

How AI Learned to Generate Video
Three years ago, AI couldn't generate five seconds of coherent video. Today it generates photorealistic clips indistinguishable from reality. Let's see how.


In 2025, for the first time, AI-generated video became indistinguishable from reality.
Three years ago, AI video meant flickering frames, morphing faces, and physics-defying motion. Today it means 4K footage with perfect physics, synced audio, and coherent motion across time.
The gap between those two states isn’t incremental. It’s exponential.
The Core Problem: No Memory
Early AI video generation failed because the models had no memory.
They could generate beautiful individual frames. But each frame was independent. The model didn’t remember what it had just created. So objects changed shape between frames. Lighting shifted randomly. People teleported mid-walk.
This is called the temporal coherence problem. Without memory across frames, you can’t have consistent motion.
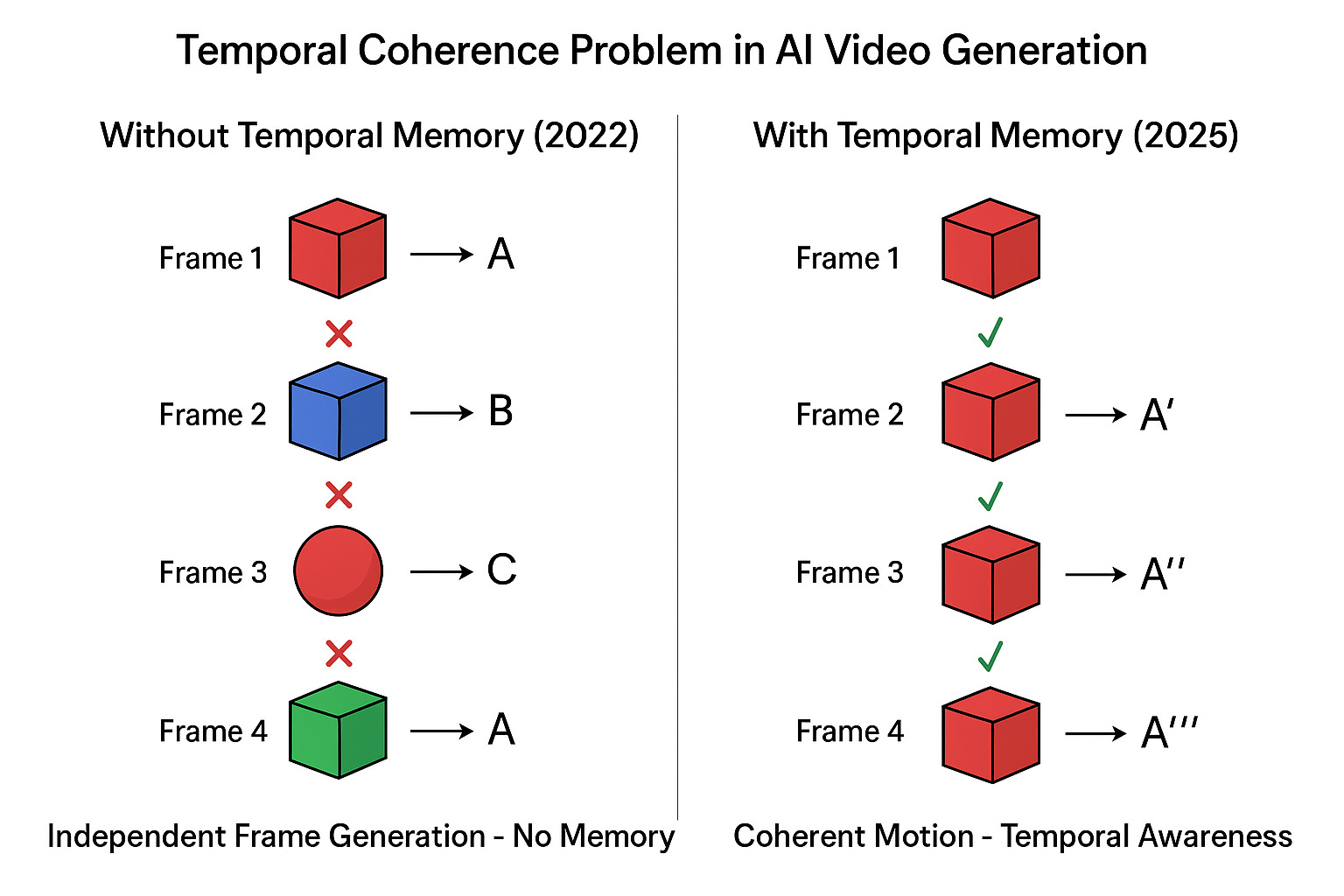
The solution required three major breakthroughs.
