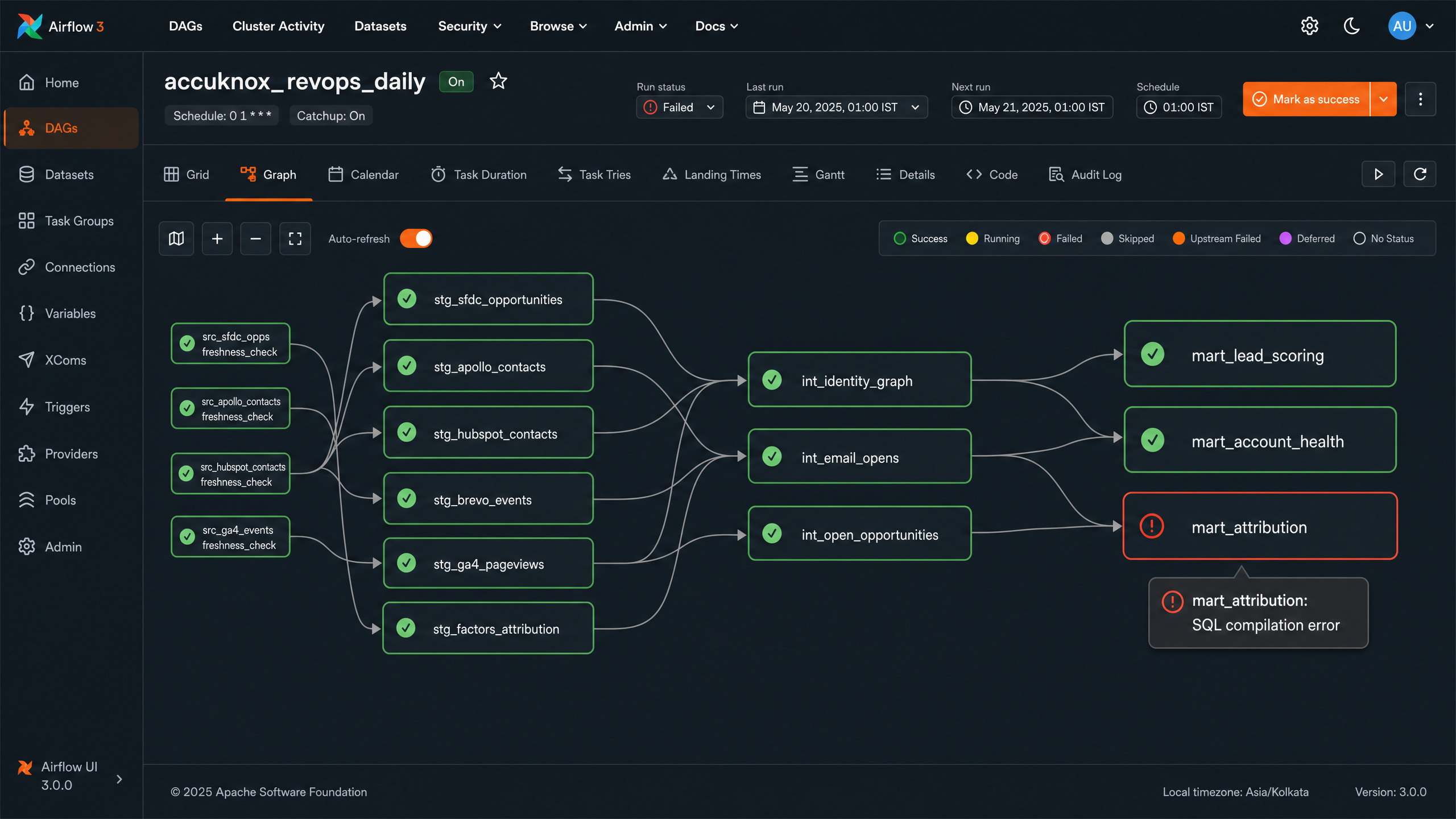
Why Cosmos over BashOperator: per-model task granularity. A failure on the attribution mart retries only that model, not the upstream 50 models.