

Building an AI OS for AccuKnox's Content, Positioning, and Marketing with MagiHQ
Not a tool. Not a workflow hack. A full operating system with mapped ICPs, competitors, knowledge bases, brand rules. Built before a single word was generated.


TL;DR: I did not set up Magi as a prompt box. I set it up as a content operating system. The real work was manual. We had to create the knowledge architecture first: 11 markets, 11 ICPs, 33 personas, competitor context, influencer tracking, reusable source collections, and mandatory SEO frontmatter. At AccuKnox, one thing became obvious fast. Content quality was never the model problem. It was the input structure problem.
Most AI content tools break in the same place.
They start generating before the company has defined what the AI should know.
That gives you the usual sludge. Generic blog posts. Flat LinkedIn copy. Landing pages that mention features without understanding buyers. Email sequences that sound like they were written for a company with no history, no positioning, and no actual market.
That was the setup problem I was solving with Magi for AccuKnox.

The goal was simple.
Take everything the team already knew, structure it manually, and then make it usable by the system.

That meant product context, buyer context, competitor context, transcript context, and publishing rules all had to be manually created, cleaned up, and mapped into a format Magi could actually work with.
, 4 Competitors, and 3 Influencers per market")
What this looked like at AccuKnox
This was never a one off experiment.
Across internal AccuKnox working sessions, three threads kept repeating:
The taxonomy had to be explicit. Market to ICP to persona to knowledge base to ideas.
The publishing standard had to be enforced. Every blog needed a TLDR, frontmatter, FAQ schema, links, structure, and positioning context.
The interface had to match the workflow. Calendar, collections, knowledge views, content generation states, and editor UX all mattered because the team had to use this every day.
One meeting summary described the operating model almost perfectly:
"Take the first cut. I'll fine tune at the very end."
That is how this kind of system should work. The team builds the structure first. The AI handles transformation after that. Human judgment stays at the edges where it belongs.
The core architecture
The entire setup got easier once I stopped thinking about "content" and started thinking about buyer mapped data.
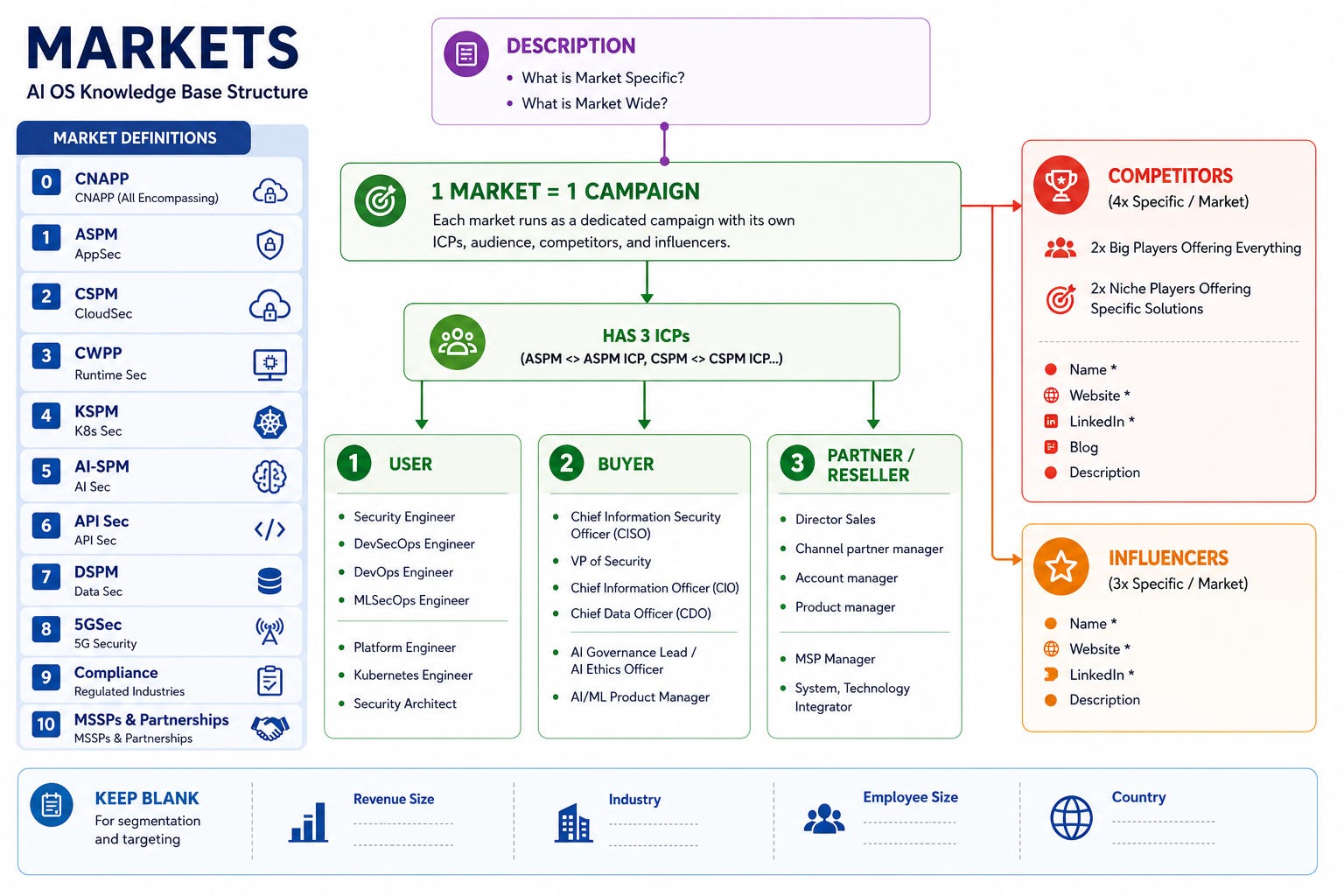

This was the foundation:
1 Market -> 1 ICP -> 3 Personas
That meant:
11 markets
11 ICPs
33 personas
Each persona needed more than a job title.
Each one needed:
A real description
Primary use cases
Pain points
KPIs they are judged on
Enough context for the AI to understand why that person would care
The three ICP types we mapped across every single market:
User (hands-on operators): Security Engineer, DevSecOps Engineer, DevOps Engineer, MLSecOps Engineer, Platform Engineer, Kubernetes Engineer, Security Architect.
Buyer (decision makers with budget): CISO, VP of Security, Chief Information Officer, Chief Data Officer, AI Governance Lead, AI/ML Product Manager.
