

DAB-Bench Explained: The Multi-Database Benchmark That Tells You What Production AI Really Faces
ADE-Bench dominates the discourse. DAB-Bench measures the harder problem most agents quietly fail. A structured breakdown of what the 60.4% score actually means.


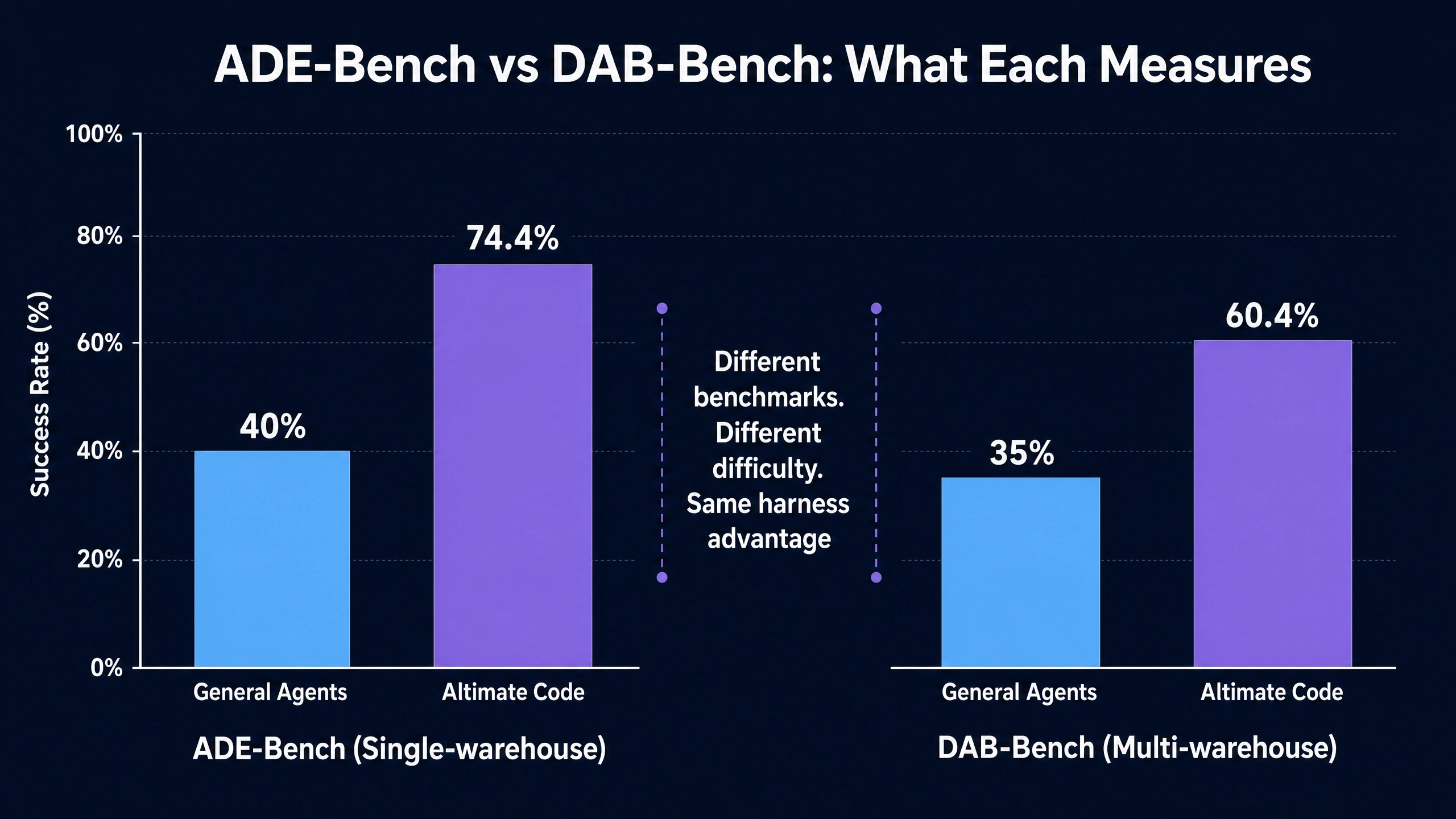
ADE-Bench, dbt Labs’ analytics-engineering benchmark, has become a load-bearing reference point in the AI-for-data conversation in 2026. Altimate AI’s 74.4 percent score on it has traveled through industry newsletters, Hacker News threads, and at least three vendor evaluations the author has seen first-hand. The 35-point gap between Altimate and general-purpose agents is genuinely meaningful, and it is correctly framing the industry conversation about specialized harnesses versus general models.
