

Claude Code vs Altimate Code on a 200-Model dbt Project: Where Generalist Agents Break
A side-by-side analysis on a real analytics codebase. Same LLM, same prompt, dramatically different outcomes. The harness is the variable.


The discourse on AI coding agents has converged on a comfortable narrative: the next model release will close the remaining gaps. Claude 4.7 will be better than 4.6. GPT-5.2 will be better than 5.1. The 70-percent benchmark scores will become 80-percent scores.
For domains with verifiable ground truth, that narrative is incomplete. Foundation model improvements have been compounding at roughly 5 to 10 percentage points per major release on canonical benchmarks. Domain-specific tooling improvements have been compounding at 25 to 35 percentage points on the same benchmarks. The model is the multiplier. The harness is the variable.
The most instructive way to see this gap is on a real production codebase. Below is a structured comparison of Claude Code and Altimate Code on a representative 200-model dbt project, both running on top of Claude Sonnet, both given identical prompts. The differences are not theoretical.
The Test Codebase
The test ran against a 200-model dbt project representative of a mid-stage B2B SaaS analytics stack. Three-tier organization: staging, intermediate, marts. Forty custom macros. Snowflake backend. Active in production with a real warehouse, real downstream BI consumers, and real lineage that crosses three dbt projects via dbt Mesh.
The prompt given to both agents was a standard request that an analytics engineer would receive in a Tuesday standup:
“Add a new mart called
fct_customer_health_scorethat combines order frequency, support ticket count, and NPS into a single score. Include tests.”
Both agents had read access to the dbt project, write access to the SQL and YAML files, and the ability to run dbt build to verify their output. The prompt allowed multi-step execution and gave the agents authority to refactor adjacent models if needed.
Claude Code, Naked
Claude Code produced a working fct_customer_health_score.sql model on the first attempt. The model compiled. The downstream dbt build ran green. The schema.yml entry included not_null and unique tests on the primary key. On surface inspection the work looked complete.
Detailed review surfaced four failure modes characteristic of generalist agents operating on production data.
Phantom column reference. The model joined to
support_tickets.priority_level. No such column exists in the source. The actual column ispriority. Claude inferred a more “obvious” column name from the join context, the warehouse accepted the SQL because the joined CTE happened to alias the column lazily, and the join silently returned null for every row. Every customer in the resulting fact had a health score that ignored support priority. The downstream dashboard would look correct and be wrong.Silent wrong join. The model joined
orderstocustomersoncustomer_id. Both tables have that column name. The values are semantically incompatible:orders.customer_idstores the external Stripe customer ID as varchar,customers.customer_idstores the internal numeric ID as integer. The join compiled because of implicit type coercion. About 80 percent of resulting rows contained incorrect data because most external IDs match by coincidence on integer parsing of the leading digits.Tests that did not catch the bugs. The auto-generated
not_nullanduniquetests passed. Neither would have caught the phantom column or the silent wrong join. Norelationshipstest linked the fact’scustomer_idto the customer dimension. No row-count regression test compared output volume against historical norms. Noaccepted_valuestest validated the score range.Destructive operation proposed without lineage check. A follow-up prompt asking to “clean up the staging models that feed this fact” produced a recommended
DROP TABLE IF EXISTSagainststg_orders_raw. The staging table is depended on by two other marts. Claude Code did not know that because the lineage was not in its context. With auto-execute enabled in the IDE, the DROP would have run.
Each of these failure modes is documented in Altimate’s published research. The aggregate published claim is that 78 percent of AI-generated SQL errors are silent wrong joins, and 27 to 33 percent of AI-generated SQL references nonexistent tables. The 200-model test reproduces both categories within a single task.
Altimate Code, Same Task
Altimate Code received the identical prompt against the identical codebase, running on the same Claude Sonnet backend. The behavioral differences map directly to the deterministic harness layer.