Partner/Reseller (channel and distribution): Director of Sales, Channel Partner Manager, Account Manager, Product Manager, MSP Manager, System/Technology Integrator.
This looks simple on a whiteboard. It is not simple once you try to operationalize it across CNAPP, ASPM, CSPM, CWPP, KSPM, AI security, API security, DSPM, compliance, 5G security, and MSSP partnerships.
Here is what the full market grid looks like inside Magi once it is properly configured:

Each card is a live campaign anchor. Click into any one and you see the ICP, competitor set, influencers, and persona breakdown for that market specifically.
That is exactly why most teams avoid doing it.
They want the output before they have earned the input.
What went into the knowledge base
The spreadsheet schema was the real product spec.
Magi did not pull any of this in automatically.
We built the knowledge base from scratch. Defined the markets, mapped the ICPs, wrote the personas, organized the collections, decided what belonged where. The system only became useful after that work was done.
Seven layers. Here is what each one actually contained.
1. Personas and campaigns
The personas tab was where everything else downstream got grounded. It mapped:
Market
Persona name
Description
Use case
Pain points
KPIs
This is where generic messaging dies.
Once the AI sees the difference between a CNAPP buyer trying to reduce cloud risk and a hands on platform engineer buried in runtime alerts, the writing changes immediately.
Here is what a fully built-out ICP looks like inside Magi. This is the AI-SPM market with its ICP description, use cases, buying cycle, and three distinct personas mapped:
")
Every persona carries its own context stack. For the AI-SPM User persona alone, that meant: description, use cases, pain points (Shadow AI, No standards, Rapid rollout, Poor visibility, Compliance gaps), and KPIs (AI asset coverage, Policy violations, Risk events, Audit readiness, MTTR). The AI does not guess at any of this. You put it in. The system uses it.
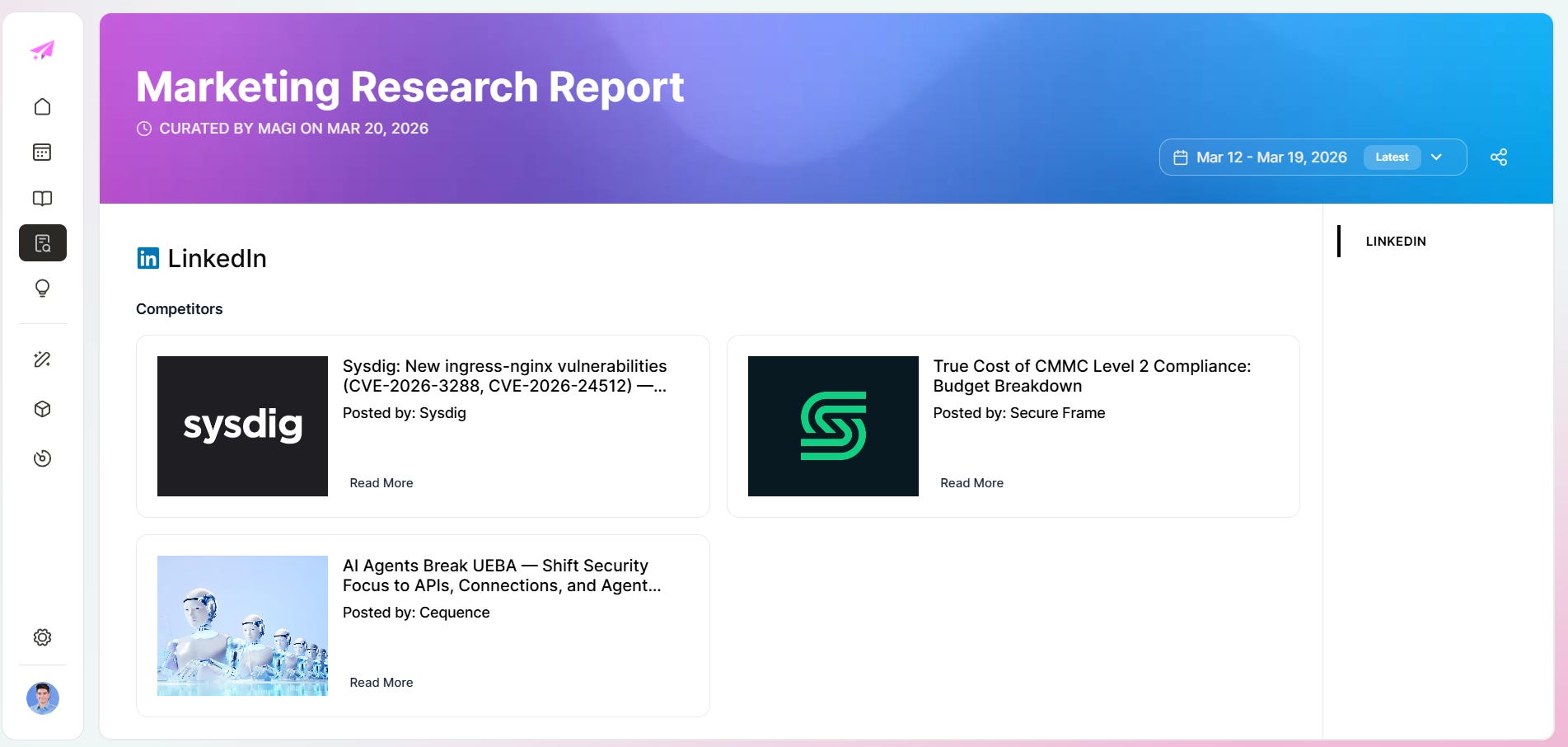
2. Competitors
Every market needed direct competitive context.
The rule we followed: 4 competitors per market. 2 big players offering broad platform coverage. 2 niche players with specific point solutions.
That included:
Name
Website
LinkedIn
Blog
Short positioning summary
The system should know whether it is writing in a market crowded by broad platforms like Wiz and Orca or a tighter category with narrower players.
If the AI has no enemy map, it writes like it has never seen the market before.
Here is what the competitive layer looks like inside a live market. AI-SPM had Protect AI, HiddenLayer, and Robust Intelligence mapped with positioning context for each:

3. Influencers
For each market we tracked 3 people: name, title, LinkedIn. Not for outreach. For signal. When the people closest to a category are writing about their problems, that is free market research. Having a list meant we actually read it instead of browsing randomly and hoping something stuck.
4. Knowledge files
Everything the company already knew that wasn't in a usable format. We pulled in:
FAQs and llms.txt
Whitepapers and eBooks
CVE pages and security advisories
Press releases
Technical documentation and help docs
Playbooks (sales, onboarding, objection handling)
Blog posts (published and competitor)
Slide decks and pitch materials
Important help doc URLs and sitemaps
POC executive summaries
Sales call transcripts and objection logs
This is where transcripts start to matter.
