

Agentic SQL Review in GitHub Actions: A Production CI Pattern for dbt Pull Requests
Working YAML, blast-radius analysis, anti-pattern detection, and AI suggestions running on every dbt PR. The CI architecture that catches silent wrong joins before they merge.


Code review on dbt projects is hard for reasons that have nothing to do with reviewer skill. A 200-line CTE chain is genuinely difficult to read carefully on the first try. Schema drift between source systems and warehouse tables surfaces in pull requests but requires reviewers to remember every recent upstream change. Silent wrong joins look identical to correct joins in diff view. Destructive operations against shared tables read the same as benign refactors when the lineage is not visible to the reviewer.
The standard mitigation strategies on data teams (dbt tests, peer review, the “two engineer approval” policy) catch a meaningful fraction of these issues but leave a residual rate of bugs that ship to production. The economics of those bugs are asymmetric. A silent wrong join that incorrectly multiplies revenue by 1.04 in a quarterly board deck costs more than years of CI investment.
Agentic SQL review in CI closes most of the residual gap. The pattern runs on every pull request that touches dbt models, executes blast-radius analysis and anti-pattern detection deterministically, layers AI judgment for stylistic concerns, and posts findings as PR review comments alongside the human reviewer’s input. Implementation is one workflow file. Operational cost is small. Risk reduction is large.
This playbook documents the working pattern.
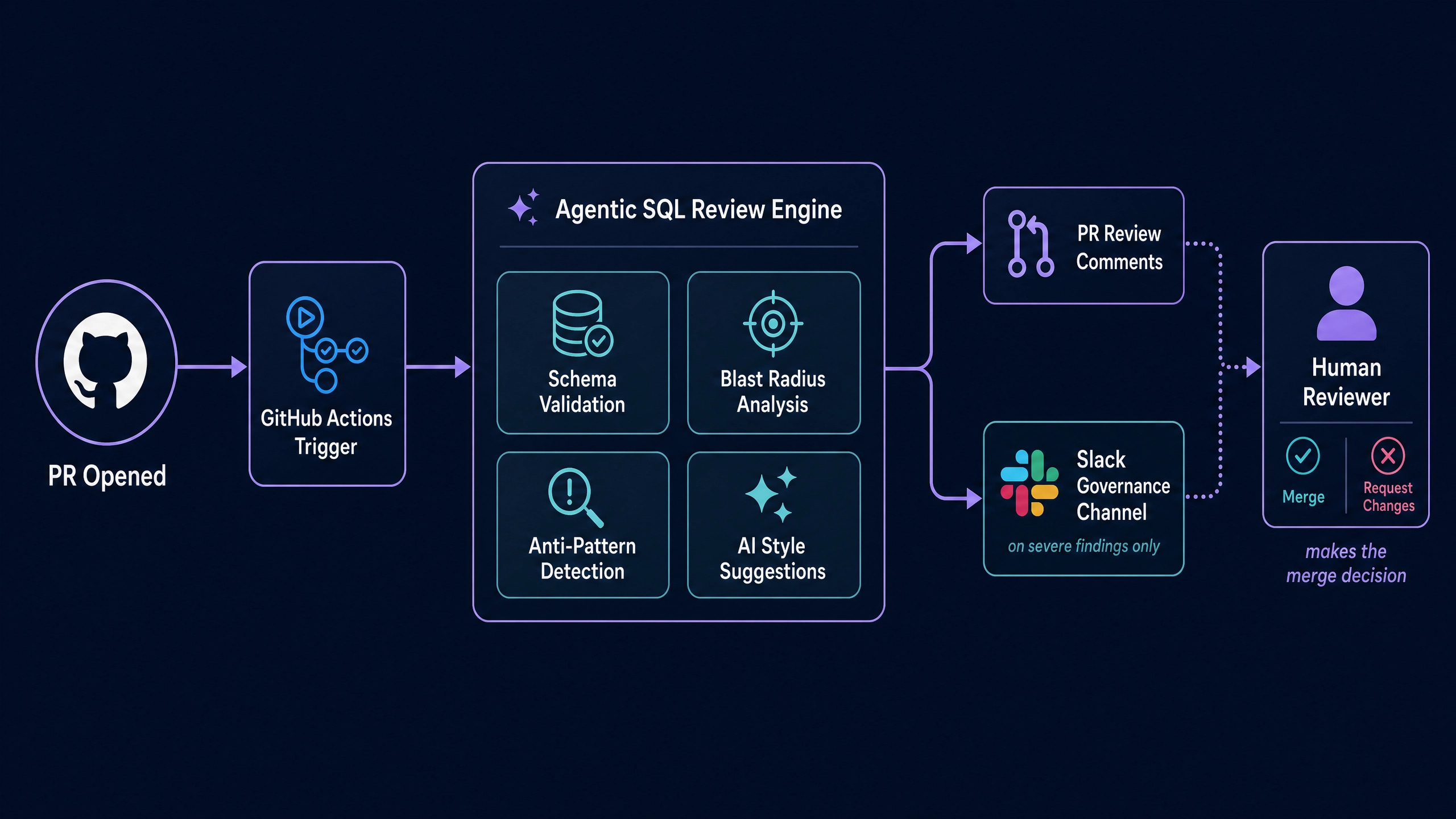
The Mechanics of SQL Review Failure
Three classes of failure account for most production bugs that escape human review.
Schema drift propagation. An upstream column gets renamed in the source system. The PR author updates the staging model that touches the column directly and tests pass. The reviewer approves. Three weeks later a downstream mart fails because the rename was not propagated through the full lineage chain. The reviewer had no way to know during the original PR which downstream models would break, because that information lives in dbt’s lineage graph, which the reviewer was not consulting.