The benchmark Altimate also reports, the one that gets a single sentence in their launch post and almost no industry coverage, is DAB-Bench. Altimate’s published score on DAB-Bench is 60.4 percent. The general-agent baseline lands in the 30 to 40 percent range. The absolute numbers are lower than ADE-Bench. The relative gap remains substantial.
DAB-Bench is the harder benchmark. It measures a different and more demanding shape of work. For organizations running data infrastructure that touches more than one warehouse, which is most enterprise data environments by 2026, DAB-Bench is the more directly relevant performance signal.
This analysis decomposes what the benchmark measures, why it is harder, what general agents fail on, and how buyers should weight benchmark numbers when evaluating AI tooling.
Why Benchmarks Shape the Field
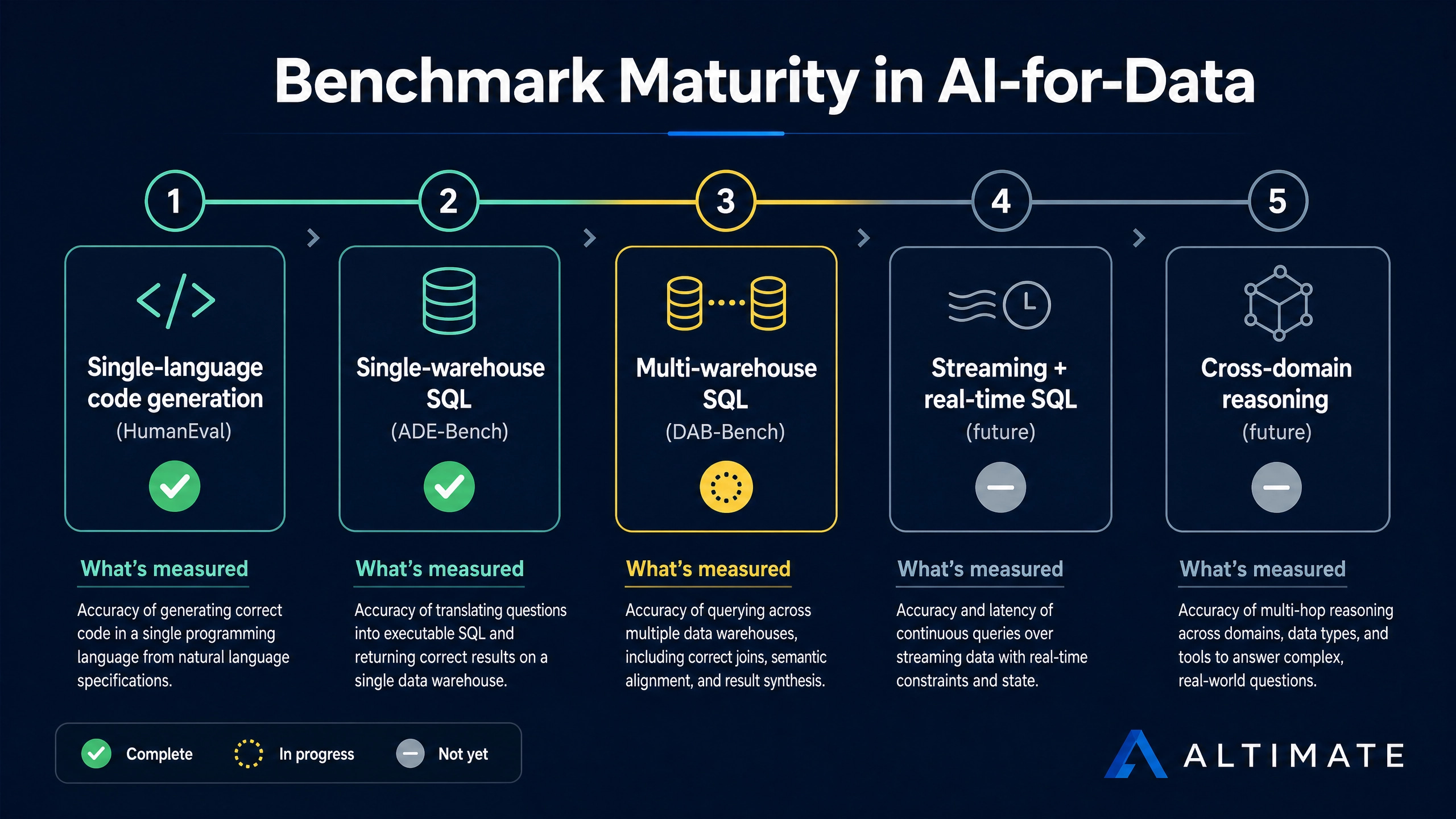
Before decomposing DAB-Bench, a meta-observation. Benchmarks are imperfect signals. They are gameable. They drift from real-world relevance over time as agents optimize against them. SWE-Bench from Princeton helped define what “AI for software engineering” means by establishing a measurable target. HumanEval shaped a generation of code generation models and is now mostly a victory lap because every frontier model scores above 90 percent.