Your company already has a pile of explainers trapped in sales calls, POC conversations, review notes, Slack threads, and internal docs. Your best content usually already exists in conversation form.
But that did not mean Magi automatically understood any of it. We still had to decide what to extract, how to classify it, and where it should live inside the knowledge base. Magi became useful only after that manual setup work was done.
5. SEO frontmatter and brand rules
The difference between content that is readable and content that can actually ship is metadata. We wanted the latter.
That meant every blog needed mandatory metadata and SEO framing at generation time.
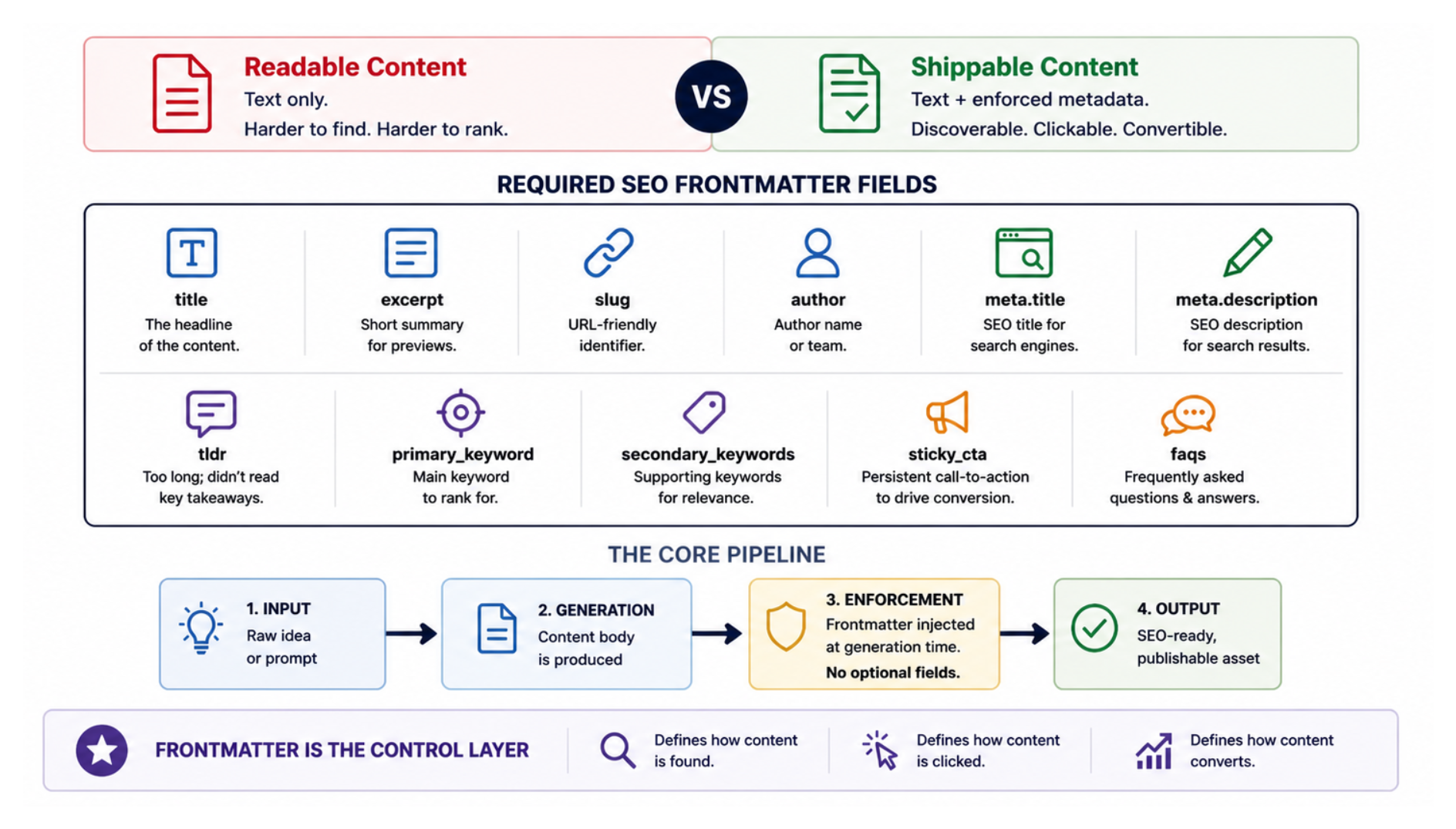
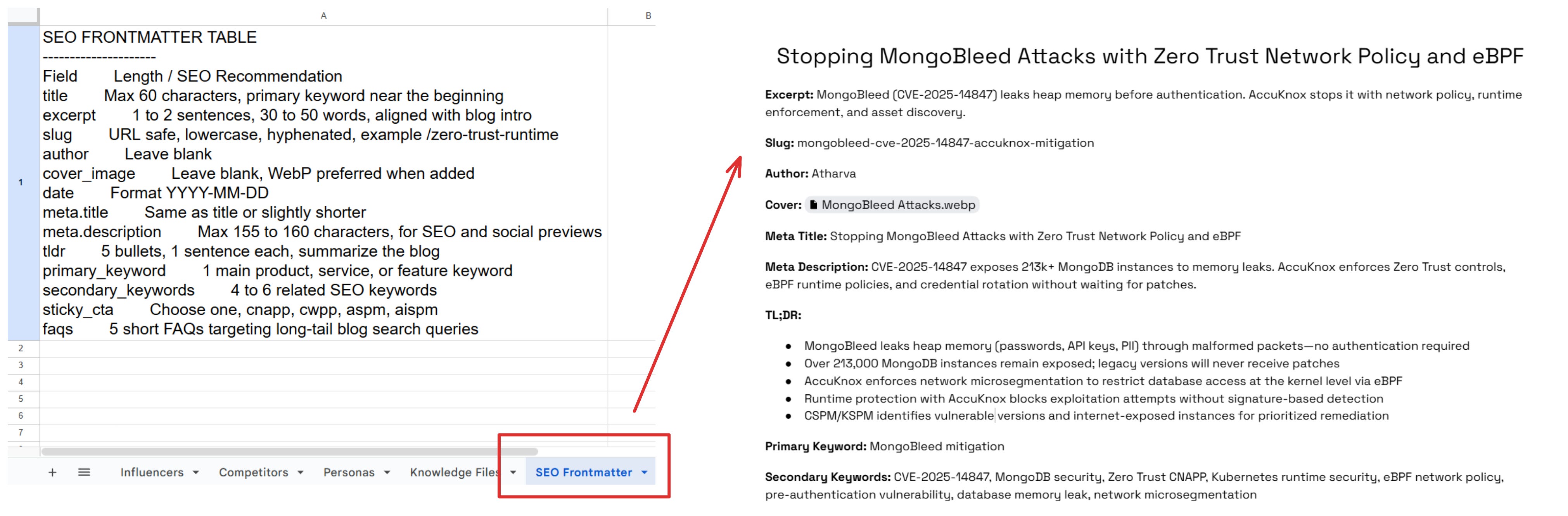
The required fields included:
titleexcerptslugauthormeta.titlemeta.descriptiontldrprimary_keywordsecondary_keywordssticky_ctafaqs
That sounds administrative. It is not.