Schema introspection before SQL generation. Before composing any model SQL, Altimate’s harness invoked a schema-fingerprint scan against the source tables. The scan returned the actual column names with their types. The first-draft model used priority, not priority_level, because the LLM had ground-truth schema in context rather than inferred guesses.
Lineage-aware change recommendations. When the follow-up prompt requested cleanup of staging models, Altimate’s harness ran a blast-radius analysis against the lineage graph. The output enumerated every downstream model touching the staging table targeted for cleanup, including the two marts that depend on it. The agent surfaced the dependency as a confirmation requirement before any destructive operation could execute.
Type-aware join validation. When the model SQL referenced orders.customer_id = customers.customer_id, the harness invoked a type-checking tool that compared column types across the join. The check returned a warning that orders.customer_id is varchar and customers.customer_id is integer, with a recommendation to cast both sides explicitly or join on a verified bridge column. The corrected SQL used the proper foreign key with appropriate casting.
Test generation grounded in lineage. The auto-generated test suite included a relationships test linking the fact’s customer_id to the customer dimension, a row-count guard comparing output volume to a historical baseline, and an accepted_values test bounding the score range to a valid window. These tests would have caught the failure modes that Claude Code’s tests missed.
The output is meaningfully different. Both agents used the same LLM. The variable is the deterministic tooling layer wrapping the LLM.
The Architecture Behind the Difference
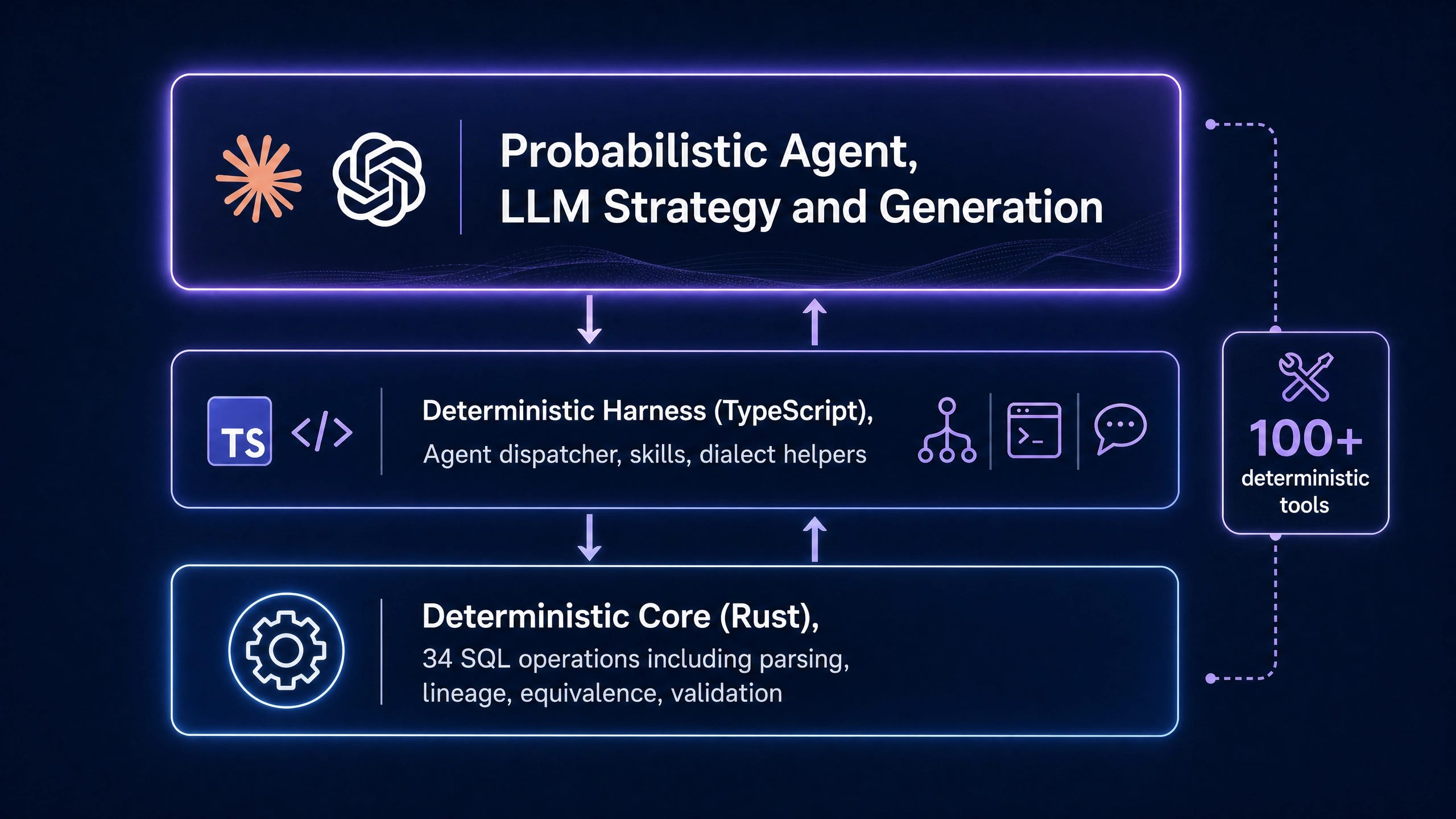
Altimate Code’s published architecture is a three-layer stack. The top layer is the probabilistic agent: the LLM that plans, generates, and integrates. The middle layer is the deterministic harness in TypeScript: the agent dispatcher, skill prescriptions, dialect-aware helpers, and the tool routing system. The bottom layer is the deterministic core in Rust: 34 SQL operations as pure functions covering parsing, validation, transpilation, equivalence checking, and lineage extraction.
The architectural insight is that LLM reasoning and deterministic verification are different operations and should be implemented in different layers. When the agent needs to know whether a column exists, it does not ask the LLM. It calls the schema-introspection tool, which returns a correct answer in milliseconds. When the agent proposes a SQL rewrite, the harness invokes the equivalence-checking engine before suggesting the rewrite to the user.
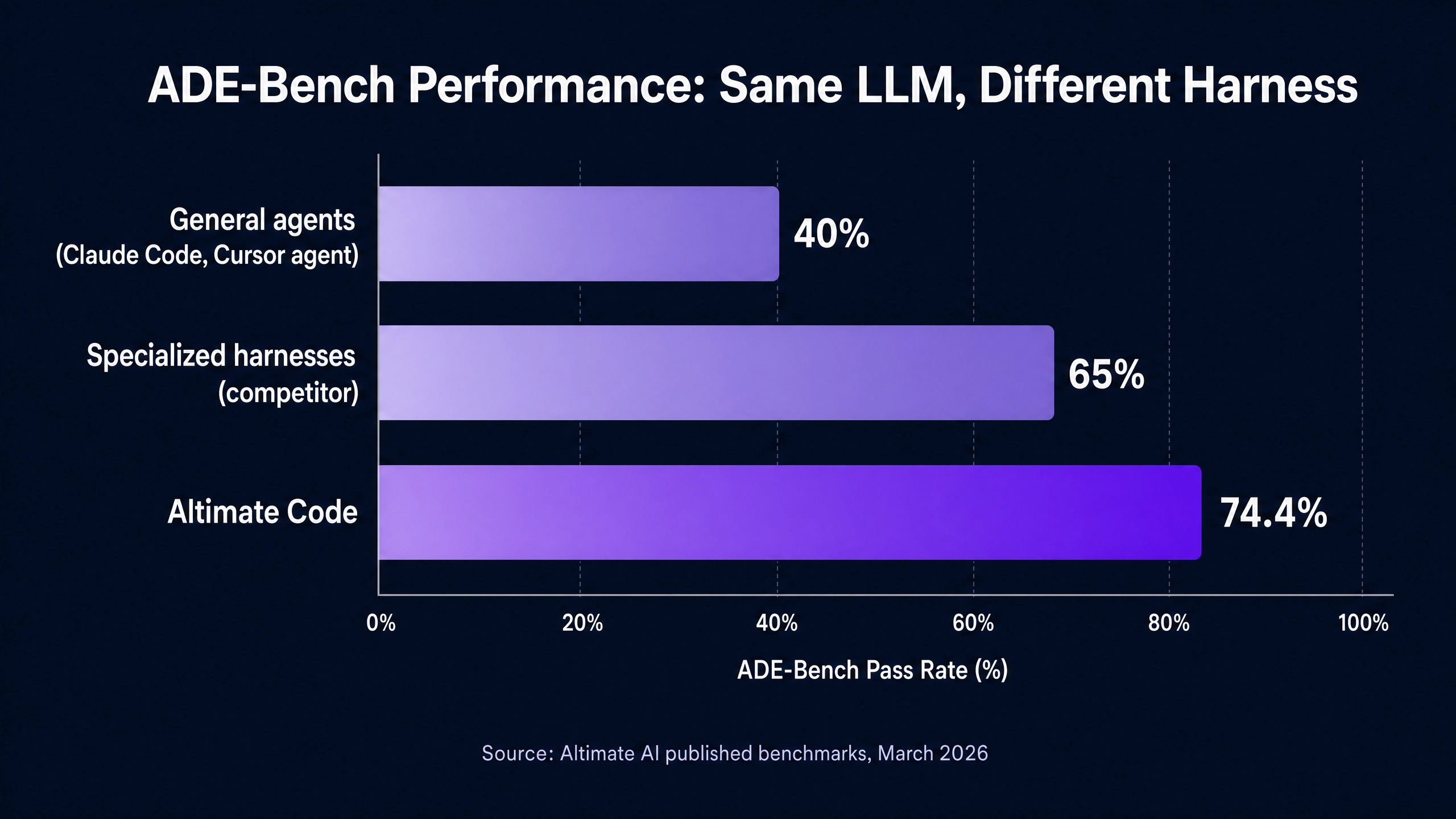
This separation explains the benchmark gap. On ADE-Bench, dbt Labs’ analytics-engineering agent benchmark, Altimate Code reports 74.4 percent. The nearest specialized competitor reports approximately 65 percent. General-purpose agents on the same task surface land in the 40 percent range. The 35-point gap is not a model gap. It is a tooling gap.
On DAB-Bench, the multi-database benchmark Altimate published alongside Altimate Code, the harness reports 60.4 percent against a baseline of 30 to 40 percent for general agents. The lower absolute number reflects the harder nature of cross-warehouse tasks. The relative gap remains substantial.
For context, Snowflake’s own Cortex Analyst, the in-warehouse text-to-SQL agent, was reported by Altimate to achieve 38 percent logical accuracy on their internal benchmark. The published numbers from Snowflake position Cortex Analyst as conversational analytics, not engineering-grade SQL generation. The architectural choice (in-warehouse, single-vendor, schema-grounded against a semantic model) optimizes for a different use case than agentic dbt development.
What “Agentic Harness” Actually Means
The word “agentic” has been overloaded by 2026. A precise definition matters for evaluating tools.
An agentic harness is a system where an LLM plans, calls tools that return ground-truth answers, observes the outcomes, and iterates without human approval on each intermediate step. The harness is the layer of deterministic tooling and orchestration logic surrounding the LLM. The LLM provides strategy. The harness provides verification.
For SQL work specifically, the deterministic tools that matter are schema introspection, column-level lineage, AST parsing and manipulation, dialect translation with rule-based correctness, equivalence checking across query rewrites, anti-pattern detection, PII scanning, and row-level diffing between candidate outputs.
Altimate Code ships more than 100 such tools. Each is callable by the LLM during a task. When the agent encounters uncertainty, it invokes a tool. When a tool flags a problem, the agent rewrites. The orchestration is the product. The LLM is interchangeable.