Benchmarks shape what gets built because they are how the field measures progress. The choice of benchmark establishes the implicit definition of “good.” If the benchmark only measures single-warehouse single-dialect single-language tasks, the tools optimized against it will be good at single-warehouse work and weak at heterogeneity. If the benchmark measures cross-warehouse heterogeneity, the tools optimized against it will get good at heterogeneity.
ADE-Bench and DAB-Bench are the two benchmarks shaping the AI-for-data category in 2026. They are different benchmarks measuring different problems. The difference matters for buyers and for builders.
ADE-Bench in Detail
ADE-Bench, the Analytics Data Engineering Benchmark, was built by dbt Labs and published alongside their own analytics-engineering agent work. The test environment is a dbt project sitting on a single warehouse, typically Snowflake. The tasks are realistic analytics-engineering operations: add a new model, refactor a CTE chain, debug a failing test, generate documentation, write a snapshot, add a relationship test.
Scoring is per-task, pass or fail, weighted by complexity. The benchmark publishes the suite of tasks publicly. Vendors run their agents against the suite and report results. Results are comparable in principle across vendors who run honestly.
The strength of ADE-Bench is realism inside a homogeneous environment. The tasks look like what an analytics engineer actually does on a Tuesday: small, focused, requiring deep understanding of a single dbt project against a single warehouse. The benchmark surfaces real failure modes (phantom columns, missing tests, broken refs) that general agents demonstrably fail.
The weakness of ADE-Bench is the homogeneous environment. The benchmark does not test what happens when data lives across three warehouses, when dialects disagree, when lineage crosses platform boundaries, or when the agent must reconcile schemas that represent the same business concept differently in different systems.
That gap is where DAB-Bench operates.
DAB-Bench in Detail
DAB-Bench, the Distributed Analytical Benchmark, was published by Altimate alongside Altimate Code. It is less open than ADE-Bench: the precise task suite is documented in Altimate’s launch material but not as readily reproducible by independent teams. This is a real critique that affects how the numbers should be weighted, and it is addressed in the buyer-evaluation section below.