It changes the entire quality threshold of the output.
Once frontmatter, tone guidance, category rules, and required links are part of the brief, the draft becomes much closer to publishable.
Our internal summaries reinforced this too. The standardized blog framework had 14 mandatory components. That is the real lesson here. Good AI writing systems are held together by checklists.
6. Landing page hierarchy
The landing page tab handled parent and child page relationships.
That was important because page generation without site hierarchy usually creates random one off pages with no connective logic.
We wanted category pages and industry pages to map back to a real information architecture.
7. Map knowledge to campaigns
One practical question: which piece of knowledge belongs to which campaign?
Without that answer, a large source library is just dead storage. With it, Magi could pull the right asset into the right flow instead of surfacing random content and hoping it fit.
Why the transcript layer mattered so much
Companies sit on a ridiculous amount of content that never becomes reusable.
Sales calls
Product demos
Customer questions
Slack clarifications
Internal review comments
Meeting recordings
This setup sharpened that for me.
Our internal call notes and transcript reviews were full of operating detail that rarely makes it into polished docs:
what the team was blocked on
how pages were supposed to be structured
which campaigns were recurring
what design assets were missing
which types of outputs were ready for testing
That is the language people actually use when they explain the business to each other.
That language is worth far more than another generic AI prompt.
But again, the transcripts were input for us first. They helped us understand what the system needed to know. They were not some automatic ingestion shortcut that saved the setup work.
The research layer also powers competitive monitoring. Magi's research reports pull competitor LinkedIn posts, blog content, and CVE coverage into a single view per market. You do not have to browse five different sources manually.

If I were rebuilding this from scratch again, I would still start with transcripts, docs, and source collections before I touched generation settings. Then I would manually map the ICP and knowledge layers before expecting anything useful from the tool.
The product feedback loop with Magi
Getting the architecture right also surfaced what the product still needed. A few things came up repeatedly across working sessions:
A media library for product screens, explainer screens, and carousel assets, so content generation could pull real visuals
More visible workflow stages, specifically In Progress and In Review
A progress bar during generation so the team wasn't staring at a blank screen
A cleaner editor so review didn't feel like a chore
And the parts that were already solid enough to test:
Calendar
Collections
The TOFU blog template
That last list matters. Those aren't cosmetic wins. They're the sign a tool has crossed from demo to daily use.
BrandOS
Once fully set up, your generated content would be a lot more on brand. You'd also be able to switch between different voices, tones, and keywords for each content piece you create. The system lets you configure brand rules that apply globally across campaigns or override them per content type.
Watch the video below to see all the options present in Magi's Brand OS:
This is the part most AI content tools skip. They give you a prompt box and call it personalization. Brand OS is the layer that makes the tool actually know how your company sounds before it writes a single word.
Calendar view
The calendar mattered because content teams do not think in isolated prompts. They think in deadlines, campaign timing, and channel mix.
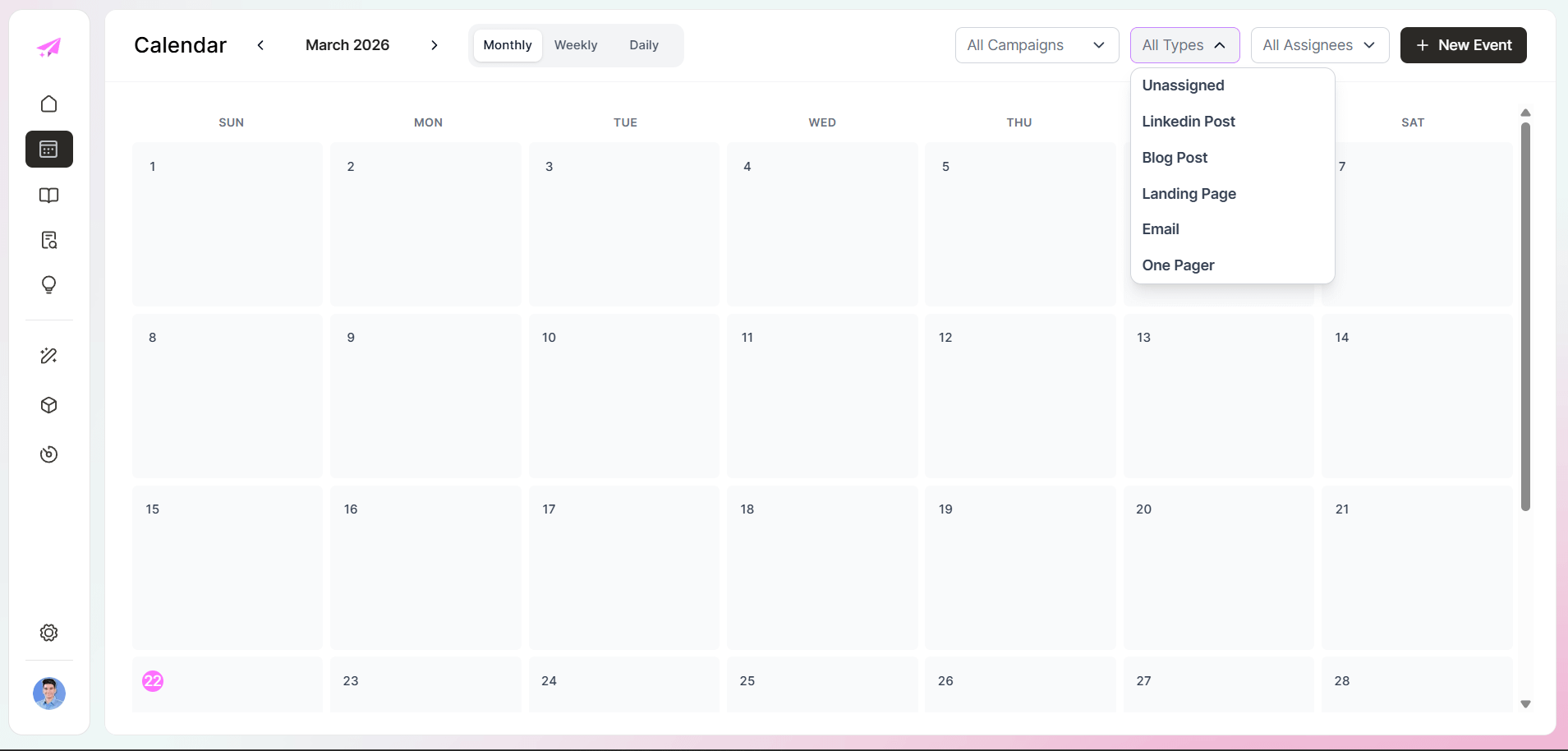
Once you can see blog posts, landing pages, emails, and one pagers in a scheduling interface, the tool stops feeling like an AI toy and starts feeling like a planning surface.