Tribal knowledge about join semantics. Senior engineers know that joining orders.customer_id directly to customers.customer_id produces wrong results because the two columns reference different ID systems (one is an external Stripe ID, the other is an internal numeric ID). That knowledge lives in two senior heads on the team. A reviewer who does not have that context approves the join. The downstream metrics become silently incorrect for weeks until a stakeholder notices an aggregate that does not match expectations.
Bugs invisible in diff view. Silent wrong joins where types match by coincidence after implicit coercion. SELECT * pulling sensitive columns into a non-restricted schema. WHERE clauses missing a partition filter on a large table. Each of these reads as normal SQL when scanning a diff. The bug is in what the SQL does not say.
CI tooling catches all three classes deterministically, which is what makes the agentic review pattern economically attractive. Manual review can match this rigor in principle but does not in practice, because reviewer attention is a finite resource and dbt PRs are frequent.
What “Agentic SQL Review” Means
Agentic SQL review combines two distinct evaluation modes. Deterministic checks (schema validation, lineage analysis, anti-pattern rules, query equivalence) cover everything with a ground-truth answer. AI judgment (naming conventions, modularization suggestions, documentation density, soft style critique) covers everything without a single correct answer.
The separation matters because the two modes have different reliability profiles. Deterministic checks are correct by construction. Their findings should typically fail the build. AI judgment is approximate. Its findings should typically post as suggestions for the human reviewer to weigh. Mixing the two modes (treating AI suggestions as build-failing) creates noisy CI that engineers learn to bypass. Keeping them separate creates signal that engineers learn to trust.
Altimate Code’s CLI surface exposes both modes. The deterministic checks ship as part of the open-source harness. The AI judgment uses whichever LLM provider the team has configured. The CI pattern below uses both with appropriate routing.
The Working CI Workflow
The complete GitHub Actions workflow file follows. Drop it in .github/workflows/dbt-review.yml at the root of the dbt project repository.