Breakthrough #1: Treating Time as a Dimension
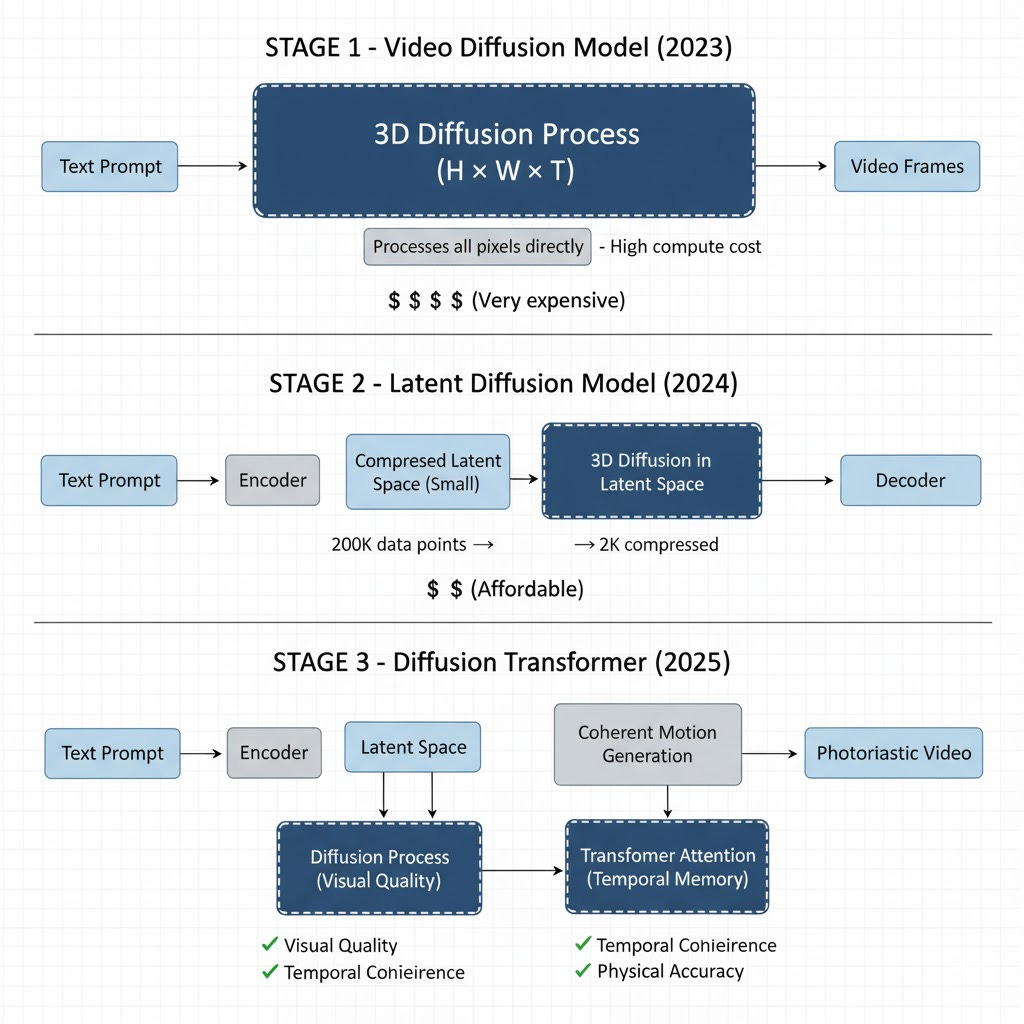
Video Diffusion Models made the first leap in 2023.