Knowledge base and collections
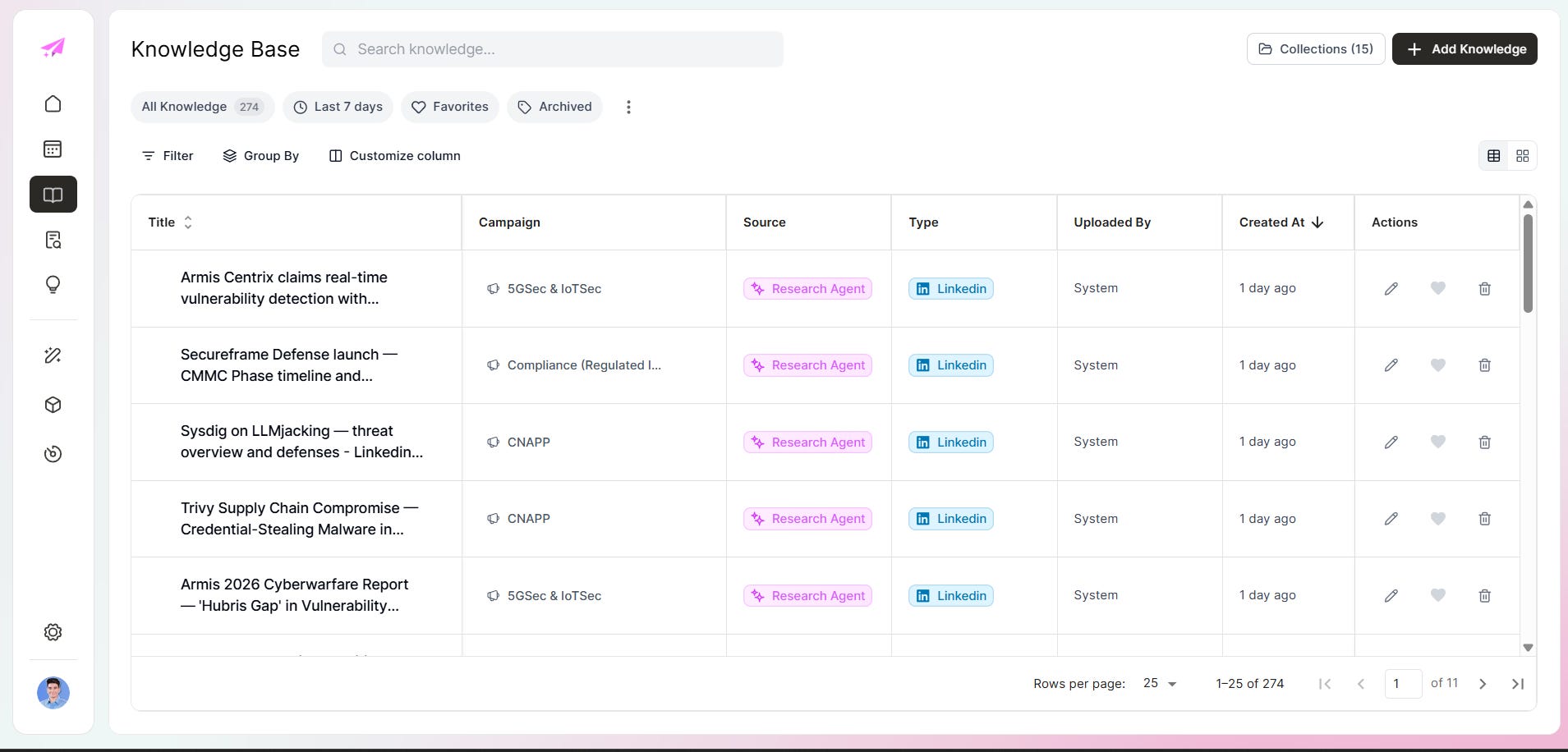
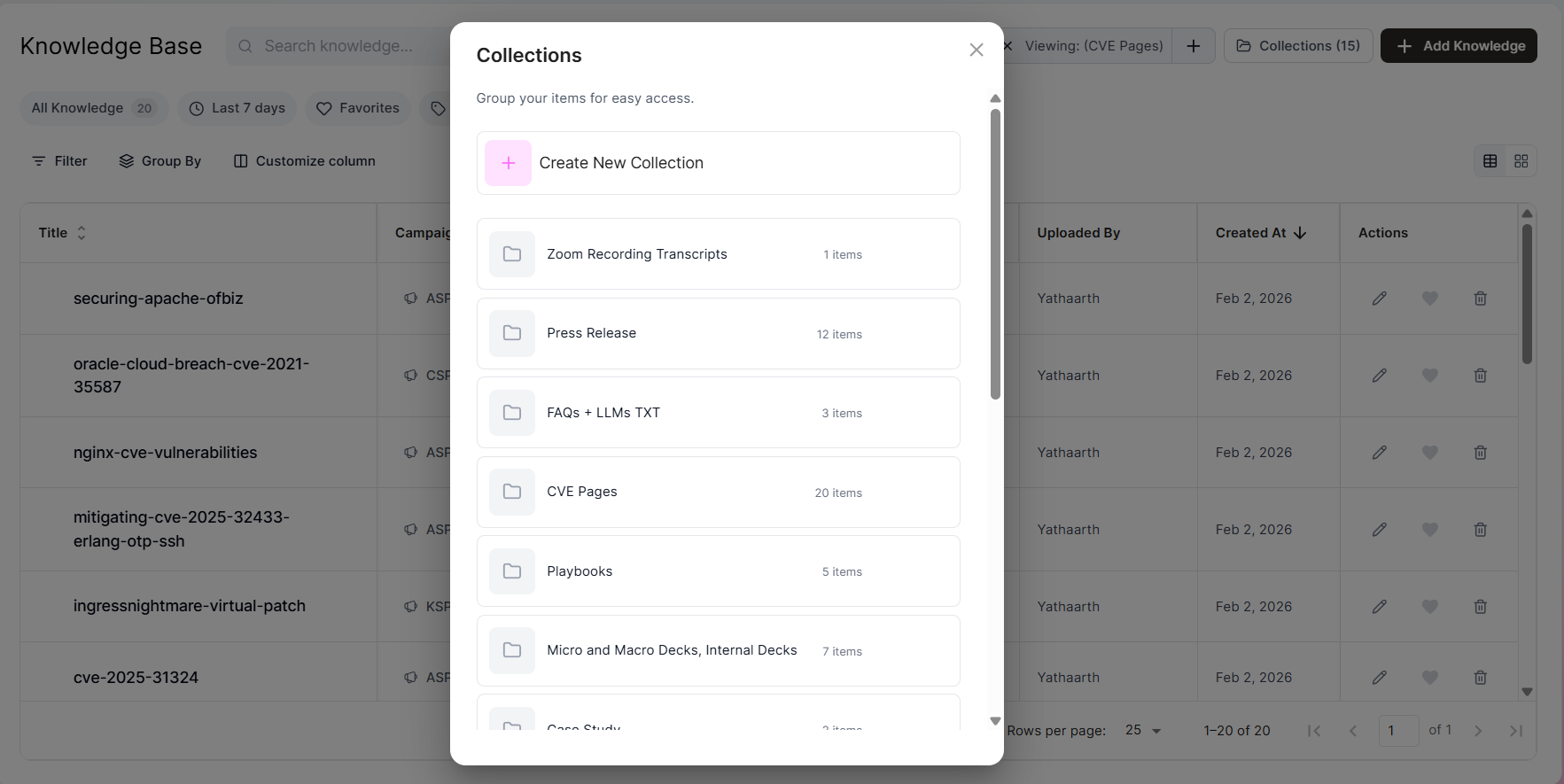
Source assets need somewhere to live that isn't a random shared drive or a Slack thread from six months ago. The knowledge base and collections views handle that. Browseable, sortable, grouped by campaign. When the knowledge layer is invisible, people stop trusting it. When it's organized, they actually use it.