The interchangeability matters. Altimate Code supports Anthropic, OpenAI, Google, AWS Bedrock, Azure, Ollama, OpenRouter, Mistral, Groq, xAI, and local models. The same harness improves all of them. A cheaper model with the harness outperforms a more expensive model without one. This is consistent with the published thesis from Altimate that “the model is not the bottleneck, the harness is.”
Where the Harness Thesis Generalizes
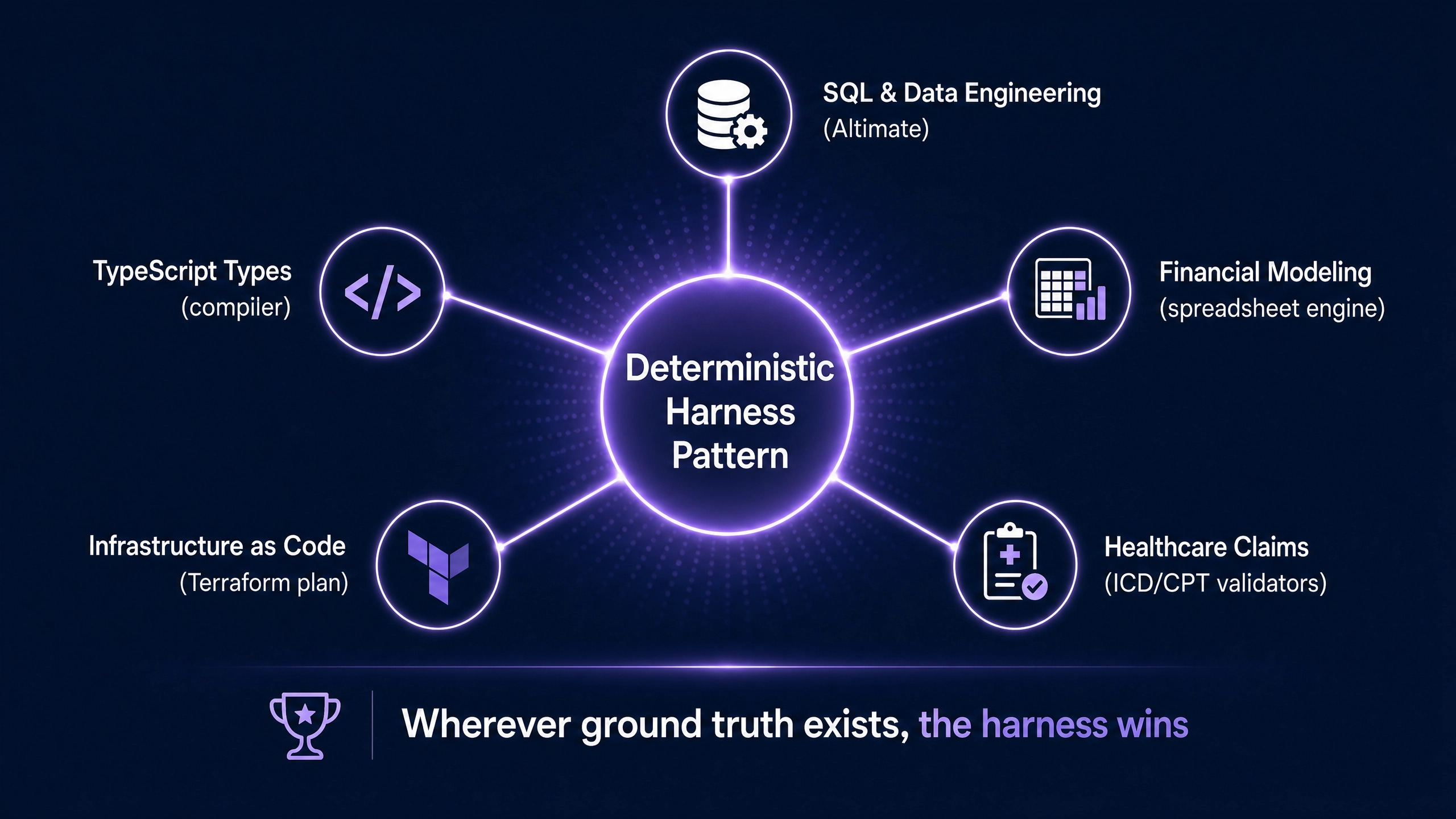
The pattern is not specific to SQL. Any domain with a verifiable substrate benefits from the same architectural pattern: probabilistic strategy on top, deterministic verification underneath.