name: dbt PR review
on:
pull_request:
paths:
- ‘models/**’
- ‘macros/**’
- ‘tests/**’
- ‘snapshots/**’
- ‘dbt_project.yml’
- ‘packages.yml’
jobs:
altimate-review:
runs-on: ubuntu-latest
permissions:
pull-requests: write
contents: read
steps:
- name: Checkout repository
uses: actions/checkout@v4
with:
fetch-depth: 0
- name: Set up Python
uses: actions/setup-python@v5
with:
python-version: ‘3.11’
- name: Set up Node (for Altimate Code)
uses: actions/setup-node@v4
with:
node-version: ‘20’
- name: Install dbt and Altimate Code
run: |
pip install dbt-snowflake==1.8.0
npm install -g altimate-code
- name: Generate dbt manifest
env:
SNOWFLAKE_ACCOUNT: ${{ secrets.SNOWFLAKE_ACCOUNT }}
SNOWFLAKE_USER: ${{ secrets.SNOWFLAKE_USER }}
SNOWFLAKE_PASSWORD: ${{ secrets.SNOWFLAKE_PASSWORD }}
SNOWFLAKE_ROLE: ${{ secrets.SNOWFLAKE_ROLE }}
SNOWFLAKE_WAREHOUSE: ${{ secrets.SNOWFLAKE_WAREHOUSE }}
run: |
dbt deps
dbt parse --target ci
- name: Run Altimate Code review
id: altimate
env:
ANTHROPIC_API_KEY: ${{ secrets.ANTHROPIC_API_KEY }}
run: |
altimate-code review \
--pr ${{ github.event.pull_request.number }} \
--base ${{ github.event.pull_request.base.sha }} \
--head ${{ github.event.pull_request.head.sha }} \
--modes deterministic,advisory \
--output review-output.json
- name: Post review comments to PR
if: always()
env:
GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}
run: |
python .github/scripts/post-review.py review-output.json
- name: Alert Slack on severe findings
if: steps.altimate.outputs.severity == ‘high’
env:
SLACK_WEBHOOK: ${{ secrets.SLACK_DATA_GOVERNANCE_WEBHOOK }}
run: |
curl -X POST -H ‘Content-type: application/json’ \
--data “{\”text\”:\”Severe finding on PR #${{ github.event.pull_request.number }}: ${{ steps.altimate.outputs.summary }}\”}” \
“$SLACK_WEBHOOK”
- name: Fail build on severe findings
if: steps.altimate.outputs.severity == ‘high’
run: |
echo “Severe finding gates this PR. Review the comments before merging.”
exit 1The companion post-review.py script reads the JSON output and posts comments via the GitHub REST API. A minimal implementation runs roughly 40 lines including error handling. The exact code is straightforward but project-specific (different teams want different comment formatting, different severity thresholds, different mentions).
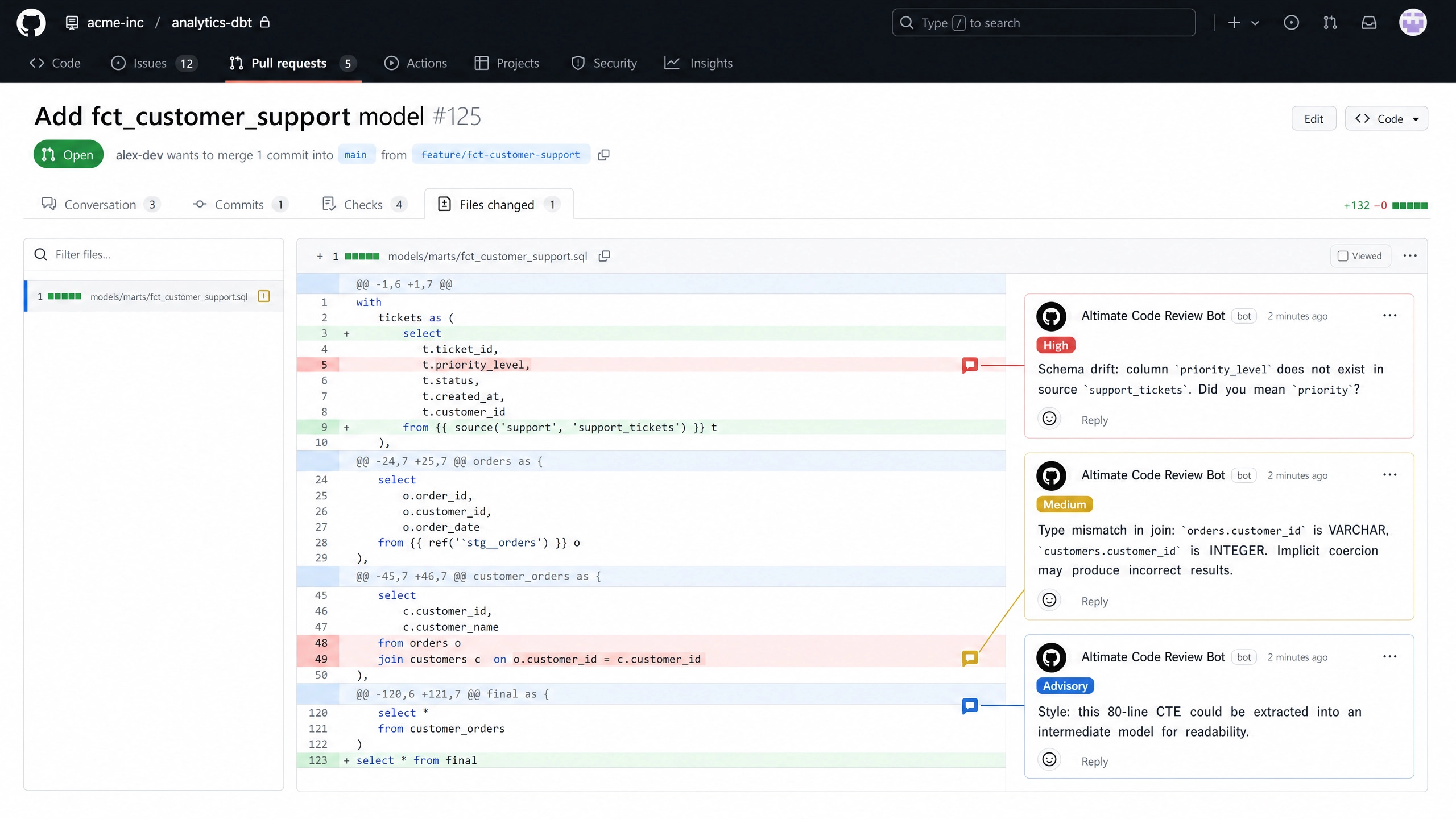
The Five Categories of Finding the Pattern Surfaces
A correctly-configured agentic review pipeline produces findings in five categories. Each maps to a distinct failure mode and a distinct response pattern from the human reviewer.