Knowledge to idea generation
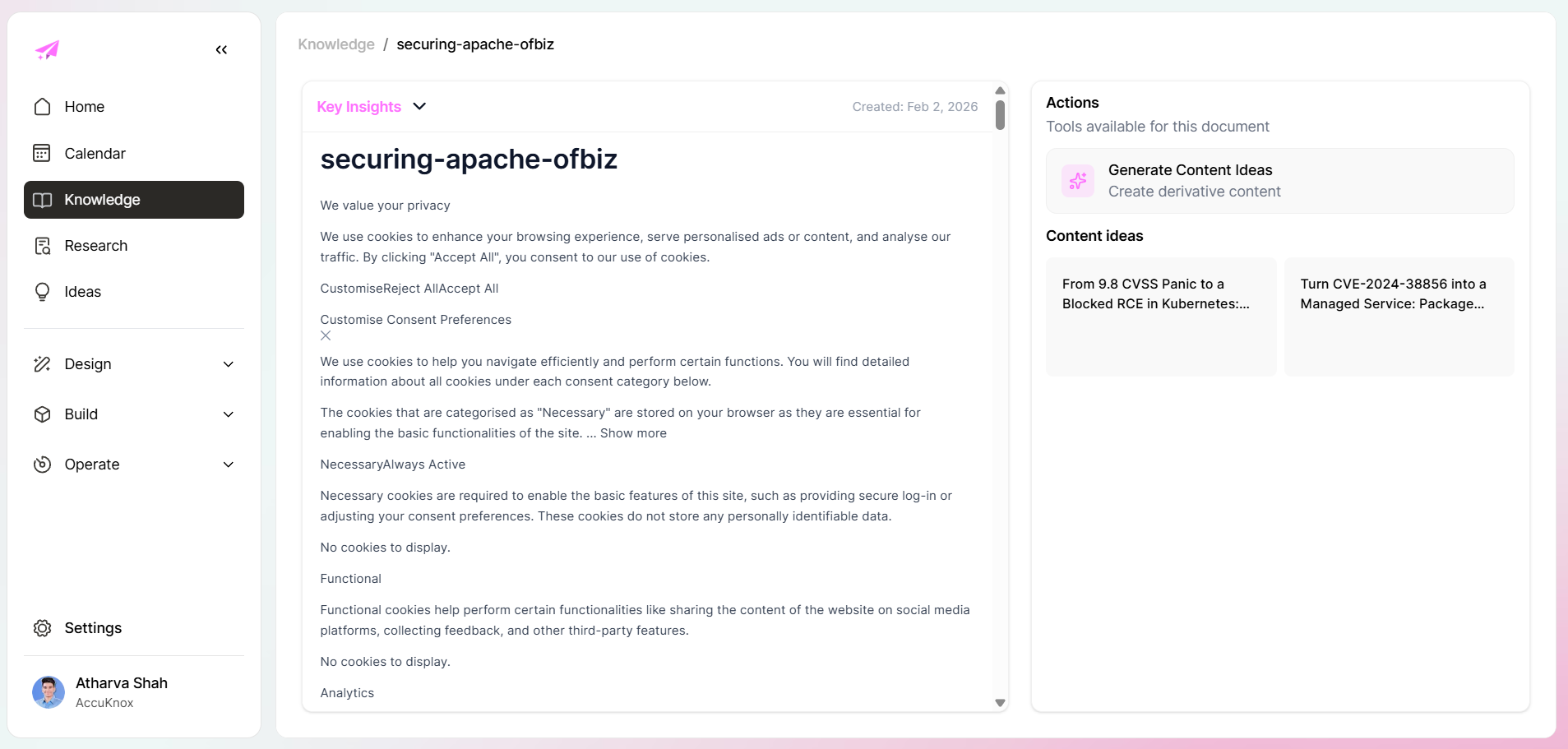
Once a source item can generate content ideas, you stop treating research as dead weight.
That creates a much tighter loop:
collect signal
classify it correctly
map it to a campaign
generate derivative content
That is the actual compounding behavior most teams want from AI content systems.