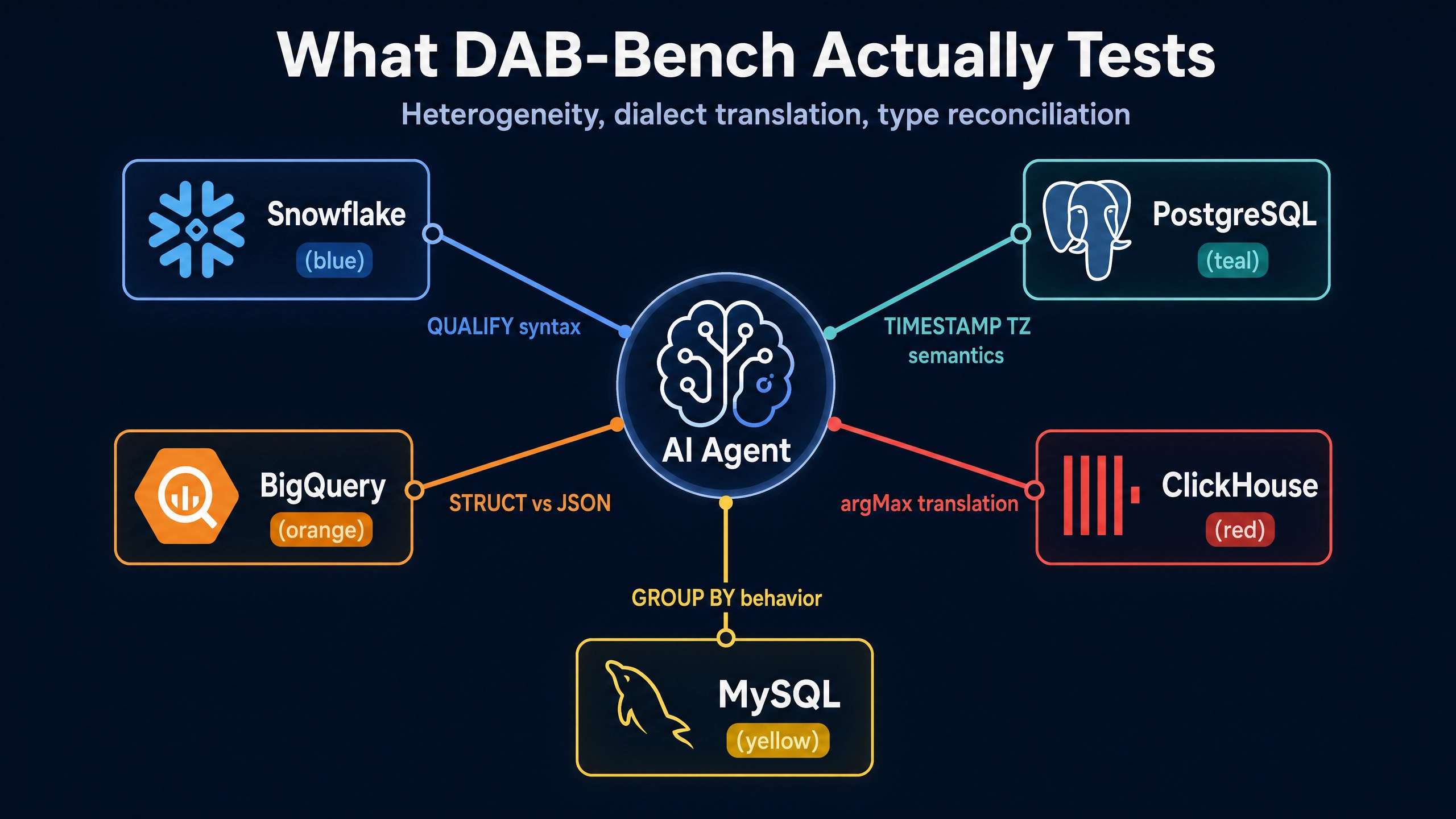
The benchmark environment spans multiple warehouses simultaneously. Tasks pull data from Snowflake, PostgreSQL, BigQuery, ClickHouse, and MySQL, sometimes within a single task. The agent must understand dialect differences, schema variations, type system disagreements, and the basic fact that not every warehouse has every feature available.
Representative tasks (inferred from Altimate’s published material, since the full suite is not as openly distributed as ADE-Bench):
Translate a ClickHouse
argMax(value, key)aggregate to a Snowflake equivalent. The Snowflake-correct approach usesQUALIFY ROW_NUMBER() OVER (PARTITION BY ... ORDER BY ... DESC) = 1or a window function with aLIMIT. The pattern-matching wrong answer appliesMAX(value)and loses the key information.Build a federated query that joins a customer dimension in PostgreSQL to a fact table in Snowflake without round-tripping the entire dimension. The correct approach uses a federation layer like Trino, Starburst, or Polaris-mediated Iceberg access. The wrong approach loads the entire customer dimension into Snowflake on every run.