Previous approaches generated frames one at a time. VDMs treated video as a 3D cube: height, width, and time. The diffusion process operated across all three dimensions simultaneously, giving the model basic motion continuity.
The problem: computational cost.
A 16-frame clip at 64×64 resolution required processing 200,000 data points. Scale to HD and a single video could consume an entire data center’s compute power.
The concept worked. The cost didn’t.
Breakthrough #2: Latent Space Compression
Latent Diffusion Models solved the compute problem in 2024.
Instead of processing millions of pixel values directly, these models first compress video into latent space—a compact representation that captures the scene’s structure, motion, and texture at a fraction of the size.
The analogy: instead of editing every pixel of a photo, you edit adjustment layers that affect the whole image efficiently.
This compression made high-resolution video generation economically feasible. It’s the same principle that made Stable Diffusion possible for images.
Breakthrough #3: Adding Memory With Transformers
The final leap came from merging diffusion models with transformers.
Transformers—the architecture behind GPT—excel at tracking patterns across sequences. When integrated into video generation, they brought temporal awareness.
Now the model could:
Remember how objects looked in previous frames
Track motion consistently
Maintain lighting and physics across time
Predict what should happen next
Diffusion models handle visual quality. Transformers handle memory and continuity.
This combination—called Diffusion Transformers—made truly coherent video possible.
The Current State: Foundation Models
By 2025, these advances converged into Video Foundation Models.
These are large-scale systems trained on millions of hours of real video, designed to generalize across any video generation task. The two leaders are Google’s Veo3 and OpenAI’s Sora 2.
Google’s Veo3 generates 8-second clips in 4K with realistic camera movement and physics. It also generates synchronized audio—sound effects and ambient noise that match the visual scene perfectly.
OpenAI’s Sora 2 focused on physical accuracy. Objects fall with correct acceleration. Shadows follow light sources accurately. Motion obeys real-world physics.
In blind tests, people cannot reliably distinguish Sora 2 clips from real footage.
The Technical Path
Here’s the progression:
2022: Diffusion models master still image generation
2023: Video Diffusion Models add temporal dimension but face cost barriers
2024: Latent Diffusion compresses computation, making scale feasible
2024-25: Diffusion Transformers add memory and temporal coherence
2025: Video Foundation Models achieve photorealistic, physically accurate generation
Each breakthrough solved a specific limitation of the previous approach.
What This Enables
AI video generation isn’t just about creating content. It’s about machines learning to predict and simulate physical reality.
The same systems will power:
Synthetic training data for robotics
Virtual testing environments
Digital twins of physical systems
Rapid prototyping and simulation
When machines can generate physically accurate video, they can simulate “what if” scenarios. That’s not just creative—it’s a form of reasoning about causality and physics.
The Authentication Problem
As synthetic video approaches perfection, we lose the ability to trust visual evidence.
Every improvement in realism makes it harder to distinguish authentic footage from generated content. This creates both creative opportunities and serious challenges for information integrity.
We’re entering an era where seeing is no longer believing.
What Changed
Three years ago, AI couldn’t generate five seconds of coherent video. Today it generates photorealistic clips indistinguishable from reality.
The breakthrough wasn’t one innovation. It was three:
Treating time as a dimension
Computing in compressed space
Adding memory through transformers
The result: applications that can simulate near perfect motion, understand physics and model animations to it to generate a faux reality.
What we do with that capability will define the next decade of visual media.
Man, perfect timing. Was litteraly just thinking about deepfakes in nature docs.
The technical progression is explained cleanly. The trust problem now matters more than quality.