The ideas view shows this at scale. Each idea is tagged to a campaign, mapped to a knowledge source, typed by content format, and dated:
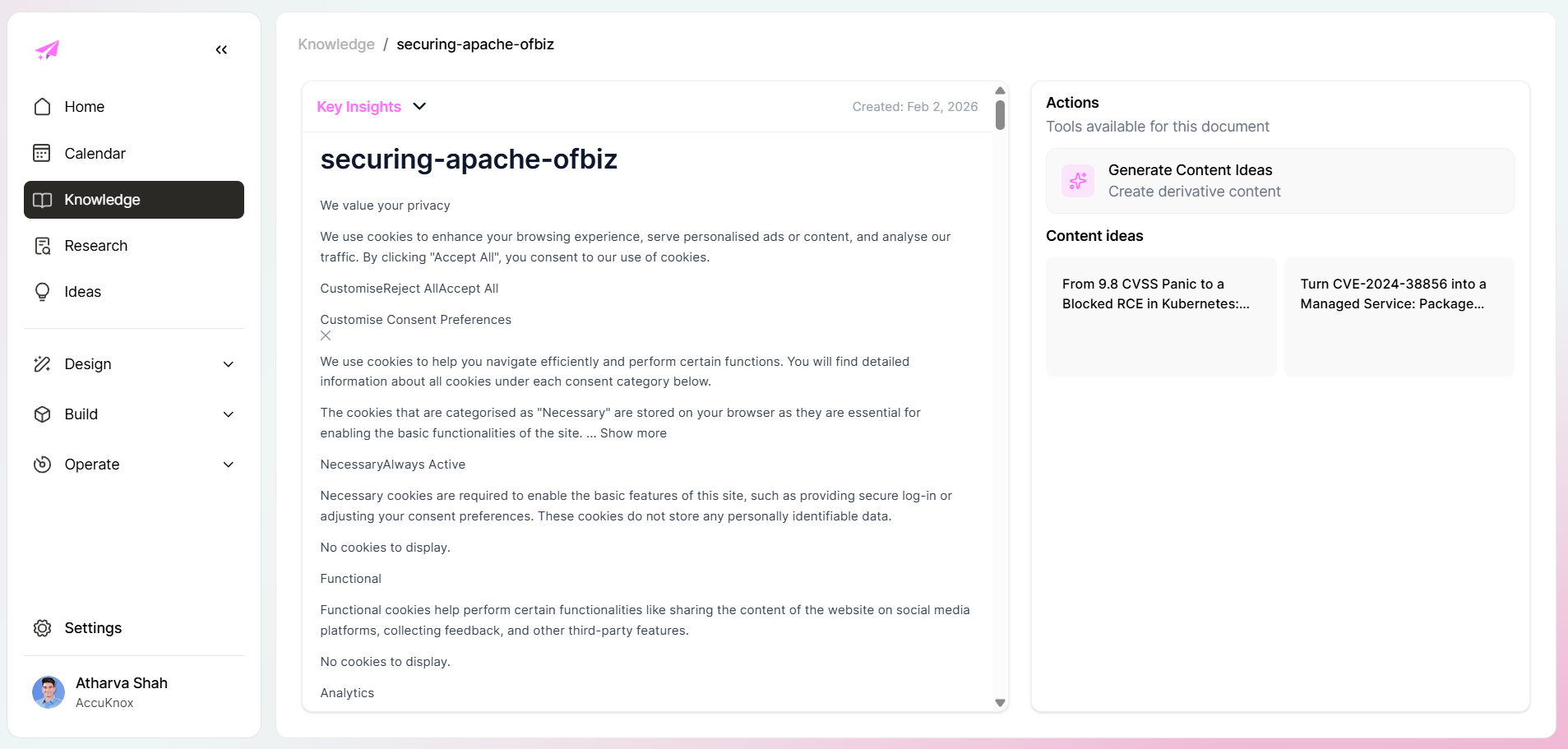

Click into any idea and you get a full brief: a Mini Post TLDR, the sourced excerpt that triggered it, and a draft generation button. The idea is not a blank page. It is already positioned.

The interface that made the tool feel real
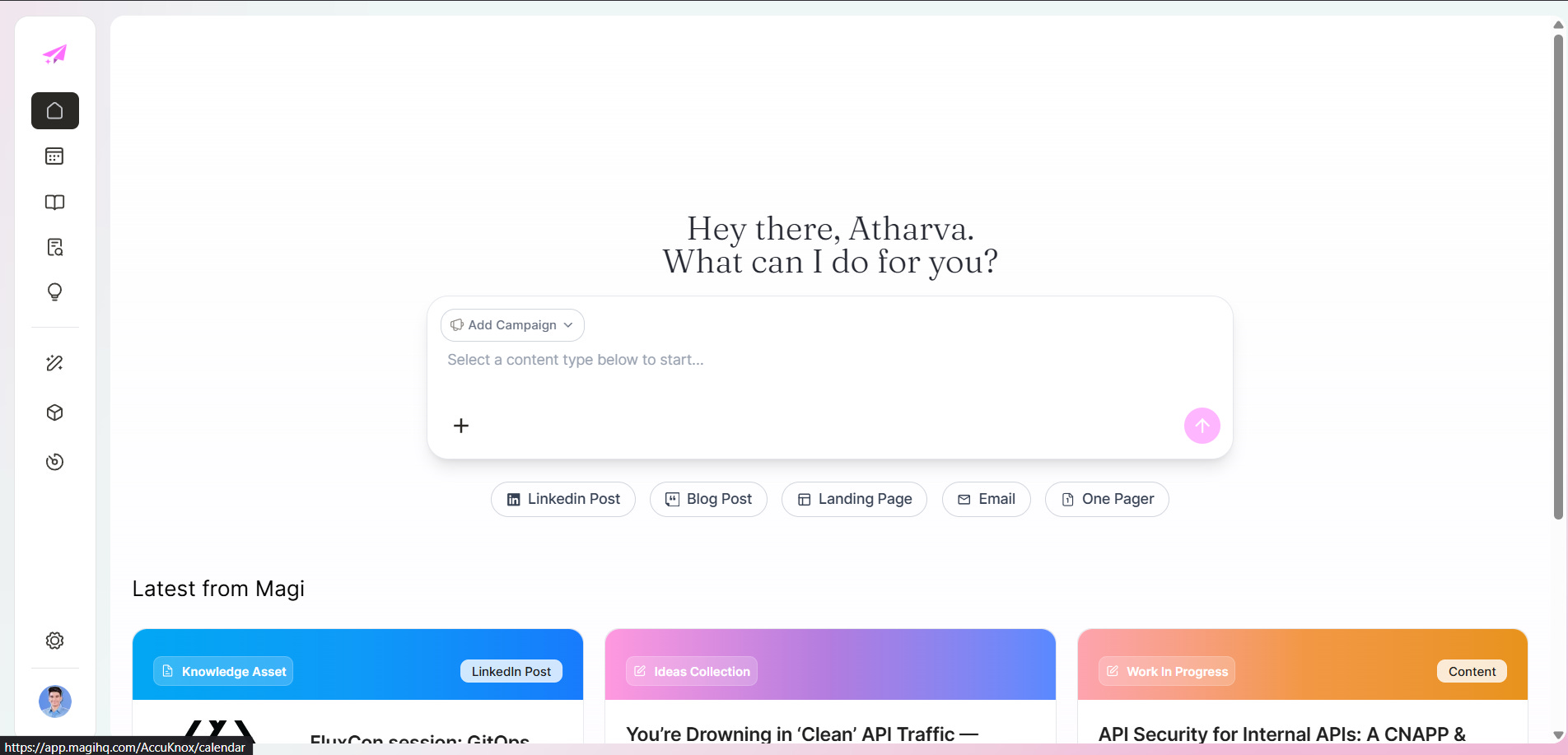
The interface was not just polish. It reflected the operating model underneath: campaign first, content type aware, structured notes feeding generation, visible workflow states, quick access to recent work. That alignment is what makes a tool feel like something a team could actually live in versus something you demo once and forget.