Reconcile schema disagreements when a column is named
created_atin one warehouse andcreation_datein another but represents the same business event. The correct approach requires inspecting both schemas, confirming semantic equivalence, and producing a unified view. The wrong approach picks one name and silently drops the other warehouse’s data.Write a backfill script that handles the daylight-saving boundary differently across regions stored in different warehouses. The correct approach inspects each warehouse’s timezone conventions and applies appropriate conversions. The wrong approach assumes UTC throughout and produces silently incorrect aggregates for regional reports.
Scoring on DAB-Bench is more nuanced than on ADE-Bench. Partial credit is given for tasks that produce the right shape but miss an edge case. Penalty is applied for tasks that look correct but silently produce wrong results, which is the failure mode that most damages production data.
The 60.4 Percent Number, Decoded
Altimate Code’s reported 60.4 percent on DAB-Bench, against a 30 to 40 percent baseline for general agents, deserves precise interpretation.
The headline reading is that specialized harnesses meaningfully outperform general agents on multi-warehouse work, but the absolute performance ceiling on this category of task is much lower than on single-warehouse work. Both observations are correct and both are operationally relevant.
The 35-point gap on ADE-Bench (74.4 percent vs 40 percent baseline) collapses to a 20 to 25-point gap on DAB-Bench. The gap is still substantial but narrower. The narrowing reflects the fact that heterogeneity introduces failure modes that even strong specialized harnesses do not fully handle yet. Dialect translation rules are imperfect at the edge cases. Schema reconciliation requires business context that no automated tool can fully infer. Cross-warehouse federation is a moving target as warehouses ship new features and as the Iceberg ecosystem matures.
The 60.4 percent absolute number is not a victory lap. It is an honest signal that production multi-warehouse work in 2026 still requires human review on the harder cases, even when using the strongest available harness. Buyers should plan staffing and processes accordingly.
Failure Modes General Agents Exhibit on DAB-Bench
Three failure modes recur across general-agent runs on DAB-Bench tasks, each instructive for understanding the difficulty.
Dialect translation when the source dialect has a feature the target dialect does not. ClickHouse’s argMax does not have a direct one-token equivalent in Snowflake. The general agent has to recognize the semantic intent (find the value of column B in the row where column A is maximum), produce a Snowflake query using QUALIFY ROW_NUMBER() OVER (...) = 1, and verify the result matches semantically. General agents tend to pattern-match argMax to MAX or to a misuse of GREATEST, both of which compile but return wrong results.
Schema reconciliation when column types disagree subtly. PostgreSQL stores timestamps as TIMESTAMP WITH TIME ZONE with one set of semantics. Snowflake’s TIMESTAMP_TZ has different semantics around timezone storage and arithmetic. ClickHouse’s DateTime64(3) is again different and does not represent timezone at all. When the agent joins or unions across these, type coercion happens automatically and silently. The query compiles. The query also returns wrong rows. Specialized harnesses catch this through deterministic type-checking. General agents do not.
Cross-database joins where the agent does not know whether a federation layer exists. If the customer team uses Trino or Starburst to federate Snowflake plus PostgreSQL, the agent can write a federated query that runs through the federation engine. If the customer team has no federation layer, the agent must extract one side and load it into the other warehouse first. General agents tend to assume the federation exists when it does not, producing queries that fail at runtime in ways that are difficult to debug.
These failure modes are not edge cases. They are the structure of real multi-warehouse work in 2026. Organizations whose data has accumulated across multiple platforms (typical for any company past Series B) encounter all three patterns regularly.
How Benchmark Numbers Should Be Read Critically
When a vendor publishes benchmark numbers, four questions sharpen the interpretation.
Who built the benchmark? A benchmark built by an independent third party is more credible than one built by the vendor itself. ADE-Bench was built by dbt Labs, which is independent of Altimate. DAB-Bench was built by Altimate. This does not invalidate Altimate’s reported number, but the reader should weight it differently. Third-party reproduction would meaningfully strengthen the claim.
Is the test suite public? A public, reproducible benchmark allows independent runs. ADE-Bench is more open in this regard. DAB-Bench is less open. The path forward for the field is for DAB-Bench to either become public or to be supplemented by an open multi-warehouse benchmark from another organization.
What is the control? The general-agent baseline matters. Altimate’s published baseline is “general agents land in the 30 to 40 percent range.” That is a credible comparison if the baseline ran on the same task suite with comparable prompting and tool access. Without independent verification, readers extend good-faith but should note the assumption.