Schema drift findings. Deterministic check. The PR modifies a model that references a column no longer present in the source table. The comment names the column, the file, the line number, and the suspected upstream rename. Response: the PR author updates the model to the new column name or, if the source has actually broken, raises the upstream team.
Anti-pattern findings. Deterministic check. SELECT * against a wide table, missing predicates on partitioned columns, implied cartesian joins from missing join conditions, large recursive CTEs without termination guards. Each finding includes the file path, line range, and a one-line explanation. Response: the PR author either fixes the pattern or annotates an exception for cases where the anti-pattern is intentional.
Downstream impact findings. Deterministic check based on lineage. The PR changes a column or model in a way that affects N downstream models. The comment enumerates them, with severity scaled by the breadth of impact. Response: the PR author confirms the impact is intentional or splits the PR to make the downstream changes explicit.
Type-mismatch join findings. Deterministic check based on schema. The PR introduces a join between columns with different types where implicit coercion will silently apply. The comment surfaces the join, the column types on each side, and the recommended explicit cast. Response: the PR author adds the explicit cast or confirms the join is correct because of a known semantic equivalence.
Style and modularity findings. Advisory mode using the LLM. Long models that could be decomposed, naming conventions that drift from project standards, documentation density below threshold. Response: the human reviewer weighs the suggestion alongside their own judgment. These findings do not fail the build.
The severity routing is important. Schema drift, anti-pattern findings, downstream impact above a configurable threshold, and type-mismatch joins typically gate the build. Style and modularity findings post as suggestions and are non-blocking.
Cost and Latency Profile
Operational costs of running this pattern in CI are modest.
Average run time on a small PR (one to three changed models) is approximately 30 seconds. The dominant cost is dbt parse time, which is constant for the project size. Average run time on a large PR (10 or more changed models on a 500-model project) is two to three minutes, again dominated by parse time.