Content in production
With the architecture in place, content becomes a queue problem, not a blank page problem. Here is what 52 pieces looks like: campaign tagged, content type assigned, owner named, status visible.

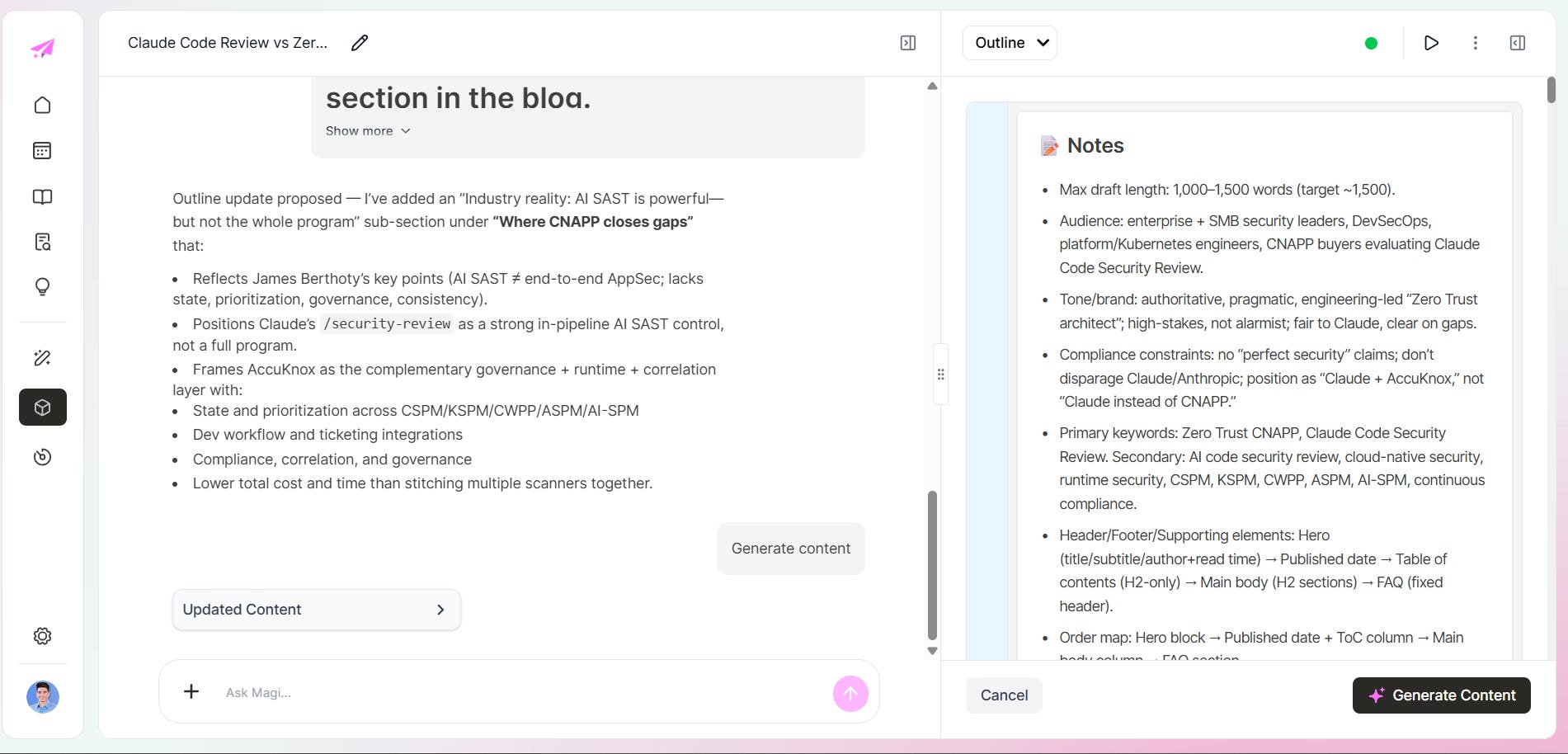
Generation runs from the brief. You set campaign, content type, ideas, and length. The system pulls from the knowledge base, applies brand rules, and produces a draft:

That brief is grounded in a specific knowledge source, a specific campaign, a specific ICP. The output shows it.
What changed once the setup was right
Before the setup, Magi could write. It just wrote like a stranger.
After the setup, the drafts had:
clearer buyer framing
better category specificity
stronger SEO structure
more usable prompts for emails and landing pages
less generic phrasing
a better shot at matching how the team actually talks
That is the difference people miss.
The model was never the bottleneck.
The knowledge architecture was.
And that architecture did not appear by itself. The team had to build it.
What I would tell any team trying this
If you are setting up an AI content system, do these first:
Define the market taxonomy before you generate anything.
Write personas with pain points and KPIs, not vague role labels.
Build competitor and influencer context by category.
Turn your existing source material into collections the system can reuse.
Make frontmatter and publishing rules mandatory.
Use transcripts and internal conversations as primary source material.
Treat workflow UX as part of the system, not an afterthought.

Most teams want a better prompt.
What they need is a better schema.
That was the real Magi setup.
It was less about teaching AI to write and more about manually teaching the system what the business already knows.
Once that clicked, the tool finally had something worth saying.