Does the benchmark measure what production cares about? A benchmark that gives full credit for “the SQL compiled” is too easy. A benchmark that requires “the SQL is semantically equivalent to a reference implementation” is harder and more useful. DAB-Bench’s penalty for silent wrong results moves it toward the harder side. ADE-Bench’s per-task pass/fail scoring is somewhere in between.
For organizations evaluating AI tooling vendors, the right move is to ask the vendor for their benchmark methodology, the public availability of the suite, the control group used, and whether the numbers have been reproduced externally. Most vendors will answer these questions honestly. Vendors who deflect are the ones to skip.
What DAB-Bench Should Evolve Into
Three changes would meaningfully raise the credibility and utility of DAB-Bench as the field matures.
Public dataset and reproducibility. The task suite should become open like ADE-Bench. Independent researchers should be able to reproduce the numbers. If Altimate Code’s 60.4 percent holds under independent runs, the credibility increases substantially. If it does not, the field learns useful detail about where the harness’s limits are.
Versioning for longitudinal tracking. Benchmarks should be versioned so the field can track agent progress over time. DAB-Bench v1 versus v2 versus v3, with the v1 suite preserved for comparability. Without versioning, every claimed improvement is hard to attribute precisely.
Expanded dialect coverage, especially legacy. The current scope (Snowflake, PostgreSQL, BigQuery, ClickHouse, MySQL) covers most modern use cases. Adding Oracle, DB2, SAP HANA, and Teradata would extend the benchmark into the enterprise migration cases where AI tooling carries the most economic weight. An agent that handles Oracle-to-Snowflake migration well is worth real money to a meaningful number of Fortune 1000 companies.
Streaming and real-time tasks. Both ADE-Bench and DAB-Bench currently test batch tasks. The next frontier is streaming SQL on event data, which has different correctness properties (windowing semantics, late-arriving data, out-of-order processing). A future benchmark that covers Materialize, Flink SQL, RisingWave, and Snowflake/Databricks streaming primitives would extend relevance significantly.
What This Means for Buyer Stack Decisions
For organizations choosing AI tooling against a single-warehouse stack (all-Snowflake or all-Databricks with dbt as the transformation layer), ADE-Bench is the relevant benchmark. The 74.4 percent number meaningfully describes how the agent will perform on representative work.
For organizations choosing AI tooling against a heterogeneous stack (data in Snowflake, PostgreSQL for operational systems, ClickHouse for product analytics, BigQuery in an acquired subsidiary), DAB-Bench is the relevant benchmark. The 60.4 percent number describes that the agent handles cross-warehouse work better than a generic agent, but neither category is fully mature yet. Plan for human review on the harder cross-warehouse cases.
For organizations building AI tooling, both benchmarks matter as different signals. ADE-Bench shows whether the harness handles the common case. DAB-Bench shows whether the harness handles the cases that cost real money when they fail.
The strategic question for AI tooling buyers is not “which benchmark do you score highest on?” The strategic question is “which benchmark most closely models the work my team actually does?” That question forces honest evaluation of both vendor claims and internal infrastructure choices.
The Strategic Takeaway
Benchmarks are imperfect, gameable, and time-bounded. They remain the closest thing the field has to evidence-based evaluation, which is why they matter for buyers and builders alike.
ADE-Bench established that specialized SQL agents are meaningfully better than general agents on single-warehouse analytics-engineering work. The discourse has correctly absorbed this.
DAB-Bench is establishing that specialized agents are still meaningfully better than general agents on multi-warehouse work, but the absolute performance ceiling on multi-warehouse work is much lower, and the gap between specialized and general agents is narrower. The discourse has not yet absorbed this fully.
For data engineering teams running heterogeneous infrastructure, the operational implication is concrete. Adopt the strongest specialized harness available, expect a 60 percent baseline on cross-warehouse work, plan for human review on the residual 40 percent, and track DAB-Bench-style numbers as the relevant performance signal over time.
The benchmark conversation in 2026 needs to mature beyond ADE-Bench. Buyers who only pay attention to the higher number are reading the easier benchmark. The harder benchmark is the one that tells you what production work will actually look like.