Type systems in TypeScript or Rust qualify. The compiler is the harness. LLMs integrated with
tscorrust-analyzership better code than LLMs operating on the source text alone.Financial modeling qualifies. Spreadsheet equations have ground truth. LLMs that can call a deterministic spreadsheet engine before suggesting changes produce fewer wrong numbers.
Infrastructure as code qualifies. Terraform plans are deterministic. Agents that can
terraform planbefore suggesting changes produce safer outputs.Healthcare claims qualify. ICD codes, billing rules, formulary checks are all deterministic. Wrapping an LLM around those tools changes outcomes.
In each case the same principle applies: the LLM provides strategy, the deterministic engine provides truth, the combination outperforms either alone. Altimate is the canonical example in the data engineering vertical.
What This Changes for Engineering Teams
The practical implication for teams choosing AI tooling in 2026 is that benchmark selection matters more than model selection. The question to ask vendors is not “which model do you use?” but “what deterministic tools wrap your LLM, and what is the benchmark performance on tasks like ours?”
Five filter questions sort productive vendors from marketing-led ones.
What deterministic tools does the system ship with? A vendor that cannot enumerate their tool set has not built a real harness.
How does the system handle LLM uncertainty? A vendor that returns the LLM’s best guess without verification is shipping a wrapper, not a harness.
What happens when the LLM proposes something demonstrably wrong? A vendor whose system silently propagates LLM errors is unsafe for production data.
Can the customer bring their own LLM? A vendor locked to a single model provider creates portability risk.
What is the published benchmark performance on tasks representative of the customer’s workload? A vendor without benchmarks has not measured itself rigorously.
Altimate Code passes all five filters. Most “AI for data” products today do not.
How Teams Are Actually Adopting the Pattern
The adoption pattern observed across mid-market data teams in 2026 is not “rip and replace.” Most teams continue using Claude Code or Cursor for general engineering work. The agentic harness gets deployed specifically for production data work where the cost of silent errors is high.
The typical pattern is dual installation. Claude Code or Cursor remains the default for application code, infrastructure, internal tooling, and exploratory analytics work. Altimate Code (or the equivalent harness) is installed alongside and is invoked specifically when working on dbt models, warehouse migrations, semantic layer changes, or any work touching production data.
This dual pattern is also what Altimate’s published positioning recommends. The Altimate team has open-sourced 20 plus data-engineering skills for Claude Code, positioning Altimate Code as the specialized companion rather than the replacement. The two products co-exist deliberately.
For teams evaluating the pattern, the practical first step is small. Install Altimate Code alongside the existing Claude Code workflow. Use it on one production dbt PR. Compare the output to what Claude Code alone would have produced. The gap is the value.
The Strategic Takeaway
The competitive frame for AI coding agents in 2026 is shifting from model performance to domain coverage. Generalist agents will remain useful for the broad surface of software engineering. Domain-specialized harnesses will dominate verticals where ground truth exists and silent errors are expensive.
Data engineering is the canonical vertical. SQL has ground truth. Schema is verifiable. Lineage is deterministic. The cost of a silent wrong join making it to production runs from “stakeholder embarrassment” through “incorrect financial reporting” to “regulatory action.” That cost curve is what makes the harness investment economical.
Altimate Code is the most credible specialized harness shipping today. The benchmark gap is real. The architecture is sound. The market position is defensible as long as the gap persists.
For data teams choosing AI tooling, the right move is not to wait for the next model release. The right move is to evaluate the harness layer. The next year of meaningful productivity gain in AI for data engineering will not come from larger models. It will come from better tooling around them.