Token cost depends on the LLM provider and the size of the diff under review. Using Claude Sonnet for advisory-mode review, expected cost per PR lands well under one US dollar. For a team running 50 PRs per week, monthly LLM cost lands in the $50 to $100 range. This is materially cheaper than one hour of senior engineer review time.
The workflow only triggers on PRs that touch models/, macros/, tests/, snapshots/, dbt_project.yml, or packages.yml. PRs that modify documentation, configuration files, or non-dbt code skip the action entirely. This paths filter is the single most important optimization for CI cost containment.
For teams with strict CI cost budgets, the deterministic checks can be enabled without the advisory LLM mode. This removes the per-PR LLM cost entirely while preserving the highest-value findings (schema drift, anti-patterns, downstream impact, type mismatches).
Adapting to Other CI Platforms
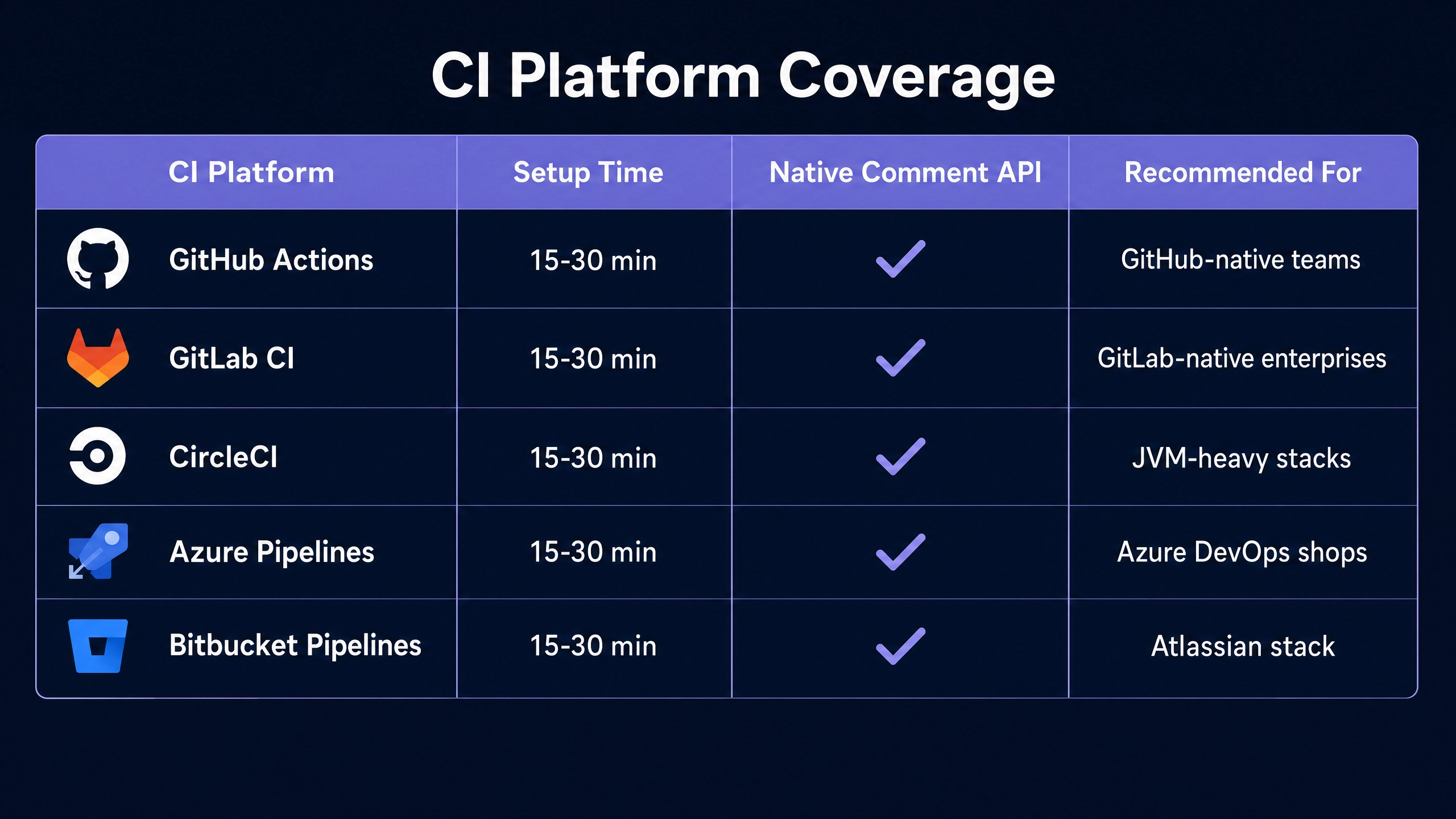
The architecture is portable across CI platforms. The same logical pattern works on GitLab CI, CircleCI, Azure Pipelines, Bitbucket Pipelines, and self-hosted runners.
The platform-specific surface is small: the YAML syntax for triggering on pull request events, the secret-injection mechanism for warehouse and LLM credentials, the API for posting comments back to the merge request. Altimate Code’s CLI accepts identical arguments across platforms. Porting the workflow from GitHub Actions to GitLab CI typically takes 15 to 30 minutes of engineering time.
For teams running self-hosted CI, the only additional consideration is network access from the runner to the warehouse and to the LLM provider. Most teams either run the CI in the same VPC as the warehouse (for low-latency parse) or use a dedicated CI service account with warehouse access.
The Slack Governance Pattern
For findings the action grades as severe (proposed DROP TABLE, schema-breaking changes without a contract update, PII columns being exposed to non-restricted schemas), the standard pattern is to post to a dedicated Slack channel in addition to the PR.
The Slack hook integrates cleanly into the workflow above. The implementation is a single curl invocation in the workflow file, conditionally executed on the severity output from the review step.
The governance impact is meaningful. Data governance leads, security teams, and compliance officers gain real-time visibility into operations that previously surfaced only at quarterly audit time. The signal-to-noise ratio depends on how aggressively the severity thresholds are configured. Teams typically iterate on this for the first few weeks before settling on a stable threshold.
Extensions Worth Building
Three extensions to the base pattern repay the engineering investment quickly.
Post-merge regression check. After a PR merges, the workflow can run a HashDiff between the new model’s output and the old model’s output (using time travel on the warehouse). Any unexpected row-count delta or hash mismatch posts a Slack alert and optionally opens a follow-up issue. This catches the residual cases where the PR-time review found nothing wrong but the merge has nonetheless produced a regression.
Auto-generated PR descriptions. The LLM can read the diff and produce a first draft of the PR description focusing on what changed, what downstream might break, and what tests were added. The PR author edits before submission. This consistently improves PR description quality across teams that adopt it.
Test generator on demand. A PR comment like /altimate generate-tests can trigger the action to write missing dbt tests for the changed models. The bot commits the new tests to the PR branch in a separate commit. This is particularly useful for legacy projects where test coverage is low.
Each extension is roughly 50 to 100 lines of additional YAML and Python. None require restructuring the base workflow.
Strategic Implications for Data Engineering Teams
The agentic review pattern is more than a tactical CI improvement. It represents a structural shift in how data teams allocate engineering review time. Schema validation, lineage analysis, and anti-pattern detection are now deterministic operations that should run on every PR. Human review attention should focus on business logic correctness, semantic equivalence, and the soft style judgments that require organizational context.
For organizations evaluating the pattern, the right adoption sequence is incremental. Start with the deterministic checks only. Enable advisory mode after the team is comfortable with the false-positive rate of the deterministic findings. Layer in Slack alerting once the severity thresholds are calibrated. Add the post-merge regression check after the basic workflow is stable.
Engineering teams that adopt this pattern in 2026 will catch a meaningful fraction of the production data bugs that currently slip through code review. The investment is one workflow file, three secrets, and a handful of API tokens. The return is measurable risk reduction on dbt deployments at scale.
The cost of running agentic SQL review on every PR is cheap. The cost of a silent wrong join making it to production